Ti sei mai chiesto come faccia Google a decidere l’ordine dei risultati di una ricerca? Ogni giorno su Google vengono eseguite milioni di ricerche e i risultati appaiono sempre in poche frazioni di secondo. Prima che tu riesca a vedere i risultati ordinati nella pagina di ricerca, nei server e data center di Google avvengono moltissime attività in lassi di tempo infinitesimali. Il processo con cui Google scansiona ed indicizza tutte le risorse presenti sul web è molto complesso e cercherò di spiegarlo nel modo più semplice possibile.
Crawling e indexing
Il primo passo per un motore di ricerca è fare crawling (scaricare) ed indicizzare tutti i documenti presenti nel web. Questo lavoro è svolto da Googlebot, lo spider di Google, che si connette ai web server sparsi nel pianeta per scaricare i documenti/pagine web.
I compiti del crawler sono gestiti dallo scheduler. Erroneamente si pensa che il crawler salti da un link all’altro navigando per le pagine web, in realtà il crawler interroga i web server per farsi dare specifiche pagine che gli vengono indicate dallo scheduler. Questi documenti vengono letti per estrapolarne i link che a loro volta vengono inviati allo scheduler che pianificherà le visite successive del crawler… e così via il ciclo si ripete. Lo scheduler quindi pianifica quali documenti il crawler deve scaricare. Ogni singolo documento scaricato viene identificato con un ID univoco ed è visualizzabile richiedendo a Google la versione cache (cache:www.esempio.com/pagina.html).
Il crawler produce tantissimi documenti, questi dati tuttavia non possono essere ancora ricercati. Senza un indice, se tu vuoi fare una ricerca per il termine “mondiali motociclismo”, i data center di Google dovrebbero leggersi tutti i documenti ogni volta che viene eseguita una ricerca e questo non è un processo efficace.
Indicizzazione e Indice invertito
Il prossimo passo quindi è creare un indice, per fare questo Google inserisce i dati di crawling in un indice invertito. Invece di dover leggere tutti i documenti per ogni query eseguita, questi vengono inseriti in un database formato da un Dizionario e i dati di posting. Ad ogni parola vengono associati gli ID dei documenti che la contengono e l’elenco degli ID è detto posting.
Le tecniche di indicizzazione studiate per le basi di dati relazionali non sono adatte per i sistemi di Information Retrieval. L’indice più utilizzato è l’indice invertito:
- Viene memorizzato l’elenco dei termini contenuti nei documenti
della collezione; - Per ogni termine, viene mantenuta una lista dei documenti nei quali tale termine compare.
Ad esempio la parola “motociclismo” potrebbe essere presente nei documenti 1, 5 e 9, mentre la parola “mondiali” potrebbe essere nei documenti 2, 5, e 11. L’indicizzazione avviene attraverso passi successivi
- Scansione dei documenti e creazione di un elenco di coppie (termine, Document ID)
- Ordinamento dell’elenco per termine
- I termini che compaiono più volte nello stesso documento collassano in un unico elemento, al quale viene aggiunta la frequenza del termine
- Il risultato viene memorizzato in due file: il file del Dizionario e il file dei Posting
Una volta costruito l’indice è il momento di ordinare i risultati e valutare la loro rilevanza rispetto alla ricerca effettuata. Supponiamo che un utente cerchi su Google la frase campionato motociclismo. Al fine di presentare e ordinare i risultati, Google ha bisogno di due cose:
- trovare il set di pagine che contiene la ricerca dell’utente
- ordinare i risultati in base alla rilevanza
Google ha trovato un modo furbo per gestire questa enorme mole di dati: invece di salvare tutto l’indice in un unico super-computer, vengono utilizzati centinaia di computer assieme e l’indice è suddiviso in piccole porzioni ciascuno. Dato che il lavoro è suddiviso tra tanti computer, la risposta può essere trovata molto più velocemente.
Immaginiamo che l’indice di una enciclopedia sia lungo 30 pagine. Se una persona dovesse cercare da sola diverse informazioni nell’indice impiegherebbe almeno qualche secondo per ogni ricerca. Ma cosa cambierebbe se si potesse assegnare una singola pagina a 30 persone? Potrebbero cercare la loro porzione di indice molto più velocemente di una sola persona che deve leggere 30 pagine da sola.
Come fa Google a trovare le pagine che contengono la ricerca dell’utente?
Torniamo all’esempio del campionato motociclismo. La parola “motociclismo” era usata nei documenti 1, 5 e 9 mentre la parole “mondiali” era presente nei documenti 2, 5 e 11. Organizzando i documenti in questo modo diventa rapido individuare i documenti che contengono entrambe le parole “mondiali” e “motociclismo”, compaiono infatti soltanto nel documento 5. La lista di ID dei documenti che contiene una parola è chiamata posting list mentre cercare i documenti che contengono entrambe le parole si dice intersecting a posting list.
Ordinare i risultati
Ora abbiamo il set di pagine che contengono le parole ricercate dall’utente ed è ora di ordinare i risultati in termini di rilevanza e authority.
Google utilizza molti fattori di ranking (+200). Uno di questi, l’algoritmo del PageRank è probabilmente il più conosciuto. Il PageRank valuta due cose: quanti link puntano ad una certa pagina e la qualità delle pagine dei siti che linkano. In base al PageRank, 5 o 6 link di qualità da siti autorevoli possono valere molto di più di 10 link provenienti da siti meno autorevoli.
Una evoluzione del PageRank è stato il Reasonable Surfer PageRank (2010). Questo algoritmo assegna pesi diversi ai link presenti in pagina in base alla posizione o zona della pagina dove i link vengono inseriti. Sintetizzando il concetto si evince che un link nel footer ottiene un peso inferiore rispetto ad un link inserito nel primo paragrafo del body text.
L’immagine mostra un esempio di distribuzione del PageRank in base alla posizione del link on-page.
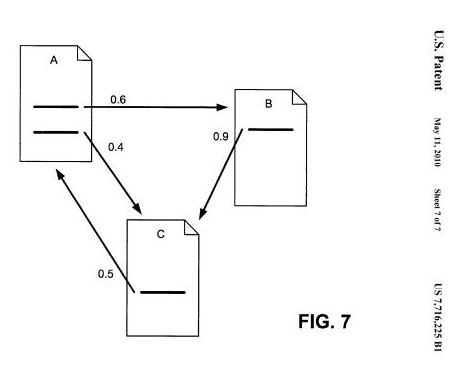
Nel brevetto che descrive questo modello ci spiega che il valore di un link può essere diverso in base a un gran numero di fattori, per esempio dove è posizionato il link nella pagina, se il collegamento è di un altro colore o stile del carattere rispetto agli altri link, quante parole sono usate nel testo di ancoraggio per il link, se il testo del collegamento utilizzato è commerciale o meno, la correlazione tra il tema della pagina che linka e quello della pagina di destinazione, se il link è un’immagine o un testo e molti altri.
Non solo PageRank
Tuttavia Google utilizza tanti altri fattori oltre al PageRank. Ad esempio, se un documento contiene le parole “mondiali” e “motociclismo” affiancate, quel documento potrebbe essere più rilevante di un documento che contiene i due termini posizionati distanti. Inoltre, se una pagina include le due parole “mondiali motociclismo” nel title tag per i motori di ricerca questo è un segnale forte di rilevanza, più forte rispetto ad una pagina che nel titolo non include quei due termini. Nello stesso modo, se i termini “mondiali motociclismo” appaiono diverse volte all’interno della pagina, quel contenuto probabilmente è più rilevante rispetto ad un documento dove le parole compaiono solo una volta e se comparissero più volte della media allora potrebbe essere identificato come spam.
Come regola Google cerca di restituire pagine che hanno una buona reputazione e sono rilevanti. Se due pagine hanno la stessa quantità di informazioni che corrispondono alla ricerca dell’utente, Google mostrerà la pagina più linkata da altri siti autorevoli. In altri casi invece una pagina con pochi link o un basso PageRank può essere scelta come migliore se risulta più rilevante e specifica. Ad esempio, una pagina web totalmente dedicata ai mondiali di motociclismo è spesso più utile di un articolo che menziona solamente i mondiali di motociclismo, anche se l’articolo è pubblicato su siti molto autorevoli.
Una volta compilata la lista di documenti e dopo aver assegnato un punteggio a ciascuno di essi, Google posiziona i risultati in base al punteggio partendo dal più alto.
Come avete visto far funzionare un motore di ricerca non è affatto semplice e richiede tantissima potenza di calcolo. Per ogni ricerca che un utente esegue vengono attivati task in circa 500 computer, il tutto in meno di mezzo secondo!
Vuoi approfondire le tue conoscenze sul funzionamento dei motori di ricerca? Ti consiglio di studiare i Patent di Google, gli articoli di Bill Slawski e di Enrico Altavilla. Aggiungo inoltre HowSearchWorks e ThinkWithGoogle.
Update 2024 – informazioni emerse durante il processo a Google
In questa seconda parte dell’articolo, che si basa dall’analisi approfondita di Natzir Turrado, approfondiamo i meccanismi interni di Google, uno strumento che tutti utilizziamo quotidianamente ma che pochi comprendono veramente.
Seguendo la recente fuga di documenti in una causa antitrust contro Google, abbiamo un’opportunità unica di esplorare gli algoritmi di Google. Alcuni di questi algoritmi erano già noti, ma ciò che è interessante sono le informazioni interne che non erano mai state condivise con noi.
Esamineremo come queste tecnologie elaborano le nostre ricerche e determinano i risultati che vediamo. In questa analisi parleremo dei sistemi complessi dietro ogni ricerca su Google.
Algoritmi di Google Svelati
Inizieremo concentrandoci sull’estrarre tutti gli algoritmi menzionati in due documenti. Il primo riguarda la testimonianza di Pandu Nayak (VP di Alphabet) e il secondo riguarda la Testimonianza di Confutazione del Professor Douglas W. Oard, relativa alle opinioni espresse dall’esperto di Google, il Prof. Edward A. Fox, nel suo rapporto datato 3 giugno 2022. Quest’ultimo documento parla del famoso e controverso «Rapporto Fox», in cui Google ha manipolato dati sperimentali per cercare di dimostrare che i dati degli utenti non sono così importanti per loro.
Cercherò di spiegare ogni algoritmo basandomi su informazioni ufficiali, se disponibili.

Navboost
Questo algoritmo è fondamentale per Google e rappresenta uno dei fattori più importanti. Questo è emerso anche nel 2019 con la fuga di informazioni «Project Veritas», perché Paul Haar lo ha aggiunto al suo CV.

Navboost raccoglie dati su come gli utenti interagiscono con i risultati di ricerca, in particolare attraverso i loro clic su diverse query. Questo sistema analizza i clic e utilizza algoritmi che apprendono da valutazioni di qualità fatte dall’uomo per migliorare il posizionamento dei risultati.
L’idea è che se un risultato viene scelto frequentemente (e valutato positivamente) per una specifica query, probabilmente dovrebbe avere un posizionamento più alto. È interessante notare che Google, molti anni fa, ha sperimentato la rimozione di Navboost e ha scoperto che i risultati peggioravano.
Il sistema Navboost, lanciato intorno al 2005 e aggiornato da allora, svolge un ruolo cruciale nell’ecosistema di ricerca di Google. Ecco una descrizione dettagliata delle sue caratteristiche:
- Registra dati clic: Navboost tiene traccia dei dati di clic dalle query degli ultimi 13 mesi, inclusi i voti di addestramento.
- Addestramento delle funzioni: Sviluppa funzioni mirate a massimizzare il posizionamento dei risultati di ricerca.
- Mappatura dei valori dei segnali: Associa valori di segnale basati su tabelle a un moltiplicatore di punteggio.
- Differenziazione tra query: Distingue tra ricerche effettuate da dispositivi mobili e desktop.
- Considerazione della posizione e del dispositivo: Prende in considerazione la posizione geografica e il tipo di dispositivo nell’ordinamento dei risultati.
- Modelli matematici: Utilizza modelli matematici che apprendono i parametri per massimizzare la Satisfaction Index (Indice di Soddisfazione, IS), basandosi sulle valutazioni degli evaluator umani.
Questo sistema è progettato per ottimizzare l’efficacia dei risultati di ricerca, utilizzando feedback reali degli utenti e valutazioni di qualità per perfezionare continuamente l’algoritmo di ranking.
Rankbrain
Lanciato nel 2015, RankBrain è un sistema di intelligenza artificiale e apprendimento automatico di Google, essenziale nel processamento dei risultati di ricerca. Attraverso l’apprendimento automatico, migliora continuamente la sua capacità di comprendere il linguaggio e le intenzioni dietro le ricerche ed è particolarmente efficace nell’interpretare query ambigue o complesse. Si dice che sia diventato il terzo fattore più importante nel ranking di Google, dopo i contenuti e i link. Utilizza un’Unità di Elaborazione Tensoriale (TPU) per migliorare notevolmente la sua capacità di elaborazione e l’efficienza energetica.
RankBrain è un modello di apprendimento profondo utilizzato nel sistema di classificazione di Google. Ecco i dettagli delle sue funzionalità:
- Modello di deep learning: RankBrain utilizza tecniche di apprendimento profondo per analizzare e interpretare le ricerche degli utenti.
- Addestrato su interazioni degli utenti: Si basa sulle preferenze di clic derivanti dalle interazioni degli utenti con i risultati di ricerca.
- Calibrato con i dati IS: Viene sintonizzato utilizzando i dati della Satisfaction Index (IS) forniti dai valutatori umani.
- Comprensione linguistica: Analizza il linguaggio sfruttando unigrammi e bigrammi.
- Esame e aggiustamento dei punteggi: Controlla e modifica i punteggi dei documenti principali.
- Costi di esecuzione: È più costoso da eseguire rispetto ad altri componenti del ranking.
- Addestramento regolare: Viene costantemente aggiornato con dati freschi provenienti da tutte le lingue e località.
Sebbene sia stato riferito che RankBrain sia diventato uno dei principali fattori di ranking di Google, è importante notare che Google usa centinaia di segnali per classificare i risultati. RankBrain è particolarmente significativo per le query nuove o rare, dove i segnali tradizionali potrebbero non essere sufficienti.
QBST e Term Weighting sono due elementi di Rankbrain.
QBST (Termini Salienti Basati sulla Query) si concentra sui termini più importanti all’interno di una query e nei documenti correlati, utilizzando queste informazioni per influenzare il modo in cui i risultati vengono classificati. Ciò significa che il motore di ricerca può riconoscere rapidamente gli aspetti più importanti della query di un utente e dare priorità ai risultati pertinenti. Ad esempio, questo è particolarmente utile per query ambigue o complesse.
Nel documento di testimonianza, QBST è menzionato nel contesto delle limitazioni di BERT. La menzione specifica è che «BERT non sostituisce sistemi di memorizzazione su larga scala come navboost, QBST, ecc.» Questo significa che, sebbene BERT sia molto efficace nella comprensione e nell’elaborazione del linguaggio naturale, presenta alcune limitazioni, una delle quali è la capacità di gestire o sostituire sistemi di memorizzazione su larga scala come QBST.
Term Weighting è un altro componente che gioca un ruolo critico all’interno di RankBrain, occupandosi di determinare il peso o l’importanza dei termini all’interno di una query o di un documento. Questo sistema permette di valutare l’importanza relativa di ciascun termine, aiutando a classificare i risultati di ricerca in modo più efficace.
QBST è addestrato su documenti e registri di clic provenienti dalle query. Ciò consente al sistema di identificare e valutare i termini chiave di una ricerca, influenzando così il ranking dei risultati. Inoltre:
- Integrazione nel ranking: QBST viene addestrato sui dati provenienti dai valutatori umani, il che migliora la sua integrazione nel sistema di ranking.
- Comprensione linguistica: Utilizza unigrammi e bigrammi per analizzare il linguaggio, permettendo una comprensione più profonda del contesto e del significato delle query.
Term Weighting regola l’importanza relativa dei singoli termini all’interno di una query, basandosi sull’interazione degli utenti con i risultati di ricerca. Questo aiuta a determinare quanto siano rilevanti certi termini nel contesto della query. Questa ponderazione gestisce anche in modo efficiente termini che sono molto comuni o molto rari nel database del motore di ricerca, equilibrando così i risultati.
Term Weighting è un processo che viene addestrato sui registri di clic derivanti dalle query. Questo componente è cruciale per:
- Addestramento: Apprendere dall’interazione degli utenti con i risultati di ricerca per determinare l’importanza di ciascun termine all’interno di una query.
- Integrazione nel ranking: Utilizza i dati provenienti dai valutatori umani per affinare il suo inserimento nel sistema di classificazione complessivo dei risultati di ricerca.
DeepRank (Bert)
Deeprank va oltre nella comprensione del linguaggio naturale, permettendo al motore di ricerca di comprendere meglio l’intenzione e il contesto delle query. Ciò è reso possibile grazie a BERT; infatti, DeepRank è il nome interno per BERT. Pre-addestrandosi su una grande quantità di dati documentali e aggiustandosi con il feedback derivante dai clic e dalle valutazioni umane, DeepRank può perfezionare i risultati di ricerca per renderli più intuitivi e pertinenti a ciò che gli utenti stanno effettivamente cercando.
DeepRank è l’ultima aggiunta ai sistemi di apprendimento profondo di Google. Le sue caratteristiche includono:
- Pre-addestramento: Utilizza dati prelevati da documenti (URL, titoli, termini rilevanti) e query/posizioni.
- Calibrazione: Affinato con dati di clic e valutazioni SI (Satisfaction Index).
- Elaborazione del linguaggio: Opera con frammenti di parole per migliorare la comprensione del linguaggio.
- Miglioramenti della rilevanza: Apporta miglioramenti nella rilevanza dei risultati di ricerca e nella comprensione linguistica.
- Apprendimento interpretativo: Impara interpretazioni linguistiche e senso comune dagli evaluator umani.
RankEmbed
RankEmbed si focalizza probabilmente sull’incorporare caratteristiche rilevanti per il ranking. Sebbene non ci siano dettagli specifici sulle sue funzioni e capacità nei documenti, possiamo dedurre che si tratti di un sistema di apprendimento profondo progettato per migliorare il processo di classificazione delle ricerche di Google.
RankEmbed-BERT
RankEmbed-BERT è una versione migliorata di RankEmbed, che integra l’algoritmo e la struttura di BERT. Questa integrazione è stata realizzata per migliorare significativamente le capacità di comprensione del linguaggio di RankEmbed. La sua efficacia può diminuire se non viene riaddestrato con dati recenti. Per il suo addestramento, utilizza solo una piccola frazione del traffico, indicando che non è necessario usare tutti i dati disponibili.
RankEmbed-BERT contribuisce, insieme ad altri modelli di apprendimento profondo come RankBrain e DeepRank, al punteggio finale di ranking nel sistema di ricerca di Google, ma opererebbe dopo il recupero iniziale dei risultati (ri-classificazione). È addestrato su dati di clic e query e finemente sintonizzato utilizzando dati da valutatori umani (IS) ed è più costoso dal punto di vista computazionale da addestrare rispetto a modelli feedforward come RankBrain.
- Addestrato su documenti, query, registri di clic e dati dei valutatori umani: RankEmbed-BERT affina la sua precisione e rilevanza attraverso un ampio addestramento su diversi tipi di dati.
- Utilizza termini salienti e dati da Navboost: Impiega informazioni chiave e apprendimenti dal sistema Navboost per ottimizzare il ranking.
- BERT integrato in DeepRank per compiti di classificazione: BERT è parte di DeepRank e viene usato per migliorare le capacità di classificazione del sistema di ricerca.
MUM (Multitask Unified Model)
È approssimativamente 1.000 volte più potente di BERT e rappresenta un grande avanzamento nella ricerca di Google. Lanciato nel giugno 2021, non solo comprende 75 lingue, ma è anche multimodale, il che significa che può interpretare ed elaborare informazioni in diversi formati. Questa capacità multimodale permette a MUM di offrire risposte più complete e contestualizzate, riducendo la necessità di effettuare molteplici ricerche per ottenere informazioni dettagliate. Tuttavia, il suo utilizzo è molto selettivo a causa della sua elevata richiesta computazionale.
- Un modello avanzato di intelligenza artificiale: Progettato per comprendere il linguaggio e le informazioni.
- Riconosciuto per il suo potenziale trasformativo e l’alto consumo energetico.
- Non utilizzato in produzione per ogni query a causa delle sue dimensioni e lentezza.
- Viene usato per addestrare modelli più piccoli e specifici per la produzione che possono operare più efficacemente in un ambiente di produzione.
Tangram e Glue
Tangram e Glue sono sistemi fondamentali per l’organizzazione e l’ottimizzazione delle SERP (Search Engine Results Pages) di Google, ma non sono tra i più noti pubblicamente. Le informazioni sul loro funzionamento sono limitate, in gran parte a causa della natura riservata delle tecnologie di Google.
Questi due sistemi operano all’interno del quadro di Tangram, che è responsabile per assemblare la SERP (Search Engine Results Page, Pagina dei Risultati del Motore di Ricerca) con i dati provenienti da Glue. Questo non riguarda solo il ranking dei risultati, ma anche la loro organizzazione in un modo che sia utile e accessibile agli utenti, considerando elementi come caroselli di immagini, risposte dirette e altri elementi non testuali.
Tangram
- Assembla la SERP: Organizzando elementi come risultati web, caroselli e snippet.
- Ottimizzazione dell’Esperienza Utente: Uno degli obiettivi principali di Tangram è migliorare l’esperienza dell’utente, assicurando che i vari elementi della SERP siano presentati in un modo che sia intuitivo e facile da navigare.
- Adattabilità a Diverse Query: Tangram può adattare la composizione della SERP in base al tipo di query, per esempio enfatizzando risultati visivi per query che richiedono immagini o fornendo risposte dirette per domande specifiche.
- Precedentemente conosciuto come Tetris: Il cambio di nome suggerisce miglioramenti nella capacità organizzativa.
Glue
- Operativo dal 2013: Glue è attivo da almeno quell’anno.
- Glue funge da ponte tra vari algoritmi e sistemi di Google, aiutando a integrare i dati e le informazioni da diverse fonti per un ranking efficace dei risultati.
- Generalizzazione ed estensione di Navboost: Collabora con Navboost nella determinazione e nel ranking dei contenuti.
- Modello unificato: Interpreta segnali di interazione degli utenti per tutti i tipi di risultati di ricerca.
- Utilizzato in Web, KE (Knowledge Engine o Knowledge Graph Engine) e WebAnswers: Impiegato in diverse aree per ottimizzare la ricerca.
- Considera il costo dell’interazione: Valuta l’impatto dell’interazione su dispositivi mobili e tipologie diverse di risultati di ricerca.
Google tende a mantenere riservate informazioni dettagliate sui suoi algoritmi e sistemi interni. Ciò include Tangram e Glue. Gli aggiornamenti e le modifiche a questi sistemi sono probabilmente continui, ma non vengono generalmente divulgati pubblicamente.
Freshness Node e Instant Glue
Questi sistemi garantiscono l’attualità dei risultati, dando maggiore peso alle informazioni recenti, il che è particolarmente cruciale nelle ricerche relative a notizie o eventi attuali.
Freshness Node Tangram
- Garantisce che i segnali di ranking riflettano l’attualità delle informazioni.
- Promuove contenuti aggiornati e rilevanti.
- Combina Instant Glue con i segnali regolari di Google.
- Suscettibile al ‘grandfathering’ nella valutazione delle caratteristiche: ovvero, attribuisce troppo valore alle caratteristiche basate sulle loro prestazioni passate, senza considerare la rilevanza attuale.
Instant Glue
- Pipeline in tempo reale che aggrega frazioni di segnali di interazione degli utenti.
- Include solo i record delle ultime 24 ore con una latenza di circa 10 minuti.
- Riflette lo stato attuale del mondo nei segnali di ranking.
Nel processo, si fa riferimento all’attacco di Nizza, dove l’intento principale della query è cambiato il giorno dell’attacco, portando Instant Glue a sopprimere le immagini generali a Tangram e invece a promuovere notizie pertinenti e fotografie di Nizza («belle immagini» contro «immagini di Nizza»):
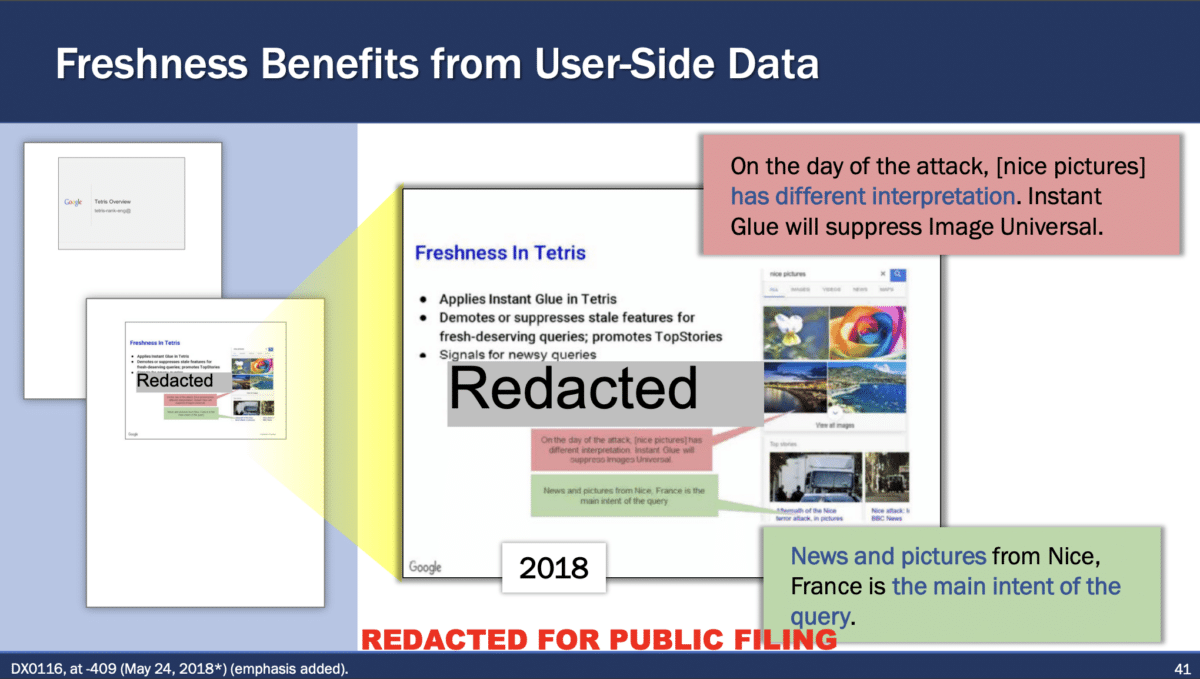
Questo esempio illustra come Instant Glue e Tangram lavorino insieme per adattare i risultati di ricerca in tempo reale in risposta a eventi significativi, modificando l’interpretazione e la classificazione dei termini di ricerca in base al contesto attuale.
Google combinerebbe questi algoritmi per:
- Comprendere la query: Decifrare l’intenzione dietro le parole e le frasi inserite dagli utenti nella barra di ricerca.
- Determinare la rilevanza: Classificare i risultati in base a quanto i contenuti corrispondano alla query, utilizzando segnali derivanti da interazioni passate e valutazioni di qualità.
- Prioritizzare l’attualità: Assicurare che le informazioni più fresche e rilevanti salgano nel ranking quando è importante farlo.
- Personalizzare i risultati: Adattare i risultati di ricerca non solo alla query ma anche al contesto dell’utente, come la loro posizione geografica e il dispositivo che stanno utilizzando. Difficilmente c’è più personalizzazione di così.
- Da quanto abbiamo visto finora, credo che Tangram, Glue e RankEmbed-BERT siano gli unici elementi novità trapelati fino ad oggi.
Come abbiamo visto, questi algoritmi sono alimentati da varie metriche che ora andremo a scomporre, estraendo nuovamente informazioni dal processo.
Metriche Utilizzate da Google per Valutare la Qualità della Ricerca
In questa sezione, ci concentreremo nuovamente sulla Testimonianza di Confutazione del Professor Douglas W. Oard e includeremo informazioni provenienti da una precedente fuga di informazioni, quella del «Project Veritas».
In una delle slide, è stato mostrato che Google utilizza alcune metriche per sviluppare e aggiustare i fattori considerati dal suo algoritmo quando classifica i risultati di ricerca e per monitorare come i cambiamenti nel suo algoritmo influenzino la qualità dei risultati di ricerca. L’obiettivo è cercare di catturare l’intento dell’utente con esse. Vediamo queste metriche.
Punteggio IS (Information Satisfaction Score)
I valutatori umani svolgono un ruolo cruciale nello sviluppo e nel perfezionamento dei prodotti di ricerca di Google. Attraverso il loro lavoro, viene generata la metrica nota come «punteggio IS» (Information Satisfaction Score che va da 0 a 100), derivata dalle valutazioni dei valutatori e utilizzata come indicatore principale della qualità in Google.
Il punteggio viene valutato in modo anonimo, dove i valutatori non sanno se stanno testando Google o Bing, ed è usata per confrontare le prestazioni di Google con il suo principale concorrente.
Questi punteggi IS non riflettono solo la qualità percepita, ma sono anche usati per addestrare vari modelli all’interno del sistema di ricerca di Google, inclusi algoritmi di classificazione come RankBrain e RankEmbed BERT.
Secondo i documenti, a partire dal 2021, stanno utilizzando IS4. IS4 è considerato un’approssimazione dell’utilità per l’utente e dovrebbe essere trattato come tale. Viene descritto come la metrica di ranking più importante, tuttavia sottolineano che è un’approssimazione e incline a errori che discuteremo più avanti.

Una derivazione di questa metrica, l’IS4@5, è anch’essa menzionata.
La metrica IS4@5 è utilizzata da Google per misurare la qualità dei risultati di ricerca, concentrando l’attenzione specificamente sulle prime cinque posizioni. Questa metrica include anche funzionalità di ricerca speciali, come le OneBoxes (note come «link blu»). Esiste una variante di questa metrica, denominata IS4@5 web, che si focalizza esclusivamente sulla valutazione dei primi cinque risultati web, escludendo altri elementi come la pubblicità nei risultati di ricerca.

Sebbene l’IS4@5 sia utile per valutare rapidamente la qualità e la rilevanza dei risultati principali in una ricerca, il suo ambito è limitato. Non copre tutti gli aspetti della qualità della ricerca, omettendo in particolare elementi come la pubblicità nei risultati. Pertanto, la metrica fornisce una visione parziale della qualità della ricerca. Per una valutazione completa e accurata della qualità dei risultati di ricerca di Google, è necessario considerare una gamma più ampia di metriche e fattori, simile a come la salute generale viene valutata attraverso una varietà di indicatori e non solo in base al peso.
Limitazioni degli Evaluatori Umani
Gli evaluatori affrontano diversi problemi, come la comprensione di query tecniche o la valutazione della popolarità di prodotti o interpretazioni di query. Inoltre, i modelli di linguaggio come MUM potrebbero arrivare a comprendere il linguaggio e la conoscenza globale in modo simile agli evaluatori umani, presentando sia opportunità che sfide per il futuro della valutazione della rilevanza.
Nonostante la loro importanza, la loro prospettiva differisce significativamente da quella degli utenti reali. Gli evaluatori possono mancare di conoscenze specifiche o esperienze precedenti che gli utenti potrebbero avere in relazione a un argomento di ricerca, influenzando potenzialmente la loro valutazione della rilevanza e della qualità dei risultati di ricerca.
Da documenti trapelati nel 2018 e nel 2021, sono riuscito a compilare un elenco di tutti gli errori che Google riconosce di avere nelle loro presentazioni interne.
- Incongruenze Temporali: Possono verificarsi discrepanze perché le query, le valutazioni e i documenti possono essere di periodi differenti, portando a valutazioni che non riflettono accuratamente l’attuale rilevanza dei documenti.
- Riutilizzo delle Valutazioni: La pratica di riutilizzare le valutazioni per valutare rapidamente e controllare i costi può risultare in valutazioni non rappresentative dell’attuale freschezza o rilevanza del contenuto.
- Comprensione delle Query Tecniche: Gli evaluator potrebbero non comprendere le query tecniche, portando a difficoltà nella valutazione della rilevanza di argomenti specializzati o di nicchia.
- Valutazione della Popolarità: Gli evaluator hanno difficoltà intrinseche nel giudicare la popolarità tra interpretazioni competitive di query o prodotti rivali, ciò potrebbe influenzare l’accuratezza delle loro valutazioni.
- Diversità degli Evaluator: La mancanza di diversità tra gli evaluator in alcune località, e il fatto che siano tutti adulti, non riflette la diversità della base di utenti di Google, che include anche i minori.
- Contenuto Generato dagli Utenti: Gli evaluator tendono ad essere severi con i contenuti generati dagli utenti, il che può portare a sottovalutare il loro valore e la loro rilevanza, nonostante possano essere utili e pertinenti.
- Formazione del Nodo di Freschezza: Segnalano un problema con la regolazione dei modelli di freschezza a causa della mancanza di etichette di formazione adeguate. Gli evaluator umani spesso non prestano sufficiente attenzione all’aspetto della freschezza della rilevanza o mancano del contesto temporale per la query. Ciò risulta nella sottovalutazione dei risultati recenti per query che cercano novità. L’esistente Utility Tangram, basata su IS e utilizzata per addestrare Relevance e altre curve di punteggio, soffriva dello stesso problema. A causa della limitazione delle etichette umane, le curve di punteggio del Nodo di Freschezza sono state regolate manualmente al momento del suo primo rilascio.
Credo che gli evaluator umani siano stati responsabili del funzionamento efficace del «Parasite SEO», un argomento giunto all’attenzione di Danny Sullivan.
Se osserviamo le modifiche nelle ultime linee guida sulla qualità, possiamo notare come abbiano finalmente adeguato la definizione delle metriche di “Esigenze Soddisfatte” e abbiano incluso un nuovo esempio per gli evaluator da considerare: anche se un risultato è autorevole, se non contiene le informazioni che l’utente sta cercando, non dovrebbe essere valutato altrettanto positivamente.

Il lancio di Google Notes potrebbe essere interpretato come una risposta alle limitazioni intrinseche nel processo di valutazione della qualità del contenuto da parte degli evaluator umani. Questo nuovo strumento suggerisce una crescente consapevolezza da parte di Google riguardo alle sfide nell’identificare con precisione cosa sia considerato ‘contenuto di qualità’ dai diversi utenti. La contemporaneità di questi sviluppi – la revisione delle linee guida per gli evaluator e l’introduzione di Google Notes – potrebbe indicare un collegamento strategico, mirato a migliorare la precisione con cui Google identifica e classifica il contenuto di qualità nelle SERP.
PQ (Qualità della Pagina)
In merito a questo fattore, non c’è nulla nei documenti del processo oltre alla sua menzione come metrica utilizzata. L’unica cosa ufficiale che menziona PQ proviene dalle Linee Guida per i Valutatori della Qualità di Ricerca, che cambiano nel tempo. Quindi, sarebbe un altro compito per gli evaluator umani.

Ecco una traduzione in italiano e la sintesi in elenco puntato delle informazioni contenute nell’immagine:
- Bassissimo: Le pagine di qualità più bassa sono inaffidabili, ingannevoli, dannose per le persone o la società, o presentano altre caratteristiche fortemente indesiderabili. (Nella Sezione 4.0 delle linee guida sono inclusi esempi di pagine che potrebbero essere dannose).
- Basso: Le pagine di bassa qualità potrebbero essere state create per servire uno scopo benefico. Tuttavia, non raggiungono bene il loro scopo perché mancano di una dimensione importante.
- Medio: La pagina ha uno scopo benefico e lo raggiunge; tuttavia, non merita una valutazione di alta qualità, né vi sono elementi che giustifichino una valutazione di bassa qualità. La pagina o il sito web presenta forti caratteristiche di alta qualità, ma possiede anche lievi caratteristiche di bassa qualità. Gli aspetti di alta qualità rendono difficile valutare la pagina come bassa.
- Alto: Una pagina di alta qualità serve uno scopo benefico e lo raggiunge bene.
- Altissimo: Una pagina di qualità altissima serve uno scopo benefico e lo raggiunge molto bene.
Queste informazioni vengono anche inviate agli algoritmi per creare modelli. Qui possiamo vedere una proposta trapelata nel «Progetto Veritas»:
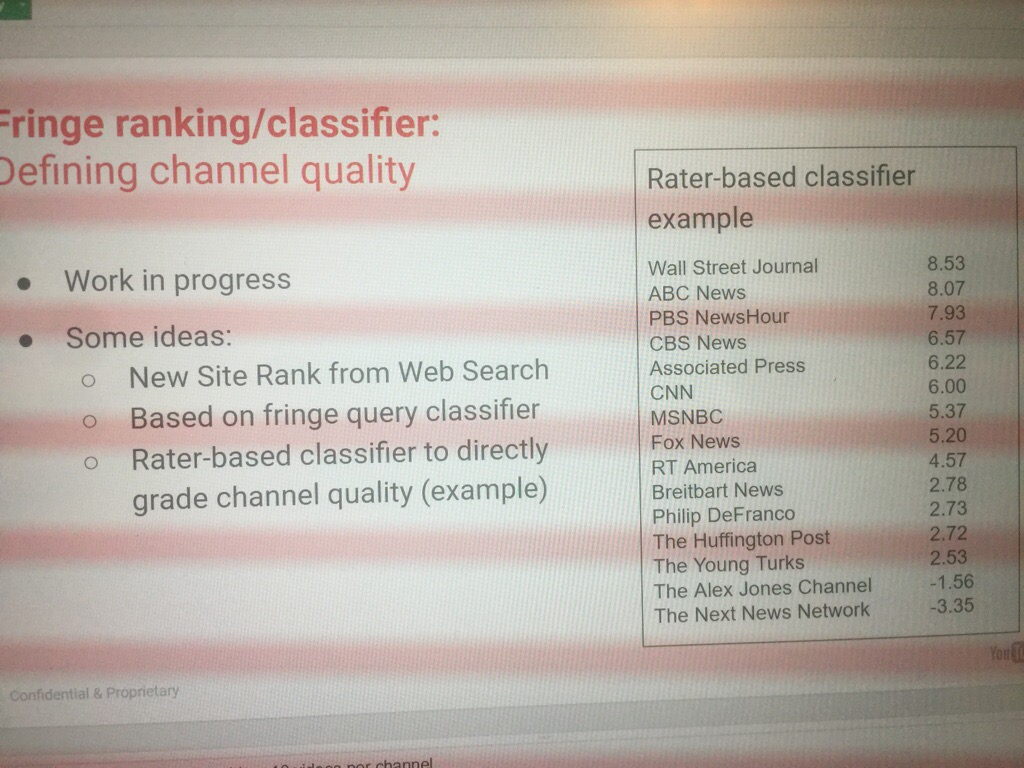
Un punto interessante, secondo i documenti, è che i valutatori di qualità valutano le pagine solo su mobile.

Test Affiancati
Questo fattore probabilmente si riferisce a test in cui due insiemi di risultati di ricerca vengono posti uno accanto all’altro in modo che gli evaluator possano confrontarne la qualità relativa. Questo aiuta a determinare quale insieme di risultati sia più rilevante o utile per una data query di ricerca. Se è così, ricordo che Google aveva il proprio strumento scaricabile per questo, lo sxse.
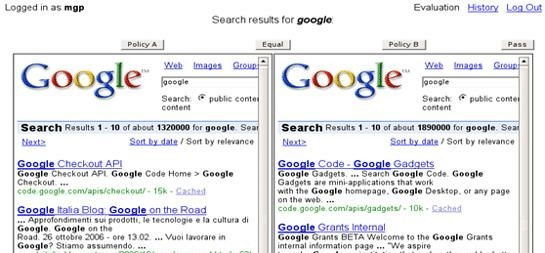
Lo strumento permette agli utenti di votare per l’insieme di risultati di ricerca che preferiscono, fornendo così un feedback diretto sull’efficacia di diversi aggiustamenti o versioni dei sistemi di ricerca.
Esperimenti Dal Vivo
Le informazioni ufficiali pubblicate in “Come Funziona la Ricerca” affermano che Google conduce esperimenti con traffico reale per testare come le persone interagiscono con una nuova funzionalità prima di renderla disponibile a tutti.
In pratica, Google attiva la funzione per una piccola percentuale di utenti e confronta il loro comportamento con un gruppo di controllo che non dispone della funzionalità.
Le metriche dettagliate sull’interazione degli utenti con i risultati di ricerca includono:
- Click sui risultati
- Numero di ricerche effettuate
- Abbandono della query
- Tempo impiegato dalle persone per cliccare su un risultato
Questi dati aiutano a misurare se l’interazione con la nuova funzionalità è positiva e garantiscono che le modifiche aumentino la rilevanza e l’utilità dei risultati di ricerca.
Tuttavia, i documenti del processo evidenziano solo due metriche:

- Click lunghi ponderati in base alla posizione: Questa metrica considererebbe la durata dei click e la loro posizione sulla pagina dei risultati, riflettendo la soddisfazione dell’utente con i risultati trovati.
- Attenzione: Questo potrebbe implicare la misurazione del tempo trascorso sulla pagina, dando un’idea di quanto tempo gli utenti interagiscono con i risultati e il loro contenuto.
Inoltre, nella trascrizione della testimonianza di Pandu Nayak, viene spiegato che conducono numerosi test sugli algoritmi utilizzando l’intrecciamento invece dei tradizionali test A/B. Ciò permette loro di eseguire esperimenti rapidi e affidabili, consentendo loro di interpretare le fluttuazioni nelle classifiche.
L’intrecciamento, nel contesto degli esperimenti sugli algoritmi di ricerca, è una metodologia di test utilizzata per valutare le variazioni nelle SERP (Search Engine Results Pages) e per determinare quale versione di un algoritmo fornisce i risultati migliori. Diversamente dai tradizionali test A/B che presentano agli utenti due versioni separate (A e B), l’intrecciamento combina elementi di entrambe le versioni di un algoritmo in un unico insieme di risultati di ricerca.
Ecco come funziona l’intrecciamento:
- Combinazione di Risultati: Le SERP generate da due distinti algoritmi (per esempio, l’algoritmo corrente e una sua nuova versione) sono combinate o “intrecciate”. Questo significa che i risultati di ricerca da entrambi gli algoritmi sono presentati nella stessa pagina, ma in ordine alterno.
- Interazione degli Utenti: Gli utenti interagiscono con questa SERP combinata senza sapere che i risultati sono generati da due algoritmi differenti.
- Analisi dei Dati: Gli ingegneri analizzano poi come gli utenti interagiscono con i risultati di ricerca. Per esempio, se gli utenti cliccano più frequentemente sui risultati generati dall’algoritmo B piuttosto che quelli dell’algoritmo A, questo potrebbe indicare che B fornisce risultati di qualità superiore.
- Rapidità e Affidabilità: L’intrecciamento permette di eseguire test più rapidi e affidabili rispetto ai test A/B. Poiché gli utenti sono esposti a una pagina di risultati che include entrambe le varianti, è possibile raccogliere dati più rapidamente e con maggiore fiducia, dato che ogni SERP contiene una varietà di risultati da valutare.
- Prevenzione dei Bias: Questo metodo aiuta anche a prevenire il bias che potrebbe sorgere se si mostrassero agli utenti solo una versione dei risultati per volta, come avviene nei test A/B.
In sintesi, l’intrecciamento è una tecnica avanzata per testare le modifiche agli algoritmi di ricerca, che permette ai motori di ricerca come Google di ottimizzare continuamente la qualità e la pertinenza dei risultati presentati agli utenti.
Freschezza (Freshness)
La freschezza è un aspetto cruciale sia per i risultati sia per le Funzionalità di Ricerca. È essenziale mostrare informazioni pertinenti non appena disponibili e smettere di mostrare contenuti quando diventano obsoleti.
Perché gli algoritmi di ranking mostrino documenti recenti nella SERP, i sistemi di indicizzazione e di erogazione devono essere in grado di scoprire, indicizzare e servire documenti freschi con bassissima latenza. Anche se idealmente l’intero indice dovrebbe essere il più aggiornato possibile, ci sono vincoli tecnici e di costo che impediscono di indicizzare ogni documento con bassa latenza. Il sistema di indicizzazione dà priorità ai documenti su percorsi separati, offrendo diversi compromessi tra latenza, costo e qualità.
C’è il rischio che i contenuti molto freschi vedano la loro rilevanza sottovalutata e, al contrario, che i contenuti con molte prove di rilevanza diventino meno pertinenti a causa di un cambiamento nel significato della query.

Il ruolo del Nodo di Freschezza è quello di aggiungere correzioni ai punteggi obsoleti. Per le query che cercano contenuti freschi, promuove i contenuti freschi e declassa quelli obsoleti.
Non molto tempo fa, è trapelato che Google Caffeine non esiste più (noto anche come sistema di indicizzazione basato su Percolator).
Google Caffeine è stato un importante aggiornamento dell’infrastruttura di indicizzazione di Google, lanciato ufficialmente nel giugno 2010. Non era un aggiornamento dell’algoritmo classico, ma piuttosto una ristrutturazione completa del sistema di indicizzazione, per rispondere alle esigenze di un Web in rapida evoluzione e alle aspettative degli utenti per risultati di ricerca più rapidi e pertinenti. Google Caffeine ha rappresentato un passo significativo verso il miglioramento dell’efficienza con cui Google elabora e fornisce risultati di ricerca, enfatizzando la freschezza e la rilevanza dei contenuti. L’aggiornamento ha reso Google in grado di tenere il passo con la crescente quantità di informazioni su Internet e con le mutevoli aspettative degli utenti.
Anche se internamente si utilizza ancora il vecchio nome, ciò che esiste ora è in realtà un sistema completamente nuovo. Il nuovo «caffeina» è in realtà un insieme di microservizi che comunicano tra loro. Ciò implica che diverse parti del sistema di indicizzazione operino come servizi indipendenti ma interconnessi, ognuno con una funzione specifica. Questa struttura può offrire maggiore flessibilità, scalabilità e facilità nell’apportare aggiornamenti e miglioramenti.
Da quello che si legge, parte di questi microservizi sarebbero Tangram e Glue, specificamente il Nodo di Freschezza e Instant Glue. In un altro documento trapelato dal «Progetto Veritas» c’era una proposta del 2016 di realizzare o incorporare un «Instant Navboost» come segnale di freschezza, così come le visite Chrome.
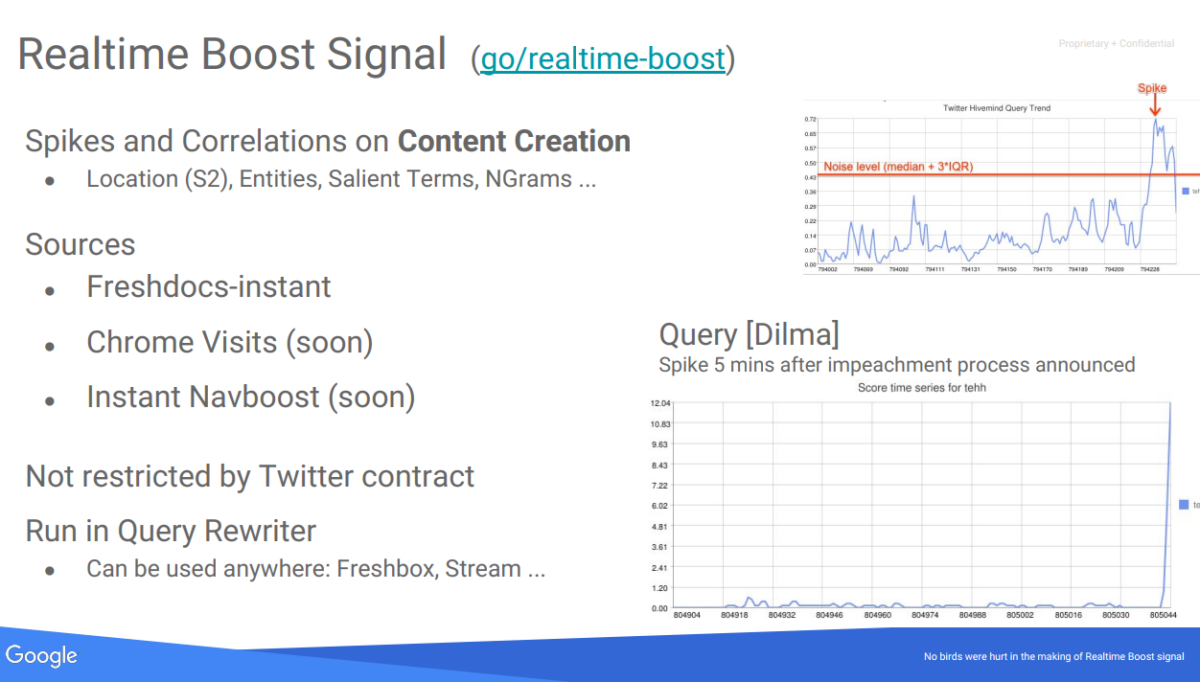
Finora, avevano già incorporato «Freshdocs-instant» (estratto da un elenco di pubsub chiamato freshdocs-instant-docs pubsub, dove prendevano le notizie pubblicate da quei media entro 1 minuto dalla loro pubblicazione) e picchi di ricerca e correlazioni nella generazione di contenuti:
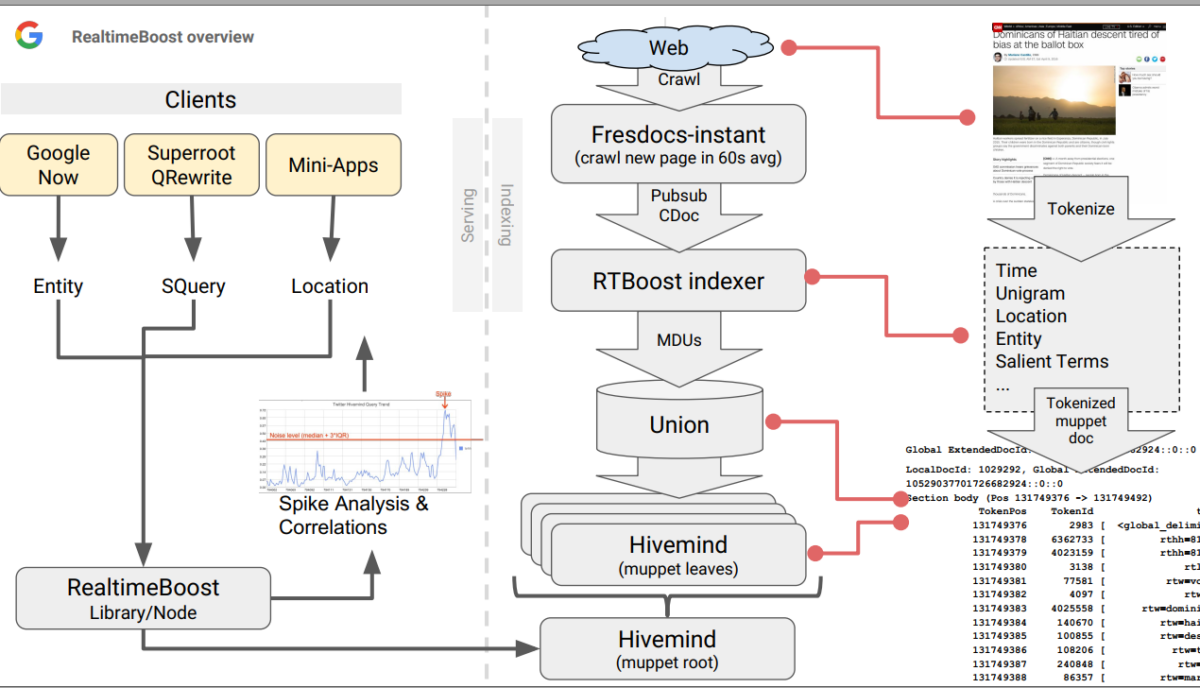
All’interno delle metriche di Freschezza, abbiamo diverse che vengono rilevate grazie all’analisi di Correlated Ngrams e Correlated Salient Terms:
- Ngrammi Correlati: Questi sono gruppi di parole che appaiono insieme in un modello statisticamente significativo. La correlazione può aumentare improvvisamente durante un evento o un argomento di tendenza, indicando un picco.
- Termini Salienti Correlati: Questi sono termini di spicco strettamente associati a un argomento o evento e la cui frequenza di comparsa aumenta nei documenti in un breve periodo, suggerendo un picco di interesse o attività correlata.
Una volta rilevati i picchi, le seguenti metriche di Freschezza potrebbero essere utilizzate:
- Unigrammi (RTW): Per ogni documento, vengono utilizzati il titolo, i testi di ancoraggio e i primi 400 caratteri del testo principale. Questi vengono suddivisi in unigrammi rilevanti per il rilevamento di tendenze e aggiunti all’indice Hivemind. Il testo principale contiene generalmente il contenuto principale dell’articolo, escludendo elementi ripetitivi o comuni (boilerplate).
- Mezz’ore dall’epoca (TEHH): È una misura del tempo espressa come numero di mezz’ore dall’inizio del tempo Unix. Aiuta a stabilire quando è avvenuto qualcosa con precisione di mezz’ora.
- Entità del Knowledge Graph (RTKG): Riferimenti a oggetti nel Knowledge Graph di Google, che è un database di entità reali (persone, luoghi, cose) e delle loro interconnessioni. Aiuta ad arricchire la ricerca con comprensione semantica e contesto.
- Celle S2 (S2): Riferimenti a oggetti nel Knowledge Graph di Google, che è un database di entità reali (persone, luoghi, cose) e delle loro interconnessioni. Aiuta ad arricchire la ricerca con comprensione semantica e contesto.
- Punteggio Articolo Freshbox (RTF): Sono divisioni geometriche della superficie terrestre utilizzate per l’indicizzazione geografica nelle mappe. Facilitano l’associazione di contenuti web con localizzazioni geografiche precise.
- NSR del Documento (RTN): Potrebbe riferirsi alla Rilevanza delle Notizie del Documento e sembra essere una metrica che determina quanto un documento sia rilevante e affidabile in relazione alle storie correnti o agli eventi di tendenza. Questa metrica può anche aiutare a filtrare contenuti di bassa qualità o spam, garantendo che i documenti indicizzati e evidenziati siano di alta qualità e significativi per ricerche in tempo reale.
- Dimensioni Geografiche: Caratteristiche che definiscono la posizione geografica di un evento o argomento menzionato nel documento. Possono includere coordinate, nomi di luoghi o identificatori come le celle S2.
Se lavori nei media, queste informazioni sono fondamentali e le includo sempre nei miei corsi per editor digitali.
L’Importanza dei Click
In questa sezione, ci concentreremo sulla presentazione interna di Google condivisa in una email, intitolata «Unified Click Prediction», la presentazione «Google is Magical», la presentazione di Search All Hands, una email interna di Danny Sullivan e i documenti trapelati dal «Progetto Veritas».
Durante questo processo, vediamo l’importanza fondamentale dei click per comprendere il comportamento e le esigenze degli utenti. In altre parole, Google ha bisogno dei nostri dati. È interessante notare che una delle cose di cui Google era proibito parlare erano proprio i click.
I documenti principali discussi sui click risalgono a prima del 2016, e da allora Google ha subito cambiamenti significativi. Nonostante questa evoluzione, la base del loro approccio rimane l’analisi del comportamento degli utenti, considerandola un segnale di qualità. Ti ricordi il brevetto in cui spiegano il modello CAS?

Ogni ricerca e click forniti dagli utenti contribuiscono all’apprendimento e al miglioramento continuo di Google. Questo ciclo di feedback permette a Google di adattarsi e «imparare» sulle preferenze e comportamenti di ricerca, mantenendo l’illusione di comprendere le esigenze degli utenti.
Ogni giorno, Google analizza oltre un miliardo di nuovi comportamenti all’interno di un sistema progettato per regolarsi continuamente e superare le previsioni future basate sui dati passati. Almeno fino al 2016, questo superava la capacità dei sistemi di intelligenza artificiale dell’epoca, richiedendo il lavoro manuale che abbiamo visto in precedenza e anche gli aggiustamenti effettuati da RankLab.
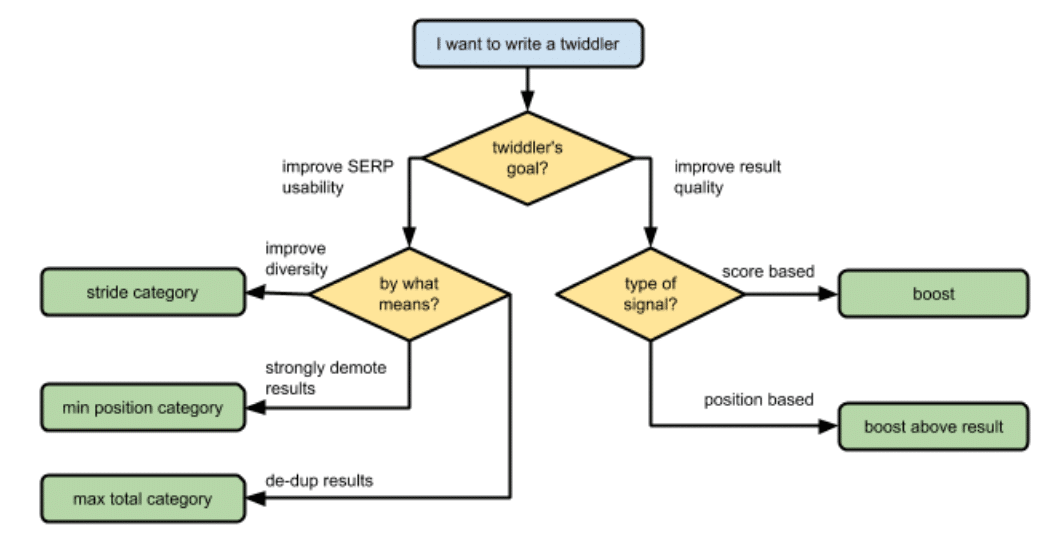
RankLab dovrebbe essere un laboratorio che testa diversi pesi nei segnali e nei fattori di ranking, così come il loro impatto successivo. Potrebbero anche essere responsabili dello strumento interno «Twiddler» (qualcosa che ho letto anche anni fa dal «Progetto Veritas»), con lo scopo di modificare manualmente i punteggi IR di certi risultati.
Mentre le valutazioni degli evaluator umani offrono una visione di base, i click forniscono un panorama molto più dettagliato del comportamento di ricerca.

Questo rivela schemi complessi e permette l’apprendimento di effetti di secondo e terzo ordine.
- Effetti di secondo ordine riflettono schemi emergenti: se la maggioranza preferisce e sceglie articoli dettagliati rispetto a liste rapide, Google lo rileva. Nel tempo, adatta i suoi algoritmi per dare priorità a quegli articoli più dettagliati nelle ricerche correlate.
- Effetti di terzo ordine sono cambiamenti più ampi e a lungo termine: se le tendenze dei click favoriscono guide complete, i creatori di contenuti si adattano. Iniziano a produrre articoli più dettagliati e meno liste, cambiando così la natura dei contenuti disponibili sul web.
Nei documenti analizzati, viene presentato un caso specifico in cui la rilevanza dei risultati di ricerca è stata migliorata attraverso l’analisi dei click. Google ha identificato una discrepanza nella preferenza degli utenti, basata sui click, verso alcuni documenti che si sono rivelati rilevanti, nonostante fossero circondati da un insieme di 15.000 documenti considerati irrilevanti. Questa scoperta evidenzia l’importanza dei click degli utenti come strumento prezioso per discernere la rilevanza nascosta in grandi volumi di dati.

Google «si allena con il passato per prevedere il futuro» per evitare l’overfitting. Attraverso valutazioni costanti e aggiornamento dei dati, i modelli rimangono attuali e pertinenti. Un aspetto chiave di questa strategia è la personalizzazione della localizzazione, assicurando che i risultati siano pertinenti per diversi utenti in varie regioni.
Riguardo alla personalizzazione, in un documento più recente, Google afferma che è limitata e raramente cambia i ranking. Menzionano anche che non avviene mai in «Top Stories». Le volte in cui è usata è per comprendere meglio cosa si sta cercando, ad esempio utilizzando il contesto delle ricerche precedenti e anche per fare suggerimenti predittivi con l’autocompletamento. Menzionano che potrebbero leggermente elevare un fornitore di video che l’utente utilizza frequentemente, ma tutti vedrebbero sostanzialmente gli stessi risultati. Secondo loro, la query è più importante dei dati dell’utente.
È importante ricordare che questo approccio focalizzato sui click affronta delle sfide, specialmente con contenuti nuovi o poco frequenti. Valutare la qualità dei risultati di ricerca è un processo complesso che va oltre il semplice conteggio dei click.
Architettura di Google
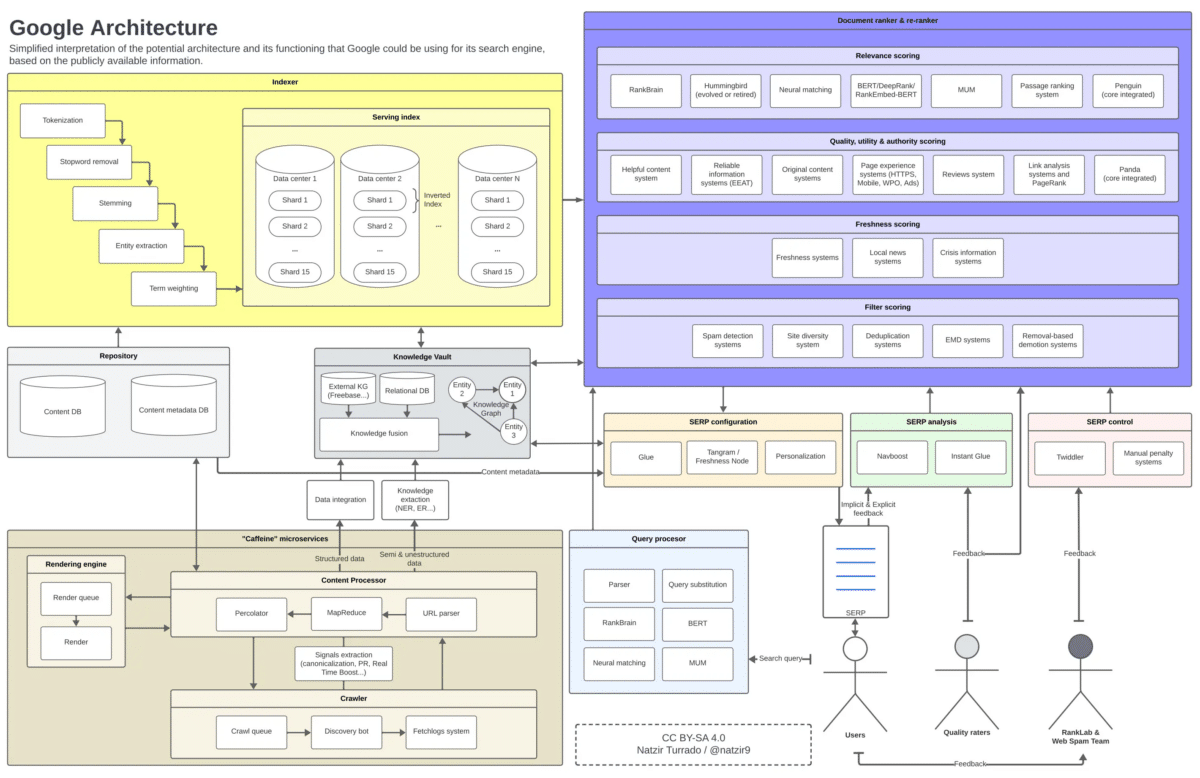
Proseguendo dalla sezione precedente, questa è l’immagine mentale che mi sono formato di come potremmo posizionare tutti questi elementi in un diagramma. È molto probabile che alcuni componenti dell’architettura di Google non siano in certi posti o non si relazionino come tale, ma credo sia più che sufficiente come approssimazione.
Google e Chrome
In questa ultima sezione, ci concentriamo sulla testimonianza del testimone esperto Antonio Rangel, Economista Comportamentale e Professore al Caltech, riguardo l’uso delle opzioni predefinite per influenzare le scelte degli utenti, nella presentazione interna rivelata «Sul Valore Strategico della Pagina Iniziale Predefinita per Google», e nelle dichiarazioni di Jim Kolotouros, VP di Google, in una email interna.
Come rivela Jim Kolotouros nelle comunicazioni interne, Chrome non è solo un browser, ma un pezzo chiave nel puzzle della dominanza di Google nella ricerca.
Tra i dati raccolti da Google ci sono schemi di ricerca, clic sui risultati di ricerca e interazioni con diversi siti web, cruciali per affinare gli algoritmi di Google e migliorare l’accuratezza dei risultati di ricerca e l’efficacia della pubblicità mirata.
Per Antonio Rangel, la supremazia di mercato di Chrome trascende la sua popolarità. Agisce come un portale verso l’ecosistema di Google, influenzando come gli utenti accedono alle informazioni e ai servizi online. L’integrazione di Chrome con Google Search, essendo il motore di ricerca predefinito, garantisce a Google un vantaggio significativo nel controllare il flusso di informazioni e pubblicità digitale.

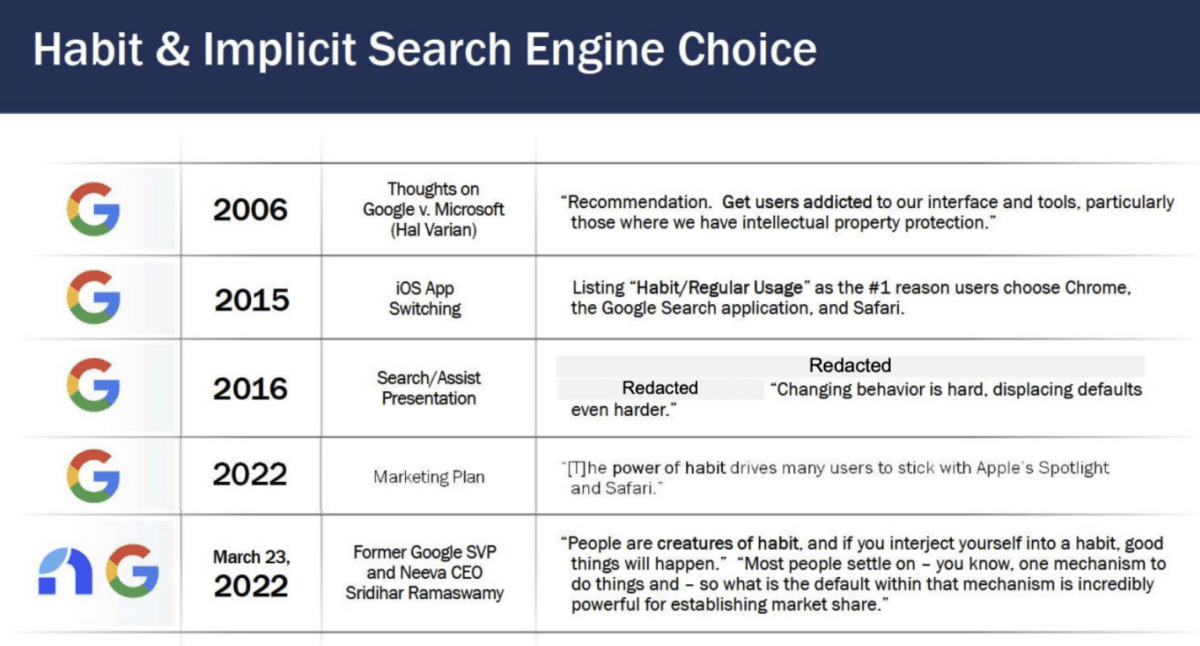
Nonostante la popolarità di Google, Bing non è un motore di ricerca inferiore. Tuttavia, molti utenti preferiscono Google per la comodità della sua configurazione predefinita e i bias cognitivi associati. Su dispositivi mobili, gli effetti dei motori di ricerca predefiniti sono più forti a causa dell’attrito nel cambiarli; fino a 12 clic sono richiesti per modificare il motore di ricerca predefinito.
Questa preferenza predefinita influenza anche le decisioni sulla privacy dei consumatori. Le impostazioni predefinite sulla privacy di Google presentano un attrito significativo per coloro che preferiscono una raccolta di dati più limitata. Cambiare l’opzione predefinita richiede consapevolezza delle alternative disponibili, apprendimento dei passaggi necessari per il cambiamento e implementazione, rappresentando un attrito considerevole. Inoltre, i bias comportamentali come lo status quo e l’avversione alla perdita portano gli utenti a mantenere le opzioni predefinite di Google.
La testimonianza di Antonio Rangel risuona direttamente con le rivelazioni dell’analisi interna di Google. Il documento rivela che l’impostazione della homepage del browser ha un impatto significativo sulla quota di mercato dei motori di ricerca e sul comportamento degli utenti. Specificamente, un’alta percentuale di utenti che hanno Google come homepage predefinita eseguono il 50% in più di ricerche su Google rispetto a coloro che non lo hanno.
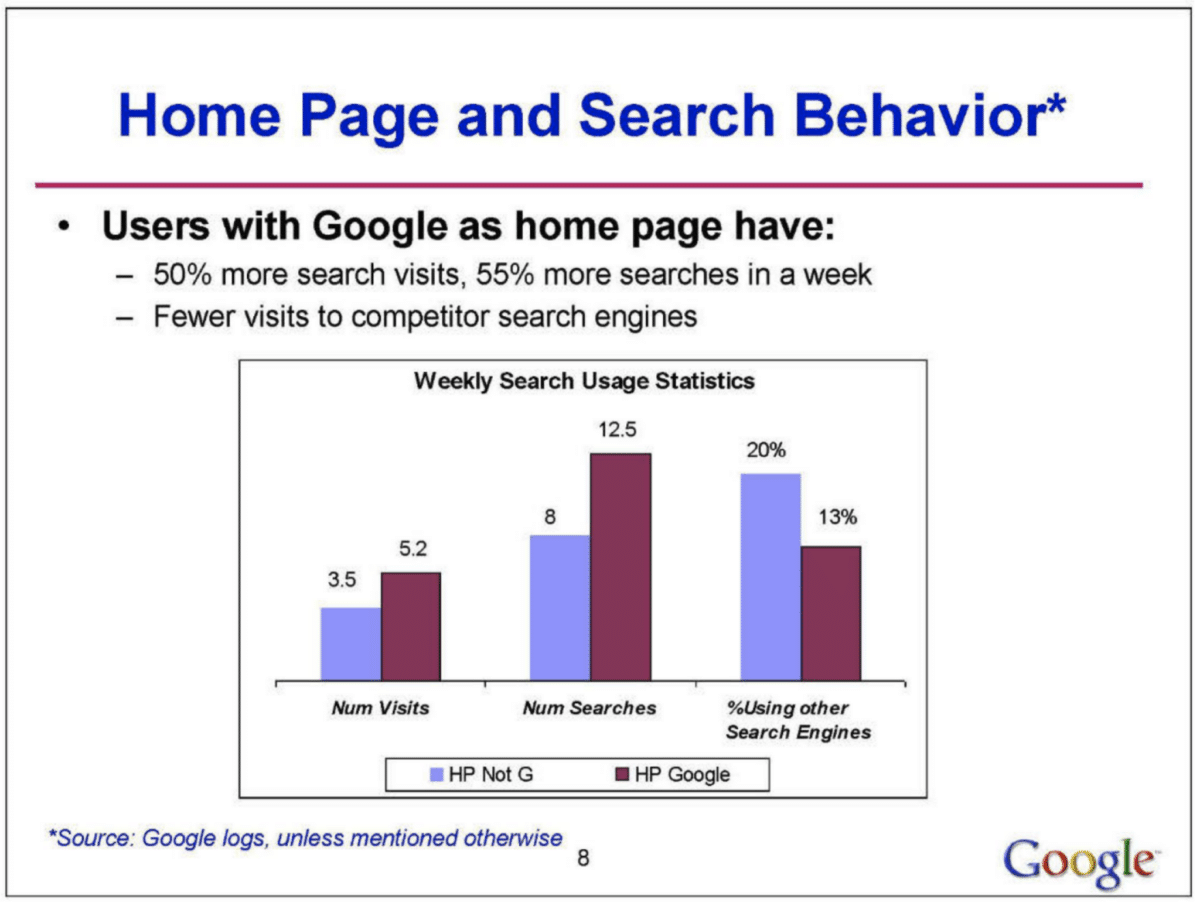
Questo suggerisce una forte correlazione tra la homepage predefinita e la preferenza del motore di ricerca. Inoltre, l’influenza di questa impostazione varia regionalmente, essendo più pronunciata in Europa, Medio Oriente, Africa e America Latina, e meno in Asia-Pacifico e Nord America. L’analisi mostra anche che Google è meno vulnerabile ai cambiamenti nell’impostazione della homepage rispetto a concorrenti come Yahoo e MSN, che potrebbero subire perdite significative se perdono questa impostazione.
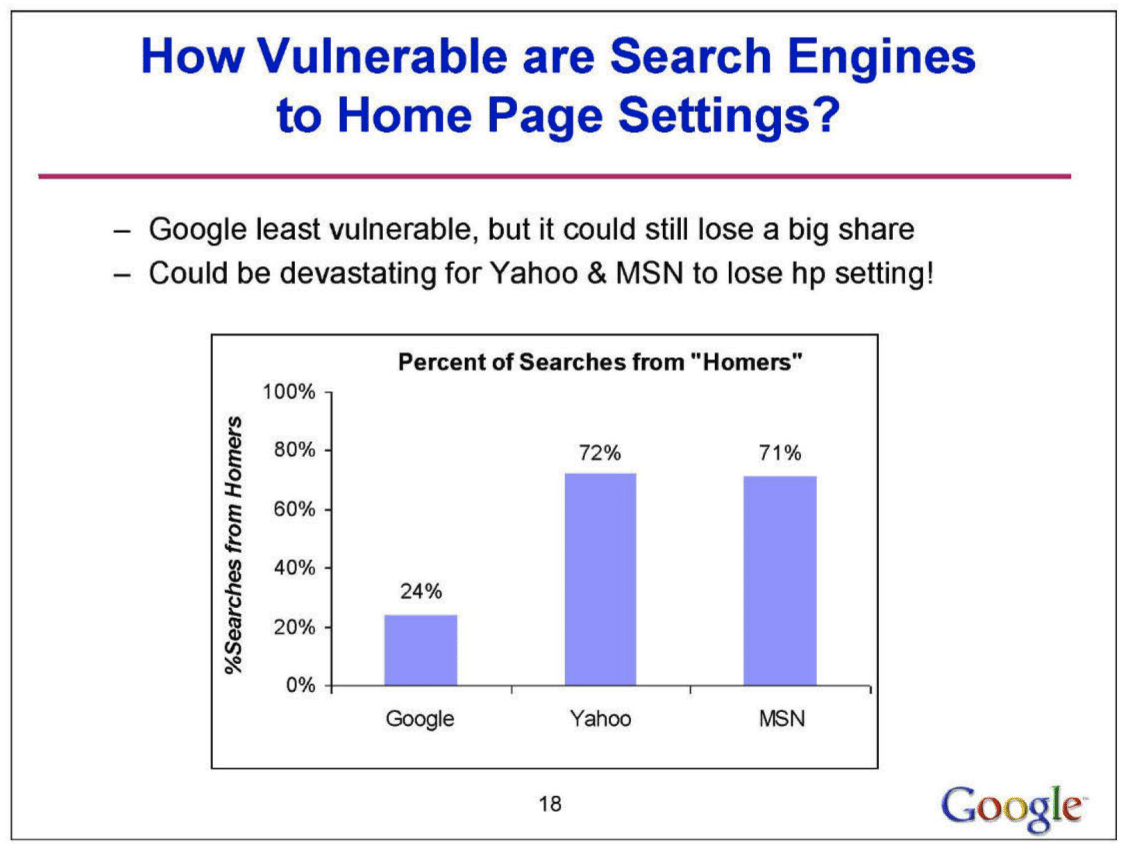
L’impostazione della homepage è identificata come uno strumento strategico chiave per Google, non solo per mantenere la sua quota di mercato, ma anche come potenziale vulnerabilità per i suoi concorrenti. Inoltre, evidenzia che la maggior parte degli utenti non sceglie attivamente un motore di ricerca, ma tende verso l’accesso predefinito fornito dall’impostazione della loro homepage. In termini economici, si stima un valore a vita incrementale di circa $3 per utente per Google quando impostato come homepage.

Conclusione
Dopo aver esplorato gli algoritmi e il funzionamento interno di Google, abbiamo visto il ruolo significativo che i clic degli utenti e i valutatori umani giocano nel posizionamento dei risultati di ricerca.
I clic, come indicatori diretti delle preferenze degli utenti, sono essenziali affinché Google possa continuamente aggiustare e migliorare la rilevanza e l’accuratezza delle sue risposte. Anche se a volte potrebbero volere il contrario quando i numeri non tornano…
Inoltre, i valutatori umani apportano un livello cruciale di valutazione e comprensione che, anche nell’era dell’intelligenza artificiale, rimane indispensabile. Personalmente, sono molto sorpreso a questo punto, sapendo che i valutatori erano importanti, ma non a tale estensione.
Questi due input combinati, il feedback automatico attraverso i clic e la supervisione umana, permettono a Google non solo di comprendere meglio le query di ricerca, ma anche di adattarsi a tendenze e necessità informative in cambiamento. Con l’avanzare dell’IA, sarà interessante vedere come Google continuerà a bilanciare questi elementi per migliorare e personalizzare l’esperienza di ricerca in un ecosistema in continua evoluzione con un focus sulla privacy.
D’altra parte, Chrome è molto più di un browser; è il componente critico della loro dominanza digitale. La sua sinergia con Google Search e la sua implementazione predefinita in molte aree impattano la dinamica di mercato e l’intero ambiente digitale. Vedremo come finirà il processo antitrust, ma sono stati senza pagare circa 10.000 milioni di euro in multe per abuso di posizione dominante per più di 10 anni.
Articoli correlati
Autore

Commenti |2
Lascia un commentoArticolo interessante ho un piccolo problema personale che vorrei risolvere in merito alla ricerca google: “fly inno di pace” – io sono l’autore del testo e della musica, ma ho dato per gratitudine la facolta ad un mio amico il maestro Nicola ####### di pubblicare una versione successiva all’origine dove lui ha collaborato suonando il pianoforte ed armonizzando.
La ricerca google evidenzia come prima voce il suo nome ed il mio non appare, vorrei semplicemente sapere se si può fare qualcosa per apparire anch’io.
Il pezzo non ha copyright volutamente, ma per giustizia morale vorrei almeno apparire con Nicola nel titolo anche se solo con il mio pseudonimo bembitenor, mi scuso se la mia richiesta non fosse pertinente con le sue ricerche. La ringrazio per la sua gentilezza in ogni caso lieto di averla conosciuta.
Cordiali saluti, Ziobembi.
Buongiorno Stefano, si può sicuramente fare qualcosa per dare maggiore evidenza e visibilità al suo nome. Mi contatti che ne parliamo (dalla pagina contatti di questo sito).
Cordiali saluti.