Introduzione
Nel decennio degli anni ’90, l’infrastruttura internet era ancora in fase di sviluppo e i web server disponevano di risorse limitate, soprattutto in termini di banda internet allocata per ciascun sito. Questa limitazione si traduceva spesso in una vulnerabilità significativa: i bot, programmi automatizzati progettati per navigare e indicizzare il web, potevano facilmente sovraccaricare un sito web con richieste eccessive, portandolo al crash o a prestazioni fortemente degradate. Questi incidenti non solo pregiudicavano l’esperienza degli utenti umani, ma potevano anche causare periodi di inattività critici per i siti web, con conseguenze dirette sulla visibilità e sull’affidabilità di un’entità online.
In risposta a questa problematica crescente e alla richiesta della comunità online, il 30 giugno del 1994 fu introdotto il “Robots Exclusion Protocol“. Questo protocollo forniva ai proprietari dei siti web uno strumento essenziale: la possibilità di comunicare direttamente con i bot attraverso un file di testo semplice, noto come “robots.txt”. Collocato nella radice del sito web, questo file permette ai gestori del sito di definire quali pagine o sezioni non dovrebbero essere sottoposte a crawling da parte dei bot, offrendo così una soluzione mirata per proteggere le risorse del server e migliorare l’esperienza utente.
La nascita del Robots Exclusion Protocol segnò un importante passo avanti nella gestione e ottimizzazione del traffico web, permettendo una più equa distribuzione delle risorse e un controllo più sofisticato sull’indicizzazione dei contenuti online. Questo strumento divenne rapidamente uno standard de facto, adottato dai principali motori di ricerca e dai crawler web, contribuendo significativamente alla formazione di un ecosistema digitale più stabile e accessibile.
Oltre a proteggere i siti dal scansioni indesiderate, il protocollo aprì nuove strade per la SEO (Search Engine Optimization), consentendo ai webmaster di influenzare il modo in cui i motori di ricerca indicizzavano i loro siti. Questo aspetto si rivelò fondamentale nell’era pre-Google, dove la visibilità su motori di ricerca come AltaVista, Lycos e Yahoo! era cruciale per il successo online. Grazie al file robots.txt, i proprietari di siti web potevano ora prevenire l’indicizzazione di pagine non ottimizzate o di contenuto duplicato, affinando la loro strategia SEO e migliorando il posizionamento nei risultati di ricerca.
Nel 2014 il file Robots.txt ha compiuto 20 anni, fu infatti implementato la prima volta nel 1994 ed ancora è largamente usato.
Prima di entrare nei dettagli degli errori più comuni da evitare è importante capire perché fu necessario sviluppare questo protocollo ed il suo standard.
#tutto aperto:
User-agent: *
Disallow:
#tutto chiuso:
User-agent: *
Disallow: /
#esempio
User-agent: *
Disallow: /foto
Allow: /foto/mamma.jpgRiducendo il traffico dei bot i vantaggi furono subito evidenti: i webmaster poterono offrire maggiore banda e velocità di risposta ai veri utenti, gli esseri umani, e ridurre il tempo di inattività del sito.
Recenti studi dimostrano che il traffico non-umano è costantemente in crescita e genera la maggior parte del traffico internet.

L’utilizzo della direttiva Disallow del Robots.txt permise di migliorare molti aspetti nella gestione di un sito web ma, l’altro lato della medaglia, portò anche diversi problemi ai webmaster. Ad esempio, qualsiasi buon motore di ricerca ha come fine (o mezzo?) quello di proporre i migliori risultati in risposta ad una query di ricerca, anche per risorse bloccate (accidentalmente o no) tramite Robots.txt.
Garantire la presentazione di risultati di alta qualità nei motori di ricerca rappresenta una sfida quando i contenuti rilevanti sono inaccessibili a causa delle restrizioni imposte dal file robots.txt. Questo file, infatti, è progettato per regolare il crawling dei contenuti da parte degli spider dei motori di ricerca, piuttosto che la loro indicizzazione. Di fronte a tale ostacolo, Google ha sviluppato un metodo ingegnoso per bypassare il problema: estrae e utilizza testi pertinenti da pagine liberamente accessibili per rappresentare gli URL bloccati nei risultati di ricerca (SERP). Questo processo si basa sulle relazioni di link interni e backlink. Per esempio, Google potrebbe selezionare l’anchor text più comune e pertinente usato nei link verso una risorsa bloccata per utilizzarlo come titolo di quella risorsa nei risultati di ricerca.
Questo approccio dimostra l’impegno di Google nel fornire agli utenti risultati di ricerca utili e accurati, anche quando le direttive del robots.txt limitano l’accesso diretto ai contenuti. Ecco un esempio pratico: supponiamo che un sito web abbia una sezione di documentazione tecnica bloccata dal crawling tramite il file robots.txt per evitare sovraccarico del server. Tuttavia, altri siti, come forum di discussione o blog tecnici, potrebbero linkare a questa documentazione. Google, analizzando questi link e i rispettivi anchor text, può dedurre l’importanza e il contesto della risorsa bloccata e, di conseguenza, decidere di includerla nei risultati di ricerca, utilizzando l’anchor text più frequente come titolo.
In aggiunta, è importante sottolineare che, nonostante questa strategia permetta a Google di migliorare la qualità dei suoi risultati di ricerca, i proprietari dei siti web dovrebbero usare il file robots.txt con cautela. Bloccare l’accesso a contenuti che si desidera siano indicizzati può avere effetti indesiderati sulla visibilità online. In questi casi, altre tecniche come l’uso di meta tag ‘noindex’ per le pagine specifiche, o la regolazione dell’accesso tramite autenticazione, possono offrire soluzioni più adeguate per gestire la visibilità dei contenuti senza compromettere la qualità o l’accessibilità dei risultati di ricerca.
Come risultato Google è in grado di mostrare in SERP URL bloccati con il Disallow nel Robots.txt.
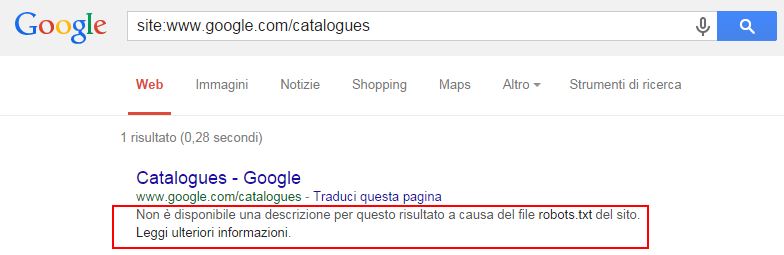
Un effetto collaterale nell’uso della direttiva Disallow nel Robots.txt è che il posizionamento per gli URL in Disallow è generalmente debole perché i bot non possono leggere il contenuto della pagina bloccata ed eventuali suoi aggiornamenti.
Cos’è il robots.txt
Robots.txt è un file di testo (.txt) creato dai webmaster per istruire gli spider (in genere robot dei motori di ricerca) ad eseguire la scansione delle pagine del loro sito web. Il file robots.txt indica se determinati user-agent (software di scansione web) possono o non possono eseguire la scansione di parti di un sito web.
Il file robots.txt viene utilizzato principalmente per evitare di sovraccaricare il sito di richieste o per tenere alla larga bot indesiderati. Le direttive espresse nel robots.txt non sono un meccanismo per tenere una pagina web fuori dall’indice Google. Per tenere una pagina web fuori da Google, dovresti utilizzare le direttive noindex oppure proteggere la tua pagina con una password.
A cosa serve
Un robots.txt indica, attraverso direttive, ai crawler dei motori di ricerca quali pagine o file il crawler può o non può richiedere al tuo sito. Il file robots.txt viene utilizzato principalmente per gestire il traffico del crawler sul sito e di solito per escludere un o più URL dalla scansione.
L’URL può essere di una pagina web, un file media o risorse varie.
- Pagine web: il file robots.txt può essere utilizzato per gestire il traffico di scansione per le pagine web (HTML, PDF o altri formati non multimediali che Google può leggere). Mettere in disallow alcune pagine può essere utile se ritieni che il tuo server sarà saturato da richieste dei crawler o per evitare la scansione su pagine non importanti o pagine duplicate sul tuo sito. Non dovresti utilizzare robots.txt come mezzo per nascondere le tue pagine web dai risultati di ricerca di Google. Questo perché, se altre pagine puntano alla tua pagina con testo descrittivo, la tua pagina potrebbe comunque essere indicizzata senza che Googlebot possa visitare la pagina. Se desideri escludere la tua pagina dai risultati di ricerca, utilizza un altro metodo come la protezione tramite password o una direttiva noindex. Se la tua pagina web è bloccata con un file robots.txt, può ancora apparire nei risultati di ricerca, ma il risultato della ricerca non avrà una descrizione.
- File media: utilizza robots.txt per gestire le scansioni e anche per impedire la visualizzazione di file immagine, video e audio nei risultati di ricerca di Google. Tieni presente che ciò non impedirà ad altre pagine o utenti di linkare al tuo file immagine/video/audio.
- Risorse: puoi utilizzare robots.txt per bloccare file di risorse come immagini, script o fogli di stile non importanti, se ritieni che le pagine HTML caricate senza queste risorse non saranno influenzate in modo significativo dalla perdita. Tuttavia, se l’assenza di queste risorse rende la pagina più difficile da comprendere per i crawler dei motori di ricerca, non dovresti bloccarle, altrimenti Google & Co non faranno un buon lavoro nell’analizzare le pagine che dipendono da tali risorse.
Come funziona
I motori di ricerca eseguono due attività principali:
- Scansione del web per scoprire i contenuti.
- Indicizzazione di quel contenuto in modo che possa essere offerto agli utenti che cercano informazioni.
Per eseguire la scansione dei siti, i motori di ricerca seguono i collegamenti per spostarsi da un sito all’altro eseguendo la scansione di miliardi di collegamenti e siti web. Questa attività viene definita “crawling”.
Quando un crawler vuole scansionare un sito web, la prima cosa che fa è cercare il file robots.txt. Se ne trova uno, il crawler leggerà il file prima di continuare la scansione. Poiché il file robots.txt contiene informazioni su come il motore di ricerca deve eseguire la scansione, le informazioni trovate indicheranno ulteriori azioni del crawler su questo particolare sito. Se il file robots.txt non contiene alcuna direttiva che impedisce l’attività di uno user-agent (o se il sito non ha un file robots.txt), lo spider procederà alla scansione di altre informazioni sul sito.
Regole importanti
- Per essere trovato, un file robots.txt deve essere inserito nella directory di primo livello di un sito web, ovvero nella root del web server: esempio.com/robots.txt
- robots.txt è case sensitive, ovvero distingue tra maiuscole e minuscole: il file deve essere denominato con lettere minuscole “robots.txt” (non Robots.txt, robots.TXT o altro).
- Alcuni user-agent potrebbero scegliere di ignorare il tuo file robots.txt. Questo è particolarmente comune con i crawler spam, spider malevoli o gli scraper di indirizzi e-mail.
- Il file robots.txt è disponibile pubblicamente: aggiungi /robots.txt alla fine di qualsiasi dominio principale per vedere le direttive di quel sito web (se quel sito ha un file robots.txt). Ciò significa che chiunque può vedere quali pagine si desidera o non si desidera sottoporre a scansione, quindi non utilizzarle per nascondere informazioni sensibili.
- Ogni sottodominio su un dominio principale utilizza file robots.txt separati. Ciò significa che sia blog.esempio.com che www.esempio.com dovrebbero avere i propri file robots.txt (su blog.esempio.com/robots.txt e www.esempio.com/robots.txt).
- In genere è buona norma indicare la posizione di eventuali Sitemap associate al dominio nella parte inferiore del file robots.txt. Ecco un esempio:
User-agent: Zeus
Disallow: /
Sitemap: https://www.evemilano.com/wp-sitemap.xmlSintassi
La sintassi del file robots.txt può essere considerata la “lingua” dei file robots.txt. Ci sono cinque termini comuni che probabilmente incontrerai in un file robots:
- User-agent: il crawler web specifico a cui stai fornendo le istruzioni di scansione (di solito un motore di ricerca). Un elenco della maggior parte dei programmi utente può essere trovato qui.
- Disallow: il comando utilizzato per indicare a un user-agent di non eseguire la scansione di un determinato URL. È consentita una sola riga “Disallow:” per ogni URL.
- Allow (applicabile solo per Googlebot): il comando per indicare a Googlebot che può accedere a una pagina o una sottocartella anche se la sua pagina principale o la sua sottocartella potrebbero non essere consentite.
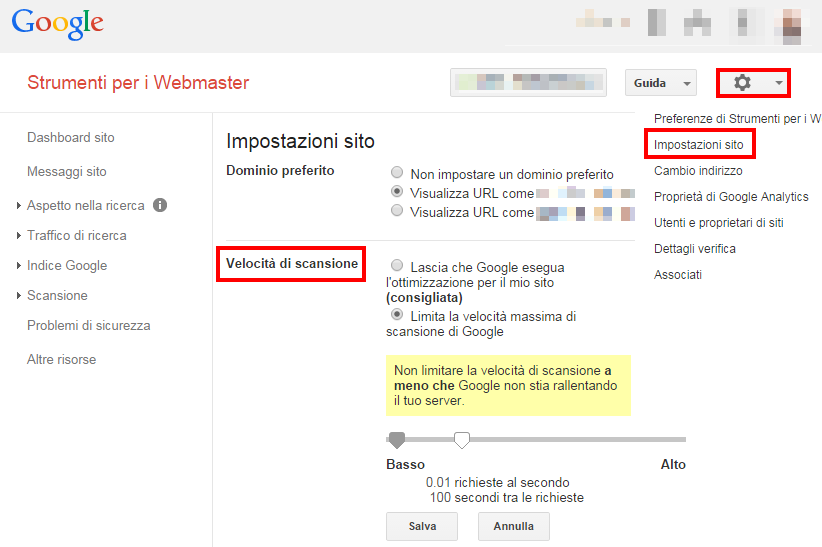
- Crawl-delay (obsoleto per Googlebot): questa direttiva indica quanti secondi deve attendere un crawler tra una richiesta e l’altra, prima di caricare ed eseguire la scansione del contenuto della pagina. Tieni presente che Googlebot non riconosce questo comando. Googlebot regola in autonomia la propria velocità di scansione in base ai tempi di risposta del web server. Googlebot tende ad aumentare la velocità di scansione se i tempi di risposta del web server diminuiscono. Viceversa rallenta la scansione all’aumentare dei tempi di risposta. In passato questo parametro poteva essere impostato in Google Search Console.
- Sitemap: direttiva utilizzata per indicare ai bot dei motori di ricerca la posizione della sitemap.xml associata al sotto dominio. Tieni presente che questo comando è supportato solo da Google, Ask, Bing e Yahoo.
Pattern-matching: definire i percorsi per gruppi di URL
Quando si tratta di bloccare o consentire la scansione di gruppi di URL, i file robots.txt possono diventare piuttosto complessi in quanto consentono l’uso di alcune espressioni regolari per coprire una gamma di possibili URL.
Google e Bing rispettano entrambi due espressioni regolari che possono essere utilizzate per identificare pagine o sottocartelle che un SEO vuole escludere. Questi due caratteri sono l’asterisco (*) e il segno del dollaro ($).
- * è un carattere jolly che rappresenta qualsiasi sequenza di caratteri
- $ corrisponde alla fine dell’URL
Di seguito vediamo un elenco di possibili sintassi ed esempi di corrispondenza dei modelli e priorità.
Per quanto riguarda URL parametrizzati, è possibile usare il disallow escludere dalla scansione tutti gli URL che contengono un determinato parametro. Per maggiori informazioni ti consiglio di leggere la guida dedicata: Disallow del robots.txt sui parametri degli URL.
Esempi utili
Di seguito alcune regole con esempi utili per i file robots.txt.
Non consentire la scansione dell’intero sito web. Ricorda che, in alcune situazioni, gli URL del sito web potrebbero essere comunque indicizzati, anche se non sono stati sottoposti a scansione. Nota: questa regola non viene applicata ai vari crawler AdsBot, i cui nomi devono essere indicati espressamente.
User-agent: *
Disallow: /Non consentire la scansione di una directory e dei relativi contenuti facendo seguire il nome della directory da una barra. Ricorda che non devi utilizzare il file robots.txt per bloccare l’accesso ai contenuti privati, bensì l’autenticazione corretta. Gli URL non consentiti dal file robots.txt possono essere comunque indicizzati senza essere sottoposti a scansione e il file robots.txt può essere visualizzato da chiunque, comunicando eventualmente il percorso dei contenuti privati.
User-agent: *
Disallow: /calendar/
Disallow: /junk/Consentire l’accesso a un singolo crawler:
User-agent: Googlebot-news
Allow: /
User-agent: *
Disallow: /Consentire l’accesso a tutti i crawler tranne uno:
User-agent: Unnecessarybot
Disallow: / User-agent: * Allow: /Non consentire la scansione di una singola pagina web indicando la pagina dopo la barra:
User-agent: *
Disallow: /private_file.htmlBloccare un’immagine specifica su Google Immagini:
User-agent: Googlebot-Image
Disallow: /images/dogs.jpgBloccare tutte le immagini del tuo sito su Google Immagini:
User-agent: Googlebot-Image
Disallow: /Non consentire la scansione di un tipo di file specifico:
User-agent: Googlebot
Disallow: /*.gif$Non consentire la scansione dell’intero sito, ma mostrare gli annunci AdSense nelle pagine; non consentire l’accesso a tutti i web crawler diversi da Mediapartners-Google. Questa implementazione consente di non visualizzare le tue pagine nei risultati di ricerca, ma il web crawler Mediapartners-Google potrà ancora analizzarle per stabilire quali annunci mostrare ai visitatori del tuo sito.
User-agent: *
Disallow: /
User-agent: Mediapartners-Google Allow: /Usa il carattere $ per applicare la regola agli URL che terminano con una stringa specifica. Ad esempio, questo codice blocca tutti gli URL che terminano con xls.
User-agent: Googlebot
Disallow: /*.xls$Migliori pratiche SEO
Assicurati di non bloccare alcun contenuto o sezione del tuo sito web che desideri sottoporre a scansione.
I link alle pagine bloccate da robots.txt non verranno seguiti. Ciò significa:
- A meno che non siano collegate anche da altre pagine accessibili ai motori di ricerca (ad esempio pagine non bloccate tramite robots.txt, meta robots o altro), le risorse collegate non verranno sottoposte a scansione e potrebbero non essere indicizzate.
- Non è possibile trasferire PageRank dalla pagina bloccata alla destinazione del collegamento. Se disponi di pagine a cui desideri trasferire PageRank, utilizza un meccanismo di blocco diverso da robots.txt.
Non utilizzare il robots.txt per impedire la visualizzazione di dati sensibili (come le informazioni degli utenti privati) nei risultati SERP. Poiché altre pagine possono collegarsi direttamente alla pagina contenente informazioni private (aggirando così le direttive robots.txt sul tuo dominio principale o sulla tua home page), potrebbe comunque essere indicizzata. Se desideri bloccare la tua pagina dai risultati di ricerca, utilizza un metodo diverso come la protezione tramite password o la meta direttiva noindex.
Alcuni motori di ricerca hanno più user-agent. Ad esempio, Google utilizza Googlebot-Mobile per la ricerca organica e Googlebot-Image per la ricerca di immagini. La maggior parte degli interpreti dello stesso motore di ricerca segue le stesse regole, quindi non è necessario specificare direttive per ciascuno dei molteplici crawler di un motore di ricerca, ma avere la possibilità di farlo ti consente di mettere a punto il modo in cui i contenuti del tuo sito vengono scansionati.
Un motore di ricerca memorizzerà nella cache i contenuti del file robots.txt, ma di solito aggiorna i contenuti nella cache almeno una volta al giorno. Se modifichi il file e desideri aggiornarlo più rapidamente di quanto si stia verificando, puoi inviare il tuo URL robots.txt a Google con Google Search Console.
Aspetti legali del REP (Robot Exclusion Protocol)
Natura non vincolante del robots.txt: Il protocollo Robots Exclusion Standard, che guida l’uso del file robots.txt, è uno standard de facto nel web design e nella gestione dei motori di ricerca. Tuttavia, non esiste un quadro legale specifico che obbliga legalmente i crawler a rispettare le direttive del robots.txt. Ciò significa che, sebbene i motori di ricerca rispettabili e i crawler benevoli seguano queste direttive come buona pratica, non ci sono conseguenze legali dirette per coloro che scelgono di ignorarle.
Robots.txt vs Meta Robots vs X-Robots tag
Qual è la differenza tra questi tre tipi di istruzioni? Ne ho parlato in modo approfondito nella guida sul meta tag noindex.
Per farla breve… Prima di tutto, robots.txt è un vero file di testo, mentre meta e x-robots sono meta direttive. Al di là di quello che sono in realtà, i tre hanno tutte funzioni diverse.
- Robots.txt determina il comportamento di scansione del sito o dell’intera directory.
- Meta robots e x-robots possono dettare il comportamento di indicizzazione a livello di singola pagina (o elemento di pagina).
Domande e risposte
Cosa significa “blocked by robots.txt”?
Blocked by Robots.txt è uno status mostrato da Google Search Console che indica che gli URL richiesti da Googlebot sono stati bloccati dal tuo robots.txt. Puoi leggere la guida dedicata Cosa significa Blocked by robots.txt.
Un URL in disallow può passare PageRank?
No. John Mueller lo ha affermato durante un video di English Google Webmaster Central office -hours hangout. Un URL che non può essere scansionato da Googlebot non può a sua volta passare PageRank ad altre pagine.
Il Robots.txt è necessario?
La maggior parte dei siti web e blog non hanno bisogno di un robots.txt. Nei siti semplici senza filtri o query string, Googlebot può trovare e indicizzare le pagine importanti del tuo sito in autonomia e non indicizzerà invece le pagine che non sono importanti o che sono duplicate di altre pagine.
Nel caso di accessi indesiderati da parte di bot che non interessano, oppure al crescere della complessità del sito, della struttura URL ed eventuali query string, può essere necessario abilitare qualche direttiva nel obots.txt.
Posso ignorare il robots.txt?
Hai uno spider e ti stai chiedendo cosa potrebbe succedere se non dovesse rispettare le direttive dei robots.txt dei siti web che scansiona? Lo standard di esclusione dei robot è puramente consultivo, dipende completamente da te se rispettarlo o meno. In linea di massima se non stai facendo qualcosa di brutto è probabile che non accadrà nulla se scegli di ignorarlo.
Come verificare il robots.txt?
Google Search Console ha uno strumento per testare il robots.txt dei siti che hai registrato, lo trovi qui.
- Apri lo strumento.
- Seleziona la tua proprietà da testare.
- Digita l’URL di una pagina del tuo sito nella casella di testo in fondo alla pagina.
- Seleziona lo user-agent che desideri simulare nell’elenco a discesa a destra della casella di testo.
- Clicca sul pulsante TEST per testare l’accesso.
L’esito positivo mostra il pulsante ALLOWED in verde, mentre l’esito negativo BLOCKED in rosso. Inoltre, nel caso di blocco lo strumento evidenzia la direttiva del robots.txt che ha impedito la scansione, così potrai correggerla o rimuoverla.
Dove si trova il file txt del robot?
I robot. txt deve trovarsi nella radice dell’host del sito web a cui si applica. Ad esempio, per controllare la scansione su tutti gli URL sotto http://www.esempio.com/, il file robots.txt deve trovarsi qui http://www.esempio.com/robots.txt.
Come si linka la mappa del sito dal robots.txt?
Aggiungere il link alla sitemap.xml è molto semplice, ti basta un client FTP come Filezilla per scaricare e ricaricare il file robots.txt, ed un editor di testo per modificarlo.
- Accedi via FTP al web server.
- Scarica il file robots.txt.
- Apri il file con un editor di testo.
- Aggiungi alla fine del file robots.txt l’URL assoluto della sitemap.xml preceduta da “Sitemap: “.
- Salva il file.
- Carica il file robots.txt sul web server.
Ad esempio:
User-agent: Zeus
Disallow: /
Sitemap: https://www.evemilano.com/wp-sitemap.xmlCome correggere un URL bloccato dal robots.txt?
Con il tester del file robots.txt in Google Search Console individua la direttiva che blocca la scansione dell’URL o detta risorsa che hai testato. Ora puoi modificarla o cancellarla in modo da lasciare libero l’accesso agli spider.
Google rispetta il Noindex nel robots.txt?
No. Google ha annunciato ufficialmente che Googlebot non obbedirà più alla direttiva noindex espressa nel robots.txt:
In the interest of maintaining a healthy ecosystem and preparing for potential future open source releases, we're retiring all code that handles unsupported and unpublished rules (such as noindex) on September 1, 2019. Fonte: developers.google.com
Come faccio a bloccare Google con il robots.txt?
Con il seguente esempio di robots.txt diciamo all’user-agent Googlebot che non può scansionare la cartella /docs/
User-agent: Googlebot
Disallow: /docs/Come faccio a bloccare un crawler specifico nel robots txt?
Se vuoi impedire ad uno specifico o più bot di eseguire la scansione su una cartella del tuo sito, puoi inserire il suo user-agent nel robots.txt, oppure uno per riga seguito dalla direttiva Disallow:
User-agent: Yandex
User-agent: YandexTurbo
User-agent: YandexBot
User-agent: Baiduspider
Disallow: /Il Robots.txt può essere una vulnerabilità?
La presenza del file robots.txt non presenta di per sé alcun tipo di vulnerabilità di sicurezza per il tuo sito web. Tuttavia, viene spesso utilizzato per identificare aree riservate o private dei contenuti di un sito.
Qual è il limite di grandezza del file robots.txt?
Un file robots.txt troppo lungo viene tagliato essenzialmente al superamento della soglia, il contenuto che si trova dopo la dimensione massima del file viene ignorato.
Google attualmente applica un limite di dimensione di 500 kibibyte (KiB). Per ridurre le dimensioni dei robots.txt devi essenzialmente scrivere meno direttive. Puoi aiutarti, ad esempio, spostando tutto il materiale da escludere in una cartella dedicata.
Come faccio a caricare il robots.txt su WordPress?
WordPress non crea un file robots.txt. Per farlo puoi usare un client FTP, creare il file txt e caricarlo nella root. Oppure puoi usare un plugin per la SEO, come ad esempio Yoast o altri equivalenti.
Come rimuovo robots.txt da un sito web?
Il file robots.txt si trova nella directory principale del tuo hosting web, negli hosting condivisi potresti trovarlo in /public_html/.
Dovresti essere in grado di modificare o eliminare questo file usando un client FTP ed un editor di testo.
Alcuni errori che ho trovato nei Robots.txt
File Robots.txt vuoti
Google consiglia* di usare il file Robots.txt soltanto se all’interno del sito ci sono sezioni e/o contenuti che non si vogliono far indicizzare dal motore di ricerca. Se intendi far indicizzare qualsiasi cosa presente nel sito non è necessario usare il file robots.txt, nemmeno se lasciato vuoto. La maggior parte dei problemi può essere risolto senza l’uso del file Robots.txt e del Disallow. Pensa al file Robots.txt come l’ultima spiaggia per non far indicizzare una risorsa. Prima di implementare un file Robots.txt sarebbe meglio considerare, ad esempio, lo status code 410, il tag meta noindex e il rel canonical.
Non bloccare le risorse 24 ore prima
Nel 2000 Google iniziò a scaricare i file Robots.txt una volta al giorno, prima del 2000 invece Google controllava i file Robots.txt una volta a settimana. Poteva capitare quindi che alcuni URL in Disallow venivano scaricati ed indicizzati durante quel gap temporale, tra una lettura del Robots.txt e la successiva.
Oggi Google controlla solitamente i file Robots.txt ogni 24 ore non è una garanzia. Google potrebbe aumentare o diminuire la durata della cache basandosi sull’header HTTP chiamato “Cache-Control”, per maggiori informazioni puoi leggere questa guida: Direttive di Cache-Control, cosa sono e come funzionano. Gli altri motori di ricerca potrebbero impiegare più di 24 ore per verificare i file Robots.txt, in ogni caso è possibile che i contenuti in Disallow vengano scaricati durante un check e l’altro nelle 24 ore.
Mettere un URL in disallow tramite il Robots.txt per evitare che una risorsa appaia nei risultati di ricerca
Bloccare un URL con il Robots.txt non impedisce alla risorsa di essere indicizzata e quindi inserita nei risultati di ricerca. Come avevo spiegato in questo articolo sul funzionamento di Google, il crawling e l’indexing sono due processi diversi ed indipendenti. URL in Disallow nel Robots.txt vengono indicizzati dai motori di ricerca se sono linkati da pagine che non sono in Disallow nel Robots.txt. Google è quindi capace di associare il testo proveniente da altre risorse con l’URL in Disallow e mostrare in serp l’URL in Disallow. Questo processo è svolto senza bisogno di fare crawling della pagina in Disallow via Robots.txt.
Per evitare che una risorsa finisca nei risultati di ricerca l’URL deve necessariamente essere scaricabile dai bot per dargli modo di leggerlo, non deve essere messo in disallow nel Robots.txt. Una volta che l’URL è scaricabile dai bot si possono utilizzare diversi metodi per impedirne l’indicizzazione da Google, come ad esempio il tag meta noindex, una password di protezione al contenuto, oppure il tag X-Robots nell’intestazione HTTP.
Usare il Disallow nel Robots.txt per rimuovere dai risultati di ricerca l’URL di pagine non più esistenti
Come detto sopra, il Robots.txt non rimuove il contenuto da Google. Google non può immaginare che la pagina non sia più esistente soltanto perchè è stato impedito l’accesso dei suoi bot verso quella pagina.
Usando il Disallow nel Robots.txt per pagine che sono state indicizzate ma che sul sito non esistono più, si impedisce di fatto a Google di scoprire che quella pagina è stata effettivamente rimossa perchè non ne potrà conoscere lo status code HTTP. Come risultato questi URL saranno trattati come qualsiasi altro URL escluso via Robots.txt e saranno quindi inclusi nei risultati di ricerca per del tempo indefinito.
Il metodo più pratico e veloce per richiedere a Google l’esclusione dai dai risultati di ricerca di una pagina non più esistente è quella di permettere a Googlebot di visitare/scansionare/scaricare la pagina, solo in questo modo potrà individuare lo status code 404/410 e di conseguenza rimuoverla dai risultati di ricerca. Fino a quando Googlebot non ha la certezza che la pagina sia stata effettivamente rimossa quell’URL continuerà ad essere presente in SERP.
Implementare lo status code 410 su tutte le risorse rimosse è il metodo più veloce per de-indicizzare pagine non più esistenti.
Mettere in Disallow nel Robots.txt URL con redirezioni attive
Il Disallow su URL con redirezioni (status code 301 o 302 o meta refresh) verso altri URL impedisce ai motori di ricerca di individuare il redirect. Dato che il Robots.txt non rimuove contenuti dall’indice dei motori di ricerca, disabilitare un URL con redirezione generalmente causa ai motori di ricerca l’errore di mostrare in SERP la risorsa indicizzata ma con URL errato.
Per indicare a Google che una risorsa ha cambiato URL è necessario permettere ai bot l’accesso al vecchio URL così che possano individuare lo status code 3xx e associare il contenuto al nuovo URL.
Usare il Disallow nel Robots.txt su pagine che hanno il meta tag noindex
Impedire l’accesso ai bot su pagine con meta tag noindex impedisce di fatto ai bot l’individuazione del tag noindex rendendolo inefficace. Può succedere che le pagine con meta tag noindex vengano mostrate nei risultati di ricerca, perchè come detto sopra, il bot non può individuare il meta tag noindex.
Se non vuoi che una pagina appaia nei risultati di ricerca devi implementare il meta tag noindex e lasciare libero accesso ai bot su quella pagina.
Alcuni siti cercano di comunicare con Google attraverso i commenti nel file Robots.txt
Per quanto figo, è solo un esercizio di stile. Googlebot essenzialmente ignora i commenti nel file Robots.txt

Usare il Disallow nel Robots.txt su pagine con il rel=canonical oppure il meta tag nofollow e la X-Robots-Tags
Bloccare un URL come abbiamo visto impedisce ai bot di leggerne il contenuto, compresi i tag inseriti e l’intestazione HTTP, di conseguenza nessuno di questi comandi verrà considerato.
Per permettere a Google di considerare gli status code od i meta tag la pagina non deve essere bloccata nel Robots.txt.
Bloccare risorse confidenziali con il Disallow nel Robots.txt
Qualsiasi utente con un minimo di esperienza sull’utilizzo del file Robots.txt è in grado di accederci per leggerlo perchè il robots.txt è (e deve essere) una risorsa pubblica e accessibile. Vedi google.com/robots.txt e apple.com/robots.txt.
Il file Robots.txt non è stato creato per nascondere informazioni, le sue funzioni sono ben diverse come abbiamo visto.
Un modo per nascondere una risorsa confidenziale ai bot è quello di fornire il contenuto al client soltanto dopo aver richiesto le credenziali, utente e password ad esempio.
Robots.txt immensi
Robots.txt troppo complessi possono facilmente generare problemi al webmaster e a Google. Non so quanti siti al mondo possano aver bisogno di un Robots.txt così. Lo standard limita la grandezza del file Robots.txt a 500 kb, il testo in eccesso viene ignorato da Google.
I file Robots.txt dovrebbero essere brevi e molto chiari.
Robots.txt senza status code
Se Google prova ad accedere al file Robots.txt ma non riceve alcuno status code HTTP (200 o 404) riproverà a scaricarlo più tardi finchè non otterrà uno status code. Per questo motivo è importante assicurarsi che il webserver risponda sempre a richieste del file robots.txt con status code HTTP 200, 403 o 404.
403 Robots.txt
Restituendo uno status code HTTP 403 per richieste al Robots.txt indica che il file non esiste. Come risultato Google può ritenere di aver libero accesso a qualsiasi risorsa ospitata sul web server. Se il tuo Robots.txt restituisce uno status code HTTP 403 ed è una cosa non intenzionale, ti basta cambiare lo status code in 200 oppure 404.
[Regola obsoleta] Sovrascrivere le direttive User-Agent
Quando direttive generiche vengono esplicitate prima di direttive specifiche. È importante notare che i motori di ricerca gestiscono i file robots.txt in modo diverso. Per impostazione predefinita, la prima direttiva corrispondente vince sempre. Tranne Google e Bing, gli altri bot seguono l’ordinamento delle regole del Robots.txt, Consiglio quindi di esplicitare le regole più specifiche prima delle regole più generiche. Vediamo questo esempio:
User-agent: *
Disallow: /chi-siamo/
Allow: /chi-siamo/azienda/Nell’esempio appena mostrato nessun bot, tranne Googlebot e Bingbot, potrebbe accedere alla pagina /chi-siamo/azienda/ dato che la prima regola impone un blocco. Googlebot e Bingbot invece seguono la regola della specificità: tra Disallow e Allow vince Allow se la direttiva è più lunga (quindi la regola più specifica). Per questo motivo è molto importante testare il robots.txt in Google Search Console. La versione corretta sarebbe:
User-agent: *
Allow: /chi-siamo/azienda/
Disallow: /chi-siamo/Robots.txt case sensitivity
L’URL del file Robots.txt e gli URL scritti all’interno del Robots.txt sono case-sensitive ovvero, il sistema fa differenza tra una lettera maiuscola e una minuscola. Per questo motivo potresti avere problemi a chiamare il tuo file ROBOTS.TXT oppure ad indicare al suo interno URL scritti mischiando maiuscolo e minuscolo.
Rimuovere il file robots.txt dai risultati di ricerca
Questo è un caso raro ma a qualcuno potrebbe interessare rimuovere il file robots.txt dai risultati di Google. Per prevenire l’indicizzazione del file robots.txt e quindi la sua inclusione nei risultati di ricerca i webmaster possono usare l’intestazione HTTP con direttiva X-Robots-Tag noindex.
Importare Robots.txt totalmente chiusi
Quando si sviluppa un nuovo sito web, sia in locale ma soprattutto online, il file Robots.txt viene solitamente (ho detto solitamente e sto esagerando!) chiuso con User-agent: * Disallow: /. Nel momento in cui si passa dalla fase di stage a quella live bisogna ricordarsi di rivedere il Robots.txt altrimenti il traffico organico sarà soltanto un miraggio.
Robots.txt Crawl-delay
Alcuni siti includono nel file Robots.txt la direttiva “Crawl delay” (di cui avevo parlato in questo articolo) ma Google la ignora. Per controllare la frequenza di crawling di Googlebot una volta era necessario usare le specifiche impostazioni in Google Search Console, oggi non è più possibile dato che Googlebot si regola in autonomia.
[WordPress] Bloccare la cartella wp-content
Inibire l’accesso alla cartella wp-content potrebbe impedire la corretta indicizzazione della pagina. wp-content infatti contiene molto spesso CSS, JS e altri file funzionali al tema utilizzato. Alcuni plugin e temi utilizzano JS presenti in wp-includes e da qui un altro errore che si andrebbe a commettere utilizzando un Robots.txt troppo chiuso.
Considerazioni finali
Il file Robots.txt è uno strumento che andrebbe utilizzato quando non esistono alternative migliori dal punto di vista SEO, oppure quando le alternative non sono praticabili a causa di limitazioni tecniche. Come abbiamo visto esistono metodi più efficaci che in alcuni casi è consigliabile usare in sostituzione del “Disallow” nel file Robots.txt.
Articoli correlati
Autore

Commenti |9
Lascia un commentoCiao Giovanni,
grazie per l’ottimo post.
Ho notato che inserendo i comandi seguenti nel robots.txt di un sito web sviluppato con WordPress
Disallow: /wp-
Disallow: /wp-includes/
Disallow: /wp-content/
Allow: /wp-content/uploads/
il portale risulta non ottimizzato per i dispositivi mobile (test eseguito mediante tool di Google).
Mi chiedevo, quindi, se sia corretto inserire nel robots.txt tali comandi.
Cosa ne pensi?
Grazie in anticipo.
Ciao Elena grazie per il commento! Attenzione a bloccare l’accesso ad eventuali file CSS, immagini e Javascript che i browser (e Google) usano per renderizzare la pagina. Meglio un robots.txt totalmente aperto di uno chiuso senza criterio :) Ti consiglio di rieseguire il test con il robots.txt svuotato ed eventualmente aggiungere volta per volta delle limitazioni eseguendo sempre il test con Fetch as Google in Google Search Console.
A presto!
Grazie mille Giovanni.
Gentilissimo e utilissimo come sempre.
Buona giornata.
Ciao Giovanni,
come sempre grazie per le tue utili informazioni.
Solo questa parte mi lascia però dubbioso
***
Rimuovere il file robots.txt dai risultati di ricerca – per prevenire l’indicizzazione del file robots.txt e quindi la sua inclusione nei risultati di ricerca, i webmaster possono mettere in Disallow il Robots.txt attraverso lo stesso file robots.txt e poi rimuovendolo da Google Search Console. Un altro metodo è quello di usare X-Robots-Tag noindex nell’intestazione HTTP del file robots.txt.
***
Una volta avevo per errore mandato in disallow il file robot, con tutto il sito, e (giustamente) Google non percepiva più la modifica per riparare all’errore.
È stata una fatica fargli capire che il robots era cambiato e che quindi poteva tornare a leggerlo (e con lui tutto il resto del sito).
Io non lo escluderei mai per sicurezza
Ciao Filippo, grazie per avermi fatto notare un errore grossolano. In effetti quanto era scritto non aveva senso: se metti in disallow un file, Google non lo legge e quindi non riceve le direttive in esso contenute.
Ho corretto il testo inserendo che (è un caso molto particolare) l’unica soluzione ragionevole è usare l’intestazione HTTP con la direttiva X-Robots-Tag.
Grazie ancora, spero che non troverai altre inesattezze su questo blog :D
La direttiva “tutto aperto” che si ottiene con:
User-agent: *
Disallow:
Sitemap: …/sitemap.xml
Si può ottenere anche con:
User-agent: *
Sitemap: …/sitemap.xml
Oppure crea dei problemi un robots.txt scritto così? Non mi sono mai posto il problema e mi è venuto un serio dubbio.
Ciao Luca, la sintassi giusta è la prima che hai scritto. La seconda non è menzionata nella documentazione ufficiale – http://www.robotstxt.org/robotstxt.html. Nella definizione del formato puoi leggere
The record starts with one or more User-agent lines, followed by one or more Disallow lines, as detailed below. Unrecognised headers are ignoredQuindi devi usarli entrambi, in base allo standard un header non riconosciuto viene ignorato, poi ogni motore di ricerca reagirà a modo suo. A presto!
Altre info:
http://www.robotstxt.org/norobots-rfc.txt
https://www.w3.org/TR/html4/appendix/notes.html#h-B.4.1.1
https://en.wikipedia.org/wiki/Robots_exclusion_standard
Ciao Giovanni,
Non mi è tanto chiara questa parte: “Sovrascrivere le direttive User-Agent”.
Cosa intendi? Potresti essere più specifico? Grazie
Ciao Chris, grazie del commento. È una considerazione oramai obsoleta ma ho aggiornato il testo per renderlo più comprensibile. Grazie per la segnalazione.