WordPress nasce con una scelta di default chiara: indicizza quasi tutto. Ogni post, ogni categoria, ogni tag, ogni archivio autore, ogni pagina data, ogni pagina di ricerca interna è una URL pubblica e — salvo configurazioni esplicite — Googlebot la troverà e la inserirà in indice. Per un sito piccolo non è un problema. Per un blog di centinaia di post, un magazine multitopic o un e-commerce WooCommerce, è il modo più veloce per riempire l’indice di pagine senza valore di ricerca e diluire la qualità percepita del dominio.
Questa guida copre tutti i tipi di URL che WordPress genera in autonomia (archivi tassonomia, archivi automatici, pagine sistema, custom post type, WooCommerce) e dice in modo operativo dove applicare noindex, dove invece serve un canonical, dove un blocco in robots.txt, dove un 410 Gone. In fondo, gli errori più comuni e come verificarli da Search Console.
TL;DR — cosa indicizzare su WordPress
| Tipo URL | Default consigliato | Motivo |
|---|---|---|
| Post / pagine | INDEX | Contenuto principale |
| Categorie | INDEX (con intro testuale) | Hub di silos tematici |
| Tag | NOINDEX di default | Quasi sempre thin / duplicati di categoria |
| Archivi autore | NOINDEX su single-author INDEX su multi-author | Profilo autore con bio = pagina utile |
| Archivi data (anno/mese/giorno) | NOINDEX | Liste duplicate, nessun intent di ricerca |
Pagine di ricerca interna /?s= | NOINDEX | Genera URL infinite di scarso valore |
| Pagine media (attachment) | NOINDEX o redirect al post | Default WP recenti: redirect |
Paginazioni /page/2/ | INDEX, no canonical alla 1 | Vedi guida paginazioni |
| Feed, REST API, xmlrpc | Disallow + X-Robots-Tag | Risorse tecniche non HTML |
| WooCommerce: cart/checkout/account | NOINDEX | Pagine transazionali personali |
| WooCommerce: product, /shop/, product-category | INDEX | Sono la vetrina commerciale |
| WooCommerce: product-tag, attribute filter | NOINDEX o canonical | Spesso duplicato / faceted thin |
Sono i default. Le sezioni successive spiegano quando deviare e perché.
Le basi: cos’è noindex e cosa non è
noindex è una direttiva (non un suggerimento) che dice ai motori di ricerca: “ho letto questa pagina, non includerla nei risultati”. La trovi come meta tag robots nell’<head> HTML, oppure come header HTTP X-Robots-Tag (l’unica via per file non-HTML come PDF, immagini, JSON).
Esempio classico in HTML:
<meta name="robots" content="noindex,follow">Equivalente via header HTTP (per esempio in .htaccess o functions.php):
X-Robots-Tag: noindex, followCosa fa, esattamente
- Al primo crawl dopo aver visto la direttiva, Google rimuove la URL dall’indice.
- Nel tempo, riduce la frequenza di crawl su quella URL (la considera meno prioritaria).
- Dopo molti mesi di
noindexpersistente, Google tratta i link in uscita come se fosseronofollow(effetto pratico: link equity bloccata).
Cosa non è noindex (le confusioni più costose)
- Non è
Disallowin robots.txt:robots.txtblocca il crawl, non l’indicizzazione. Una URL bloccata in robots.txt può comunque comparire in SERP con titolo “tratto” dai backlink. - Non è rel=canonical: il canonical consolida segnali su una URL preferita, non rimuove URL dall’indice. Le URL canonicalizzate restano scansionabili.
- Non è 404/410:
noindexmantiene la URL viva (con HTTP 200) ma fuori indice. Se la URL non esiste più, usa410 Gone. Se è stata sostituita, usa un redirect 301.
Il singolo errore più frequente è il quarto: combinare noindex con Disallow sulla stessa URL. Il crawler bloccato in robots.txt non legge mai il meta noindex perché non scarica la pagina. La URL resta in indice. Approfondiamo in noindex vs robots.txt vs canonical.
Il framework decisionale
Prima di toccare un plugin SEO conviene avere un criterio. Una URL WordPress merita di stare in indice se risponde a tre domande in cascata:
- Valore unico — chi atterra dalla SERP trova qualcosa che non vede già altrove sul sito?
- Non duplicato interno — esiste un’altra URL del dominio che copre lo stesso intent meglio o uguale?
- Valore di ranking concreto — riceve query reali in Search Console o ha link in entrata?
L’albero qui sotto mette in ordine queste domande e mappa ogni esito (INDEX, NOINDEX, CANONICAL, REDIRECT/410):

Notare la regola implicita: in dubbio, parti da noindex,follow. È reversibile in qualsiasi momento e — a differenza di Disallow — non rompe segnali. Dopo 30-60 giorni controlli in GSC: se quella URL stava ricevendo impression utili, riportala in indice. Se no, l’esclusione era corretta.
Archivi di tassonomia: categorie, tag, custom
Categorie
Le categorie sono i silos del blog: la struttura gerarchica con cui un lettore (e Google) inquadra di cosa parli. Salvo casi rari, le categorie principali vanno indicizzate. Tre condizioni perché diano valore reale in SERP:
- Hanno un testo di introduzione unico (almeno 150-300 parole) che spiega il tema della categoria, non solo il titolo.
- Mostrano excerpt degli articoli, non il post completo (altrimenti duplichi 1:1 con i singoli post).
- Non si sovrappongono tra loro: due categorie con post in comune al 50% sono un segnale di silo male disegnato.
Categorie figlie (sotto-categorie): vanno indicizzate solo se hanno volume di articoli (almeno 5-10) e un loro testo introduttivo. Altrimenti meglio noindex e link interno verso la parent.
Tag
I tag sono la trappola più frequente. Di norma noindex, per tre motivi: (1) sono spesso usati come keyword-stuffing (“seo”, “wordpress”, “google” applicati a metà del blog) e generano archivi quasi identici fra loro; (2) si sovrappongono con le categorie senza aggiungere valore; (3) generano thin content quando contengono pochi post.
Le eccezioni in cui far indicizzare i tag esistono e sono ristrette:
- Magazine multitopic dove i tag rappresentano entità nominate (es. “Inter”, “Real Madrid”) con archivi ricchi (centinaia di pezzi) e intent di ricerca verificato in SERP.
- Tag con introduzione testuale curata e selezione editoriale, non auto-generati.
Limite pratico: massimo 3-5 tag per articolo, mai un tag con meno di 5-10 post.
Tassonomie custom
Quando un tema o un plugin (es. WooCommerce, plugin di gallerie, plugin recensioni) registra custom taxonomy, ogni termine genera una URL pubblica. Le regole sono le stesse: indicizzare se il termine ha volume di contenuti + testo introduttivo + intent di ricerca, altrimenti noindex.
Errore tipico: lasciare in indice le tassonomie dei plugin “per default” senza averle mai guardate. Da site:tuosito.it/taxonomy-slug/ verifichi rapidamente cosa è successo.
Matrice per tipo di sito
| Tipo sito | Categorie | Tag | Tassonomie custom |
|---|---|---|---|
| Blog tematico stretto | INDEX | NOINDEX | Caso per caso |
| Magazine multitopic | INDEX | INDEX selettivo (entità nominate) | INDEX se editoriale |
| E-commerce WooCommerce | INDEX (product-cat) | NOINDEX (product-tag) | NOINDEX (attributi) |
| Portfolio / vetrina | INDEX se ha intro | NOINDEX | NOINDEX |
Archivi automatici WordPress
WordPress genera in autonomia, senza che tu debba fare nulla, una serie di archivi che quasi nessun sito ha bisogno di indicizzare. Sono attivi by default e — su un blog di anni di pubblicazione — moltiplicano l’inventario di URL senza valore di ricerca.
Archivi autore (/author/<slug>/)
Single-author (blog con un solo autore): l’archivio autore duplica quasi 1:1 la home o l’archivio principale. Vai di noindex. Multi-author (magazine, portali con redazione): l’archivio autore può diventare una pagina utile se ha biografia, foto, expertise dichiarata (E-E-A-T) e link ai social. In quel caso INDEX.
Soluzione pulita per multi-author: usare un plugin author profile (es. Co-Authors Plus, Molongui) che arricchisce la pagina autore. Senza arricchimento, noindex anche su multi-author.
Archivi data (/2026/, /2026/05/, /2026/05/14/)
Sempre noindex. Tre URL generate per ogni post (anno, mese, giorno), tutte duplicati parziali di categoria e home, e nessun utente cerca articoli per “marzo 2024” su Google. Su un blog di 1000 post, gli archivi data possono valere 3000+ URL indicizzabili di zero valore. Plugin SEO le mettono in noindex con un toggle.
Pagine di ricerca interna (/?s=)
Sempre noindex, e in più Disallow con cautela. La pagina /?s=parola è generata dinamicamente da qualunque visitatore o bot: se Google trova un link a una di queste URL (capita), inizia a esplorare uno spazio di URL infinito. Il noindex via meta robots è gestito dai plugin SEO. In più, Disallow: /?s= in robots.txt risparmia crawl budget.
Attenzione all’effetto combinato: noindex + Disallow sulla stessa pattern è un’eccezione che funziona perché parlano di crawl e indice insieme — ma se la URL era già in indice prima del Disallow, lo resta. Prima noindex e attendi de-indicizzazione, poi Disallow.
Pagine media (attachment)
Ogni immagine caricata su WordPress genera una pagina dedicata (/?attachment_id=123 o /slug-immagine/) con solo l’immagine e nessun contenuto testuale. È il caso più puro di thin content. I plugin SEO moderni (Yoast, Rank Math) hanno per default l’opzione “redirect attachment URL al post genitore”: scelta consigliata. In alternativa, noindex.
Se hai pubblicato per anni senza redirect, controlla in GSC Indicizzazione pagine quante attachment URL sono in indice. Spesso il numero supera il numero dei post.
Paginazioni (/page/2/, /page/3/)
Le pagine 2-N degli archivi vanno indicizzate, niente canonical alla pagina 1: contengono link verso post diversi e servono al crawler per scoprire profondità. Il dettaglio (link, autoreferenza canonical, e perché il vecchio rel=prev/next non serve più) è in Paginazioni e archivi: linee guida SEO.
Pagine sistema e tecniche
Sono le URL che WordPress espone per ragioni funzionali, non editoriali. Non vanno indicizzate, ma la modalità di esclusione cambia in base al fatto che siano HTML o no.
Feed RSS (/feed/, /comments/feed/, /category/…/feed/)
I feed sono XML, non HTML: il meta noindex non si applica. L’unica strada è l’header HTTP X-Robots-Tag: noindex. WordPress di default non lo invia. Si aggiunge in functions.php:
add_action('template_redirect', function() {
if (is_feed()) {
header('X-Robots-Tag: noindex, follow', true);
}
});In alternativa, alcuni plugin SEO (Rank Math) hanno l’opzione “noindex feeds” integrata.
REST API (/wp-json/)
La REST API espone i contenuti del sito come JSON. Non è HTML, restituisce Content-Type: application/json. Google ha smesso di indicizzare risposte JSON da anni, ma su siti grandi compaiono comunque negli sniffer log. Se vuoi escludere il path:
# robots.txt
User-agent: *
Disallow: /wp-json/Attenzione: non bloccare /wp-json/ se hai integrazioni headless, app, plugin che dipendono dalla REST API esposta pubblicamente.
xmlrpc.php, trackback, wp-admin, wp-login
Sono endpoint funzionali, mai contenuto. Disallow in robots.txt:
User-agent: *
Disallow: /xmlrpc.php
Disallow: /wp-admin/
Disallow: /wp-login.php
Disallow: /trackback/Eccezione famosa: /wp-admin/admin-ajax.php serve a molti plugin per AJAX frontend. WordPress di default emette un Allow: /wp-admin/admin-ajax.php dentro un blocco Disallow: /wp-admin/. Se sovrascrivi robots.txt a mano, riproduci l’eccezione:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.phpPDF, immagini, altri file non-HTML
Su PDF, DOCX, ZIP e simili il meta noindex non esiste. Si usa l’header HTTP via Apache (.htaccess):
<FilesMatch "\.pdf$">
Header set X-Robots-Tag "noindex, follow"
</FilesMatch>Approfondimenti su come Googlebot scarica e processa risorse: Crawl budget e Analisi log server con tail.
Custom Post Types e WooCommerce
Custom Post Types generici
Un tema o un plugin può registrare tipi di contenuto personalizzati (libri, eventi, ricette, case study, video, recensioni…). Le regole sono identiche ai post: il singolo CPT va indicizzato se contiene contenuto unico, l’archivio CPT va indicizzato se ha intro testuale e volume.
Verifica obbligatoria su qualsiasi CPT installato da plugin di terze parti: spesso registrano CPT pubblici senza dirtelo. Esempio: plugin di recensioni (WP-Recipe-Maker, plugin di gallerie, plugin di knowledge base) creano CPT con archivi attivi che diventano centinaia di URL.
WooCommerce: regole specifiche
WooCommerce introduce un’intera famiglia di URL con logica diversa da un blog. Le decisioni di default:
| URL / template | Default | Note |
|---|---|---|
/shop/ (archivio prodotti) | INDEX | È la home commerciale, prima vetrina |
/product/<slug>/ (prodotto singolo) | INDEX | Mai noindex su prodotti attivi. Per prodotti OOS: linee guida dedicate |
/product-category/... | INDEX | Come categorie blog: serve testo introduttivo unico |
/product-tag/... | NOINDEX | Quasi sempre duplicato di product-category o thin |
/cart/ | NOINDEX | Personale e dinamico |
/checkout/ | NOINDEX | Step transazionale |
/my-account/ e sotto-path | NOINDEX | Area utente |
/checkout/order-received/<id>/ | NOINDEX (X-Robots-Tag) | Pagina thank-you, server-side header |
| Wishlist, Compare (YITH, TI WooC) | NOINDEX | Stato di sessione utente |
Filtri faceted ?filter_color=... | NOINDEX o canonical | Vedi sotto: strategia faceted |
Sorting ?orderby=price | Canonical alla URL pulita | Stesso contenuto, ordine diverso |
Paginazione /shop/page/2/ | INDEX | Come paginazioni blog |
/lost-password/, password recovery | NOINDEX | Utility |
Faceted search: la decisione più delicata
I filtri attributo di WooCommerce (colore, taglia, marca, prezzo) generano combinazioni esponenziali di URL: 4 colori × 5 taglie × 3 brand = 60 URL solo sul singolo product-category. Su un catalogo grande diventano migliaia. Tre strategie possibili:
- Tutte noindex con canonical alla URL non filtrata. Default sicuro. Si perde la possibilità di intercettare query long-tail (“scarpe rosse taglia 42”), ma si tutela il crawl.
- Whitelist selettiva: si indicizzano solo combinazioni singole di valore (es. solo “colore=rosso”) e si noindexano le combinazioni multiple. Richiede plugin SEO con regex/condizionale (Rank Math Pro, SEOPress Pro).
- URL pulite: usare plugin che convertono i filtri in URL statiche (es.
/scarpe/rosse/) trattate come sub-categorie. Setup complesso, ma il più potente per SEO faceted. Vedi parametri URL.
Per l’80% dei WooCommerce, l’opzione 1 è la scelta giusta. L’opzione 2 e 3 valgono solo se hai un team SEO che misura l’incremental click.
Come applicarlo concretamente
Nel 2026 nessuno modifica più header.php a mano per gestire noindex (era pratica del 2012, oggi semplicemente inutile). Tutto passa dai plugin SEO o da snippet in functions.php.
Yoast SEO
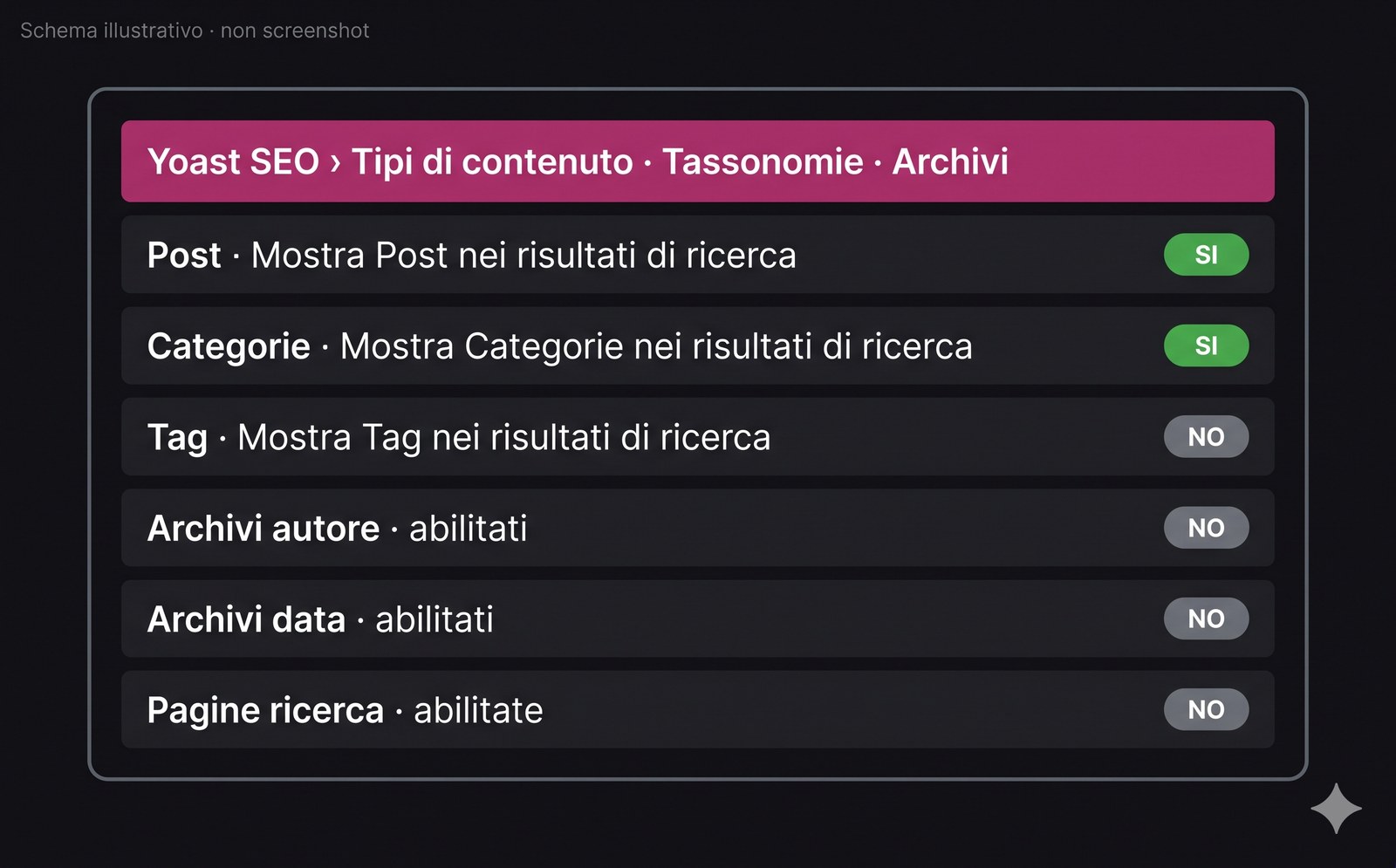
Path UI: Yoast SEO > Tipi di contenuto (per post, pagine, CPT) e Yoast SEO > Tassonomie (per categorie, tag, custom taxonomy). Per ogni tipo c’è il toggle “Mostra X nei risultati di ricerca”: NO = noindex. Per gli archivi automatici (autore, data, ricerca) il path è Yoast SEO > Archivi.
Rank Math
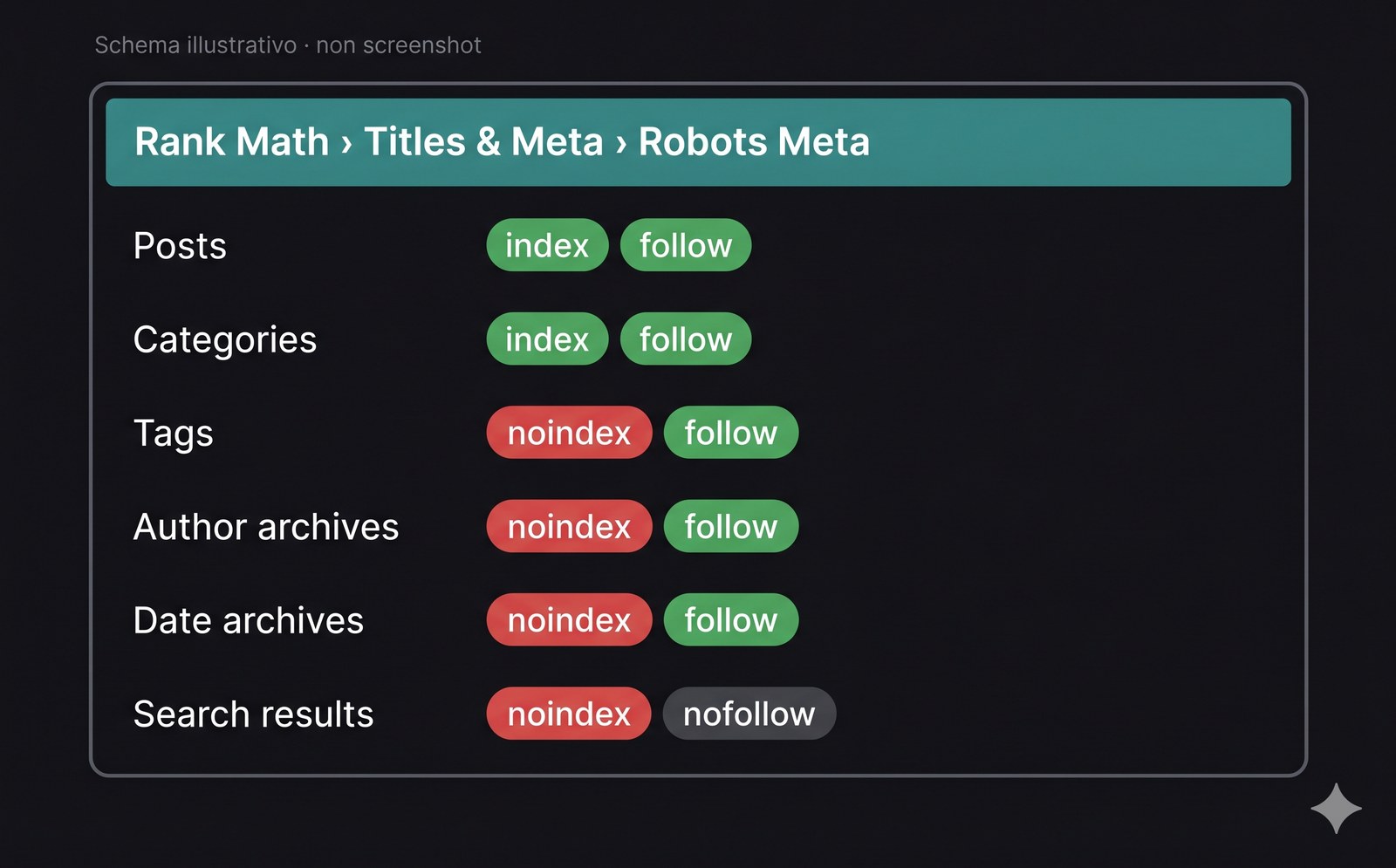
Path UI: Rank Math > Titles & Meta. Per ogni tipo (Posts, Pages, Categories, Tags, CPT, Author, Date, Search) c’è una sezione Robots Meta con checkbox: Index / No Index, Follow / No Follow, più No Archive, No Image Index, No Snippet. La granularità è superiore a Yoast.
SEOPress
Path UI: SEO > Titoli & Metas > Archivi e SEO > Titoli & Metas > Tipi di post. Logica simile a Rank Math con checkbox dedicati per index/noindex per ogni tipo. Plugin meno diffuso ma valido.
All in One SEO (AIOSEO)
Path UI: All in One SEO > Search Appearance > Content Types e > Taxonomies e > Archives. Toggle “Show in Search Results”: disattivo = noindex.
Senza plugin: snippet in functions.php
Se non vuoi installare un plugin SEO o vuoi un controllo fine non gestito dal plugin, lo snippet moderno è questo (da inserire in functions.php del tema child, non del tema principale):
add_action('wp_head', function() {
if (is_tag() || is_date() || is_author() || is_search() || is_attachment()) {
echo '<meta name="robots" content="noindex,follow">' . "\n";
}
}, 1);Per controllo a livello di header HTTP (utile per feed, file non-HTML, REST API):
add_action('template_redirect', function() {
if (is_feed() || is_search()) {
header('X-Robots-Tag: noindex, follow', true);
}
});Per categorie specifiche da escludere (caso reale: una categoria contenitore di articoli a basso valore che vuoi de-indicizzare per intero):
add_action('wp_head', function() {
// ID categorie da rendere noindex
$cats_to_noindex = [42, 87];
if (is_single() && in_category($cats_to_noindex)) {
echo '<meta name="robots" content="noindex,follow">' . "\n";
}
}, 1);Tutti questi snippet sono compatibili con WordPress moderno e convivono con i plugin SEO senza conflitti — se il plugin emette già un noindex, il browser/crawler vedrà la prima occorrenza valida.
noindex vs robots.txt vs canonical: la matrice
Tre strumenti diversi, tre layer di stack diversi, tre effetti diversi. Confonderli è la causa della maggior parte dei problemi di indicizzazione su WordPress.
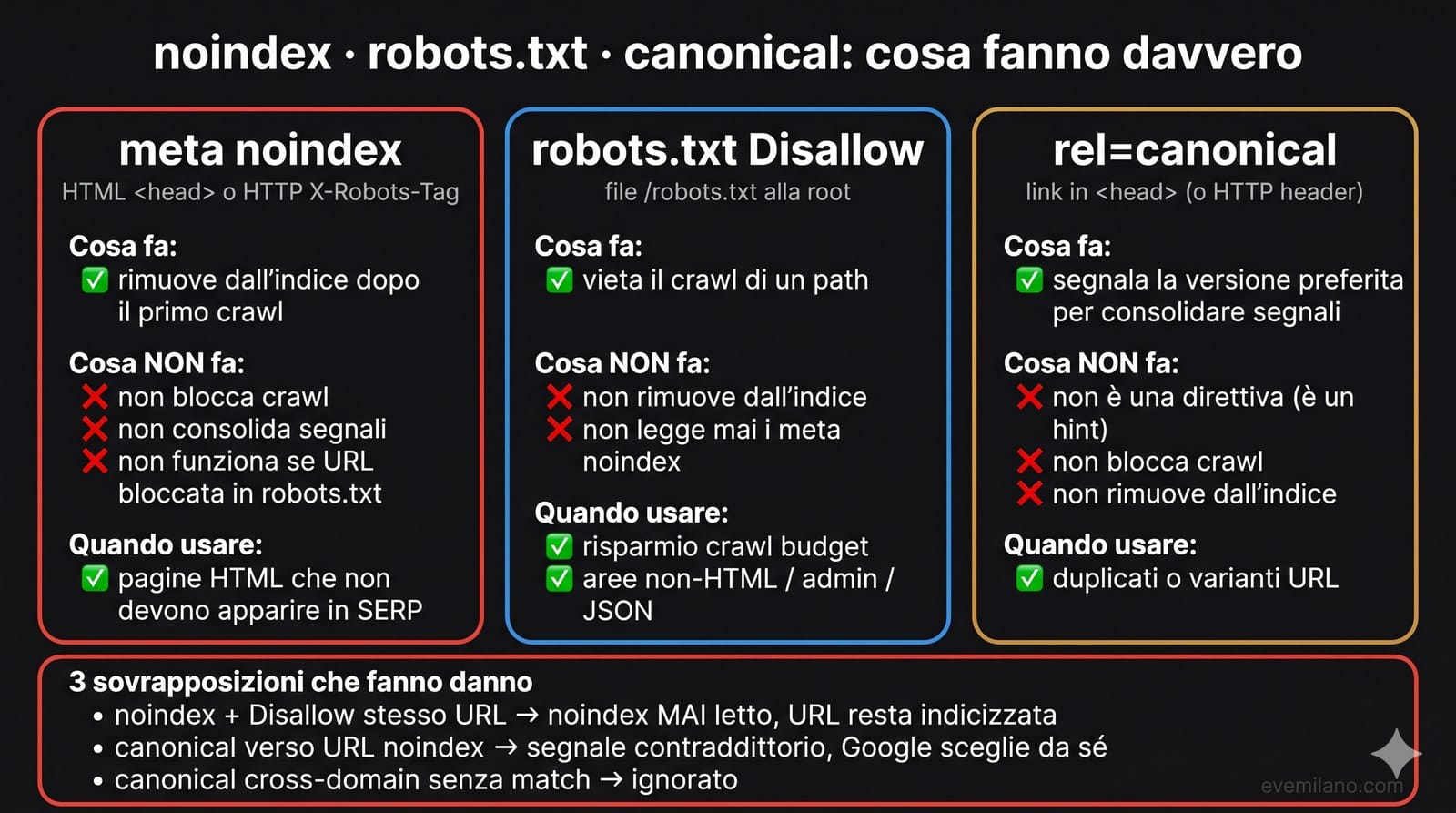
| meta noindex | robots.txt Disallow | rel=canonical | |
|---|---|---|---|
| Layer | HTML head / HTTP header | File /robots.txt root | HTML head / HTTP header |
| Blocca crawl? | No | Sì | No |
| Rimuove dall’indice? | Sì (dopo primo crawl) | No (URL può restare) | No (consolida) |
| Tipo | Direttiva | Direttiva | Suggerimento |
| Funziona per non-HTML? | Solo via X-Robots-Tag | Sì | Solo via HTTP header |
| Risparmia crawl budget? | No (al primo crawl) | Sì | Minimo |
L’errore che vedo più spesso
Voglio nascondere una pagina da Google → metto noindex nel plugin SEO → la pagina resta in indice → “il noindex non funziona” → vado a controllare il robots.txt e vedo Disallow: /quella-pagina/. Il crawler bloccato in robots.txt non scarica la pagina e quindi non legge mai il meta noindex. La URL resta nell’indice (magari con titolo tratto dai backlink) finché non rimuovi il Disallow.
La sequenza corretta per de-indicizzare una URL è: (1) rimuovi qualsiasi Disallow su quella URL in robots.txt, (2) applica noindex, (3) aspetta che Google la riscansioni e la rimuova (giorni o settimane), (4) opzionalmente, dopo la rimozione, ri-applichi Disallow per risparmiare crawl futuro.
Verifica e monitoraggio
Aver impostato noindex non garantisce che Google l’abbia visto, processato, e che la URL sia uscita dall’indice. Quattro strumenti, dal più rapido al più dettagliato.
1. Search Console — Indicizzazione delle pagine
Da Google Search Console > Indicizzazione > Pagine: vedi quante pagine sono indicizzate, quante escluse, e per quale motivo. Le etichette che ti interessano per il debug noindex:
- “Esclusa in base al tag ‘noindex'”: il noindex sta funzionando, quelle URL sono fuori indice.
- “Indicizzata, ma bloccata da robots.txt”: il classico errore di sovrapposizione. URL in indice nonostante il Disallow.
- “Pagina di reindirizzamento”: la URL è gestita da redirect, non da noindex.
- “Alternativa con tag canonical adeguato”: la URL è canonicalizzata altrove, non è un problema.
2. Search Console — Ispezione URL
Per controllare una singola URL, incollala nella barra “Controllo URL” in alto in GSC. Il risultato dice:
- Se è in indice o no.
- Quando Google l’ha vista l’ultima volta.
- Quale
canonicalha dichiarato e quale ha scelto Google (possono differire). - Eventuale
X-Robots-Tagricevuto.
Cliccando “Visualizza pagina scansionata” puoi vedere l’HTML esatto che Googlebot ha letto, incluso il meta robots renderizzato. Utile quando il plugin SEO dice “noindex attivo” ma il rendering finale produce qualcosa di diverso (cache, conflitto di plugin, header già emesso).
3. Operatore site: come check rapido
Ricerca su Google: site:tuosito.it/tag/ oppure site:tuosito.it/?s= oppure site:tuosito.it/author/. Se i risultati sono numerosi, hai pagine in indice che non dovrebbero esserci. È approssimativo (Google a volte non mostra tutto), ma è il check di 10 secondi che fa scoprire i problemi.
4. Screaming Frog (o crawler simile)
Per audit completi, Screaming Frog SEO Spider scansiona il sito come Googlebot e ti elenca tutti i meta robots e gli header X-Robots-Tag ricevuti. Configurazione utile: Configuration > Robots.txt > Settings > Ignore Robots.txt per vedere anche cosa c’è dietro Disallow. Esporta la colonna “Indexability” + “Indexability Status” per la dashboard.
Per controllo lato server in tempo reale (vedere cosa Googlebot effettivamente scarica), vedi Analisi log server con tail.
Errori comuni
Otto pattern che riconosco al volo nei progetti che ricevo per consulenza.
- Noindex sull’intero sito in produzione (dimenticato dopo una migrazione). Impostazioni > Lettura > “Scoraggia i motori di ricerca dall’indicizzare il sito” attivo. Effetto: meta
noindex,nofollowsull’intero dominio. Se il sito è online da settimane, è un disastro. Controllo del primo giorno post-migrazione obbligatorio. - Noindex + Disallow stessa URL. Il crawler bloccato non legge il noindex. URL resta in indice indefinitamente. Sequenza corretta sopra in la matrice.
- Noindex su URL canonical-izzata da un’altra. Pagina A canonical → B, ma A è noindex. Google riceve segnali contraddittori (la canonical dice “consolidale”, il noindex dice “rimuovila”). Risultato: imprevedibile. Se metti noindex, rimuovi anche il canonical-target.
- Noindex sulle paginazioni di archivio. Errore di chi pensa che “page/2/, page/3/ siano duplicati”: non lo sono, contengono link a post diversi. Mettendole in noindex perdi profondità di crawl. Vedi guida paginazioni.
- Noindex sulle categorie principali. Errore frequente di chi “ha letto da qualche parte che le categorie sono duplicati”. Sono i tuoi silos, sono pagine hub, vanno indicizzate (con intro testuale). Mettendole noindex auto-saboti la struttura SEO del blog.
- Disallow di
/wp-admin/senzaAllow: /wp-admin/admin-ajax.php. Rompe plugin AJAX (form Contact Form 7, WooCommerce mini-cart, ecc.) per i bot che eseguono JS. WordPress di default gestisce l’eccezione; se sovrascrivirobots.txt, replicala. - Affidarsi a
noindex,followper i link equity. Sul breve terminefollowconta, sul lungo Google tratta una URL in noindex persistente comenoindex,nofollowdi fatto. Non costruire SEO sulla speranza che noindex,follow passi PageRank per sempre. - Meta noindex su PDF, immagini, file non-HTML. Non funziona — quei file non hanno un
<head>. ServeX-Robots-Tagvia header HTTP.
FAQ
Noindex passa link equity (PageRank) agli altri link nella pagina?
Sul breve termine sì, se usi noindex,follow. Sul lungo termine (mesi/anni), Google ha dichiarato che tratta una pagina costantemente in noindex come noindex,nofollow di fatto: il crawl si riduce, la link equity si attenua. Se vuoi che una pagina passi link equity in modo affidabile, mantienila index.
Quanto tempo ci mette Google a rispettare un noindex?
Da poche ore (URL importanti, crawl frequente) a settimane (URL su path poco crawlato). Per accelerare: in Search Console > Ispezione URL richiedi un nuovo crawl della singola URL. Per blocchi di URL puoi forzare un re-crawl via XML sitemap aggiornata o via Remove URLs tool di Search Console per rimozione temporanea (6 mesi).
Yoast vs Rank Math per gestione noindex: differenze pratiche?
Yoast è più semplice (toggle ON/OFF per tipo) e adatto a non-tecnici. Rank Math offre granularità maggiore (index/follow/archive/snippet/imageindex separati) e regole condizionali nella versione Pro. Per la stragrande maggioranza dei siti, Yoast è sufficiente. Per WooCommerce complessi o magazine con regole noindex articolate, Rank Math vince. Non c’è differenza tecnica nel risultato finale (entrambi emettono lo stesso meta tag).
Posso usare noindex su una pagina che riceve molti backlink?
Tecnicamente sì, ma è uno spreco. Una pagina con molti backlink ha PageRank che vorresti distribuire. Tre opzioni migliori del puro noindex: (a) riscrivere la pagina per renderla degna dell’indice; (b) 301-redirect verso la pagina più rilevante (consolida link equity); (c) canonical verso un’altra pagina (consolida segnali, mantiene la URL accessibile).
Il noindex è reversibile?
Sì, sempre. Rimuovi il meta tag, aspetta il prossimo crawl, la URL torna in indice. Tempo medio: pochi giorni per URL crawlate spesso, fino a settimane per URL poco viste. Puoi accelerare con Ispezione URL > “Richiedi indicizzazione”.
Posso usare noindex per nascondere contenuti riservati?
No. Noindex impedisce che la URL appaia in SERP, ma la URL resta pubblicamente accessibile a chiunque la conosca. Per contenuti riservati: HTTP Basic Auth, login obbligatorio, IP whitelist, o spostare i file fuori dal webroot. Non confondere “non indicizzato” con “privato”.
Conclusione
La gestione index/noindex su WordPress non è un dettaglio tecnico: è uno dei più forti segnali di qualità che dai a Google sul tuo dominio. Più sei selettivo nel decidere cosa appare in SERP, più alta è la qualità media dell’indice, più il dominio guadagna fiducia.
I default per un blog WordPress sano:
- INDEX: post, pagine, categorie principali, paginazioni archivio.
- NOINDEX: tag, archivi autore (se single-author), archivi data, ricerca interna, attachment pages.
- Disallow:
/wp-admin/(con Allow su admin-ajax),/xmlrpc.php,/?s=(dopo aver de-indicizzato), feed (con X-Robots-Tag).
I default per WooCommerce:
- INDEX:
/shop/, prodotti, product-category, paginazione. - NOINDEX: product-tag, cart, checkout, my-account, order-received, filtri faceted, wishlist/compare.
Tre azioni concrete per chiudere
- Fai un
site:tuosito.itsu Google e scorri 5-10 pagine di risultati. Ogni URL che ti sorprende è candidata a noindex. - Crea una tabella decisionale interna del tuo sito (tipo URL → stato voluto → strumento) e mettila come fonte di verità nel piano editoriale. Aggiornala quando installi un nuovo plugin che registra CPT o tassonomie.
- Controlla in Search Console > Indicizzazione > Pagine ogni trimestre. Cerca trend strani: se “Esclusa in base al tag noindex” cresce molto da un mese all’altro, qualcuno ha cambiato configurazione.
Per approfondire i temi adiacenti: crawl budget, parametri URL, canonical, paginazioni, come calcolare l’indicizzazione di un sito, cosa impedisce l’indicizzazione.
Articoli correlati
Autore

Mi chiamo Giovanni Sacheli e dal 2009 aiuto le aziende a farsi trovare online. Sono specializzato in SEO tecnica e PPC, competenze che applico quotidianamente nella mia agenzia, Searcus Swiss Sagl. Mi piace sviluppare strumenti a supporto del mio lavoro, ho creato SEOdata.app e cluster.army e co-scritto il libro SEO Audit Avanzato. Curo maniacalmente questo blog per colleghi e appassionati, dove mi "appunto" quello che imparo. Sono un NERD anni '80, motociclista e orgoglioso papà di due bambini.
Link:
Giovanni Sacheli
SEO Audit Avanzato
Searcus Swiss Sagl
SEOdata.app
cluster.army
Commenti |10
Lascia un commentoCiao Giovanni, avevo il dubbio se tenere noindex tag o categorie, grazie per avermi fatto capire. In effetti meglio evitare duplicazioni e giocare solo con le categorie. Grazie!
Ciao Margherita grazie del commento. Consiglio sempre di non fare indicizzare le tag, poi però dipende sempre da caso per caso. In un blog classico preferisco sempre puntare sulle pagine di categoria.
A presto!
Buongiorno Giovanni,
“Se nelle categorie e tag archive usate gli excerpt**, allora non è necessario usare noindex, anzi non usarlo sarebbe meglio.”
Perché meglio non usarlo se usa gli excerpt?
Grazie
Ciao Barbara, grazie del commento. Era un articolo molto vecchio e mi hai dato l’input per aggiornarlo. In particolare ho rimosso quella frase e rivisito le linee guida. Grazie!
Grazie a te per l’aggiornamento!
Complimenti per l’articolo, molto utile.
Ho un problema con sito che mi trovo a gestire. Nell’ultimo anno il blog è stato gestito in modo molto “allegro”, per gli articoli sono state create 6 categorie e ben 280 tag, molti dei quali messi a casaccio (tipo stesso tag singolare e plurale) o in modo massivo come se fossero hashtag di fb o instagram. Ovviamente sono state create altrettante pagine archivio.
Devo fare pulizia.
Conviene cancellare tutti i tag e fare dei 301?
Troppi 301 poi non incidono comunque su crawl budget?
E’ un gran casino, vorrei fare un lavoro con metodo ma senza peggiorare la situazione.
Da dove consigli di iniziare?
Ciao Ben grazie del commento. La tua situazione è abbastanza comune.
Io ti consiglio di partire valutando se le tag servono o no.
Se decidi di togliere tutte le tag usa i 301, non sono un problema. Assicurati di far sparire dal sito tutti i link che puntavano alle tag e tag cloud varie. Ad esempio, in questo blog ho deciso di toglierle, le uso solo nel back-end per far funzionare alcuni plugin custom, ma in front-end non appaiono mai.
Se invece decidi di tenerle definisci bene quali tenere, ti consiglio di mappare i tuoi argomenti in modo che siano ben studiate e mai sovrapposte. Tutte quelle che togli redirezionale 301 verso cat o tag simili.
Non preoccuparti, è un lavoro semplice :) A presto!
Grazie per l’articolo. Temo però di non aver capito bene come utilizzare la stringa che hai postato.
Ho un sito su cui ho installato Rank Math. Devo creare una nuova categoria i cui articoli all’interno non voglio che vengano indicizzati (si tratta di circolari che purtroppo sono copiate da altri siti, che le hanno copiate da altri siti e via dicendo, quindi devo inserirle per forza ma non voglio che creino problemi).
Ora, quello che non ho capito di questa stringa è
<?php if (is_single() && in_category(array(###))) { echo '’; } ?>
1) dove metto il nome della categoria? Al posto di “category” nel pezzo “in_category”? O al posto dei tre cancelletti?
2) dici di metterlo nell’header del tema. Posso quindi inserirla in qualunque punto del file header.php del tema?
Grazie
Ciao Vanessa, grazie per il commento.
La stringa che hai menzionato nella tua domanda aggiunge il tag “noindex” solo alla pagina di categoria e non agli articoli contenuti in essa. Se desideri che gli articoli all’interno della categoria siano contrassegnati come “noindex”, dovrai utilizzare il seguente codice:
function my_noindex_category_posts( $robots ) {
if ( is_single() && in_category( array( 123 ) ) ) {
$robots['index'] = 'noindex';
$robots['follow'] = 'nofollow';
}
return $robots;
}
add_filter( 'wp_robots', 'my_noindex_category_posts' );
Nel codice sopra, sostituisci il numero 123 con l’ID della categoria per la quale vuoi rendere gli articoli “noindex”. Questo codice farà sì che gli articoli appartenenti alla categoria specificata abbiano il tag “noindex, nofollow”.
Puoi inserire lo script nel file “header.php” del tuo tema, oppure crea un file “functions.php” per un plugin personalizzato, se preferisci mantenere le modifiche separate dal tema. Per aggiungerlo al file “functions.php”, apri il file e inserisci il codice sopra riportato alla fine del file, prima della chiusura ?> (se presente).
Spero che queste informazioni ti siano state utili e abbiano chiarito i tuoi dubbi. Se hai altre domande, non esitare a chiedere!
Grazie mille!