Le espressioni regolari, conosciute anche come RegEx, sono uno strumento essenziale per chi lavora nel mondo dello sviluppo web e dell’analisi dei dati. Queste potenti sequenze di caratteri permettono di identificare, filtrare e manipolare stringhe di testo in modo estremamente preciso ed efficiente.
Le RegEx sono diventate indispensabili per gestire molte operazioni comuni e complesse nel mondo digitale di oggi. Che tu sia un webmaster, uno sviluppatore, o un consulente SEO, padroneggiare le espressioni regolari può migliorare significativamente la tua produttività e la qualità del tuo lavoro.
Perché le RegEx sono Importanti?
Le RegEx sono utilizzate in un’ampia gamma di applicazioni pratiche, tra cui:
- Filtraggio dei dati: Identificare e isolare informazioni specifiche all’interno di grandi dataset.
- Validazione dei formati: Verificare l’integrità di indirizzi email, numeri di telefono, URL e altri dati inseriti dagli utenti.
- Manipolazione dei testi: Modificare stringhe di testo, riscrivere URL per SEO, e molto altro ancora.
- Google Analytics: Applicare filtri avanzati per segmentare il traffico web e ottenere insight più dettagliati.
Cosa Imparerai in Questa Guida?
In questa guida completa esploreremo le RegEx in dettaglio, includendo:
- Sintassi di base: Comprendere i caratteri semplici, i meta-caratteri e gli operatori di ripetizione.
- Utilizzo avanzato: Creare pattern complessi utilizzando gruppi, classi di caratteri, e ancoraggi.
- Applicazioni pratiche: Implementare le RegEx in contesti reali come Google Analytics e URL rewriting.
- Strumenti di supporto: Scoprire utili strumenti online e software per testare e costruire le tue RegEx.
Questa guida ti fornirà esempi pratici e suggerimenti utili per sfruttare al meglio le espressioni regolari. Preparati a trasformare il modo in cui gestisci e manipoli i dati testuali!
Introduzione
Il termine RegEx, in inglese “Regular Expressions” indica una funzione per filtrare, confrontare o identificare stringhe di caratteri o codice.

Le espressioni regolari sono state definite da Stephen Kleene nel 1950 ed implementate per la prima volta da Ken Thompson nell’editor QED, era il 1966.
Ancora oggi le RegEx rimangono insostituibili e, per chi lavora nel web, è un plus saperle utilizzare dato che sono presenti in praticamente tutti gli strumenti.
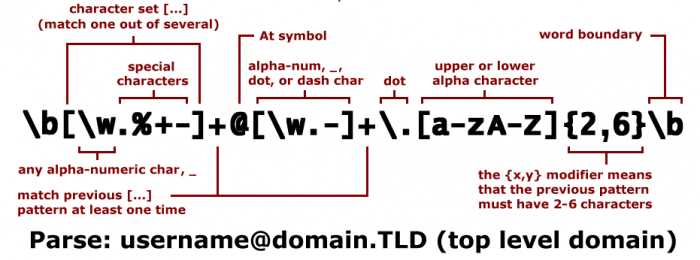
Un esempio di utilizzo pratico delle RegEx potrebbe essere filtrare gruppi di pagine in un report di Google Analytics, oppure creare una regex che redireziona un set di pagine, o ancora validare il formato di una e-mail inserita in un form. Gli indirizzi e-mail infatti devono essere composti in questo modo:
- una sequenza di caratteri alfanumerici
- chiocciola
- altri caratteri alfanumerici
- punto
- due o tre lettere
Il modello è rappresentabile attraverso l’utilizzo delle espressioni regolari, qualora fosse codificata secondo una sintassi ben precisa e riconosciuta da un programma in grado di analizzare le stringhe.
La regex per validare una email è la seguente:
^[_A-Za-z0-9-\\+]+(\\.[_A-Za-z0-9-]+)*@[A-Za-z0-9-]+(\\.[A-Za-z0-9]+)*(\\.[A-Za-z]{2,})$oppure
^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$N.B. non esiste una RegEx infallibile per questo particolare task perché le e-mail possono variare molto una dall’altra. Puoi creare espressioni regolari che sono combinazioni di caratteri e meta-caratteri.
Vediamo nel dettaglio caratteristiche e funzionamento delle RegEx.
Sintassi di base
Le espressioni regolari (RegEx) sono strumenti potenti e versatili per la manipolazione del testo. Comprendere la loro sintassi di base è fondamentale per sfruttarne appieno le potenzialità. Le RegEx permettono di definire pattern precisi per identificare, filtrare e manipolare stringhe di testo in vari contesti.
Elementi Fondamentali:
- Caratteri Letterali:
Ogni lettera, numero, simbolo o spazio ha un significato letterale.
Meta-caratteri:
- Simboli speciali con significati specifici nelle RegEx.
- Punto (.): Rappresenta qualsiasi carattere eccetto il ritorno a capo.
- Asterisco (*): Indica zero o più occorrenze del carattere o gruppo precedente.
- Più (+): Indica una o più occorrenze del carattere o gruppo precedente.
- Punto interrogativo (?): Indica zero o una occorrenza del carattere o gruppo precedente.
- Accento circonflesso (^): Indica l’inizio della stringa.
- Dollaro ($): Indica la fine della stringa.
- Barra verticale (|): Rappresenta un’opzione “o”.
- Parentesi tonde (()): Utilizzate per raggruppare parti dell’espressione.
Classi di Caratteri:
- Definiscono un insieme di caratteri.
- Parentesi quadre ([]): Contengono un set di caratteri da abbinare.
- Intervalli: Usati all’interno delle parentesi quadre per specificare un intervallo di caratteri.
Sequenze di Escape:
- Utilizzate per rappresentare caratteri speciali o non stampabili.
- Backslash (\): Precede un meta-carattere per trattarlo come un carattere normale.
Quantificatori:
- Specificano il numero di occorrenze di un carattere o gruppo.
- Accolade ({}): Definiscono un numero esatto o un intervallo di ripetizioni.
Questa sintassi di base fornisce le fondamenta per costruire espressioni regolari più complesse e potenti. Con la pratica, diventerà più facile creare pattern che rispondano alle tue esigenze specifiche, rendendo le RegEx uno strumento indispensabile per qualsiasi webmaster o professionista SEO.
Ora vediamo nel dettaglio ciascun elemento.
Caratteri
Un carattere è qualsiasi lettera, numero, simbolo o spazio. Nelle RegEx, i caratteri hanno un significato letterale: la lettera A rappresenta esattamente la lettera A, il numero 77 rappresenta esattamente il numero 77, e una parola rappresenta esattamente quella parola, rispettando la distinzione tra maiuscole e minuscole.
Esempio:
- Testo: “Casa123”
- RegEx: Casa
- Risultato: Troverà “Casa” nel testo.
Stringhe semplici
Usare le espressioni regolari per filtrare stringhe semplici è come andare a caccia di mosche con un lanciarazzi. Come vedremo le RegEx permettono di sfruttare specifici operatori per compiti molto complessi, ma possono essere usate anche per necessità molto basilari.
Per filtrare stringhe semplici, basta scrivere la stringa esattamente come desiderata, a meno che non contenga caratteri speciali che devono essere preceduti da un backslash \. Ad esempio, la stringa “del” troverà sia la parola “del” come parola singola che la stessa sequenza all’interno di altre parole.
Esempio:
- Testo: “Il delegato ha parlato della situazione”
- RegEx: del
- Risultato: Troverà “del” in “delegato” e “della”.
Caratteri singoli
Il modo più semplice per utilizzare una RegEx è cercare un singolo carattere. Ad esempio, la RegEx x troverà tutte le occorrenze del carattere x in un testo, indipendentemente dal fatto che x sia una parola a sé stante o parte di un’altra parola.
Esempio:
- Testo: “La volpe salta sopra il box”
- RegEx: x
- Risultato: Troverà le x in “box”.
Caratteri speciali
Le espressioni regolari (RegEx) utilizzano diversi caratteri speciali per rappresentare insiemi di caratteri specifici o per invertire l’insieme. Di seguito sono elencati alcuni dei caratteri speciali più comuni utilizzati nelle RegEx:
\d
Rappresenta una cifra (0-9).
- Esempio: \d corrisponde a “3” in “a3b”.
\w
Rappresenta una lettera, una cifra o un underscore (_). In pratica, \w corrisponde a qualsiasi carattere alfanumerico.
- Esempio: \w corrisponde a “a”, “1”, o “_” in “a_1”.
\s
Rappresenta qualsiasi spazio bianco, inclusi spazi, tabulazioni e nuovi paragrafi.
- Esempio: \s corrisponde a lo spazio tra “hello world”.
\D
Rappresenta qualsiasi carattere che non sia una cifra (l’opposto di \d).
- Esempio: \D corrisponde a “a” in “a3b”.
\W
Rappresenta qualsiasi carattere che non sia una lettera, una cifra o un underscore (l’opposto di \w).
- Esempio: \W corrisponde a “!” in “a!b”.
\S
Rappresenta qualsiasi carattere che non sia uno spazio bianco (l’opposto di \s).
- Esempio: \S corrisponde a “a” in “a b”.
Questi caratteri speciali sono utili per creare pattern RegEx che possono abbinare gruppi di caratteri specifici in un testo, rendendo più facile la ricerca, la manipolazione e la validazione delle stringhe.
Meta-caratteri
I meta-caratteri sono simboli con significati speciali nelle RegEx e non vengono interpretati letteralmente. Analizziamo i principali meta-caratteri utilizzabili nelle espressioni regolari.
Punto (.)
Rappresenta qualsiasi carattere eccetto il ritorno a capo.
Il punto è il jolly delle RegEx e, come nelle carte, rappresenta qualsiasi carattere singolo, quindi qualsiasi lettera, numero, simbolo o spazio. Ad esempio l’espressione regolare .etto rappresenta le stringhe petto, netto, detto, setto, !etto, etc, … Il termine “etto” non sarà incluso nella corrispondenza perché il punto richiede comunque la presenza di un carattere.
Una RegEx, se non specificato, può filtrare parole singole o parti di parole. Ad esempio “.etto” filtrerebbe anche “corretto” e non solo parole di 4 lettere. La RegEx corretta per filtrare solo parole di 4 lettere sarebbe: “\b.etto\b”. Più avanti vedremo come delimitare l’inizio o la fine di una parola con il carattere semplice \b.
- RegEx: a.b
- Troverà: “aab”, “acb”, “a1b” (qualsiasi carattere tra a e b).
Accento Circonflesso (^)
L’accento circonflesso ^ ha due funzioni principali nelle espressioni regolari:
Questo è un meta carattere di ancoraggio. Gli ancoraggi sono elementi fondamentali nelle espressioni regolari, utilizzati per specificare le posizioni relative all’inizio o alla fine di una stringa.
Inizio della Stringa: Quando utilizzato all’inizio di un pattern, ^ indica che la corrispondenza deve avvenire all’inizio della stringa.
Esempio:
- RegEx: ^abc
- Troverà: La stringa “abc” solo se è all’inizio della stringa.
- Esempi di Corrispondenza: “abc”, “abcdef”
- Esempi di Non Corrispondenza: “xyzabc”, “1abc”
Negazione: All’interno di una classe di caratteri (racchiusa tra parentesi quadre), ^ indica la negazione. Significa che la corrispondenza deve avvenire su qualsiasi carattere che non sia specificato nella classe.
Esempio:
- RegEx: [^0-9]
- Troverà: Qualsiasi carattere che non sia una cifra (0-9).
- Esempi di Corrispondenza: “a”, “!”, “#”
- Esempi di Non Corrispondenza: “1”, “2”, “9”
Dollaro ($)
Il simbolo del dollaro $ è utilizzato per ancorare la fine della stringa, indicando che la corrispondenza deve avvenire alla fine della stringa.
Questo è un meta carattere di ancoraggio. Gli ancoraggi sono elementi fondamentali nelle espressioni regolari, utilizzati per specificare le posizioni relative all’inizio o alla fine di una stringa.
Esempio:
- RegEx: abc$
- Troverà: La stringa “abc” solo se è alla fine della stringa.
- Esempi di Corrispondenza: “abc”, “123abc”
- Esempi di Non Corrispondenza: “abcxyz”, “abc1”
- Esempi Pratici di Utilizzo degli Ancoraggi
Verificare l’Inizio di una Stringa:
- Pattern: ^hello
- Trova: “hello world”, “hello123”
- Non Trova: “world hello”, “123hello”
Verificare la Fine di una Stringa:
- Pattern: world$
- Trova: “hello world”, “my world”
- Non Trova: “world is great”, “myworld”
Negare Caratteri Specifici:
- Pattern: [^a-zA-Z]
- Trova: “123”, “!”, “@”
- Non Trova: “abc”, “XYZ”
Utilizzando questi ancoraggi, puoi creare espressioni regolari precise e mirate, capaci di rispondere a esigenze specifiche di filtraggio e validazione delle stringhe.
Operatori di Ripetizione
Gli operatori di ripetizione nelle espressioni regolari (RegEx) sono utilizzati per specificare quante volte un carattere o un gruppo di caratteri può apparire in una stringa. Comprendere questi operatori è essenziale per scrivere pattern flessibili e potenti.
. - Qualsiasi carattere tranne \n.
* - Seleziona 0 o più occorrenze del precedente elemento {0,}.
+ - Seleziona 1 o più occorrenza del precedente elemento {1,}.
? - Seleziona 0 oppure 1 occorrenza del precedente elemento {0,1}.
{n,m} - Numero di ripetizioni. Seleziona il precedente elemento almeno n-volte ma non più di m-volte.
{n,} - Numero di ripetizioni. Seleziona il precedente elemento n-volte o più.
{n} - Seleziona esattamente n-volte il precedente elemento.Asterisco (*)
L’asterisco (*) è un meta-carattere nelle espressioni regolari che indica zero o più occorrenze del carattere o gruppo precedente. Questo significa che il pattern specificato prima dell’asterisco può apparire qualsiasi numero di volte, inclusa nessuna.
Esempi di Utilizzo:
RegEx: ab*
- Testo: “a”, “ab”, “abb”, “abbb”
- Troverà “a”: perché ci sono zero occorrenze di b dopo a.
- Troverà “ab”: perché c’è una occorrenza di b dopo a.
- Troverà “abb”: perché ci sono due occorrenze di b dopo a.
- Troverà “abbb”: perché ci sono tre occorrenze di b dopo a.
RegEx: a.*b
- Troverà qualsiasi stringa che inizia con a e termina con b, con qualsiasi carattere nel mezzo (incluso nessuno).
- Testo: “ab”, “a123b”, “axyzb”
- Risultato: Troverà tutte le stringhe menzionate.
RegEx: go*d
- Troverà “gd”, “god”, “good”, “goood”, ecc.
- Testo: “gd”, “god”, “good”, “goood”
- Risultato: Troverà tutte le stringhe menzionate.
RegEx: ca*t
- Troverà “ct”, “cat”, “caat”, “caaat”, ecc.
- Testo: “ct”, “cat”, “caat”, “caaat”
- Risultato: Troverà tutte le stringhe menzionate.
Importanza dell’Asterisco
L’asterisco è utile per creare pattern flessibili che possono adattarsi a diverse varianti di testo. Ad esempio, può essere utilizzato per trovare parole con lettere ripetute o per gestire stringhe dove alcune parti potrebbero essere opzionali.
È importante distinguere l’asterisco da altri quantificatori come il più (+), che richiede almeno una occorrenza, e il punto interrogativo (?), che indica zero o una occorrenza. Comprendere questi differenziatori permette di scrivere espressioni regolari precise e efficienti.
L’asterisco (*) nelle espressioni regolari è un potente strumento per trovare pattern con zero o più ripetizioni di un carattere o gruppo. Con la pratica, diventerà una parte essenziale del tuo arsenale per la manipolazione e l’analisi dei testi.
Più (+)
Il simbolo più (+) è un meta-carattere nelle espressioni regolari che indica una o più occorrenze del carattere o gruppo precedente. Questo significa che il pattern specificato prima del simbolo più deve apparire almeno una volta, ma può ripetersi un numero indefinito di volte.
Esempi di Utilizzo
RegEx: ab+
- Testo: “ab”, “abb”, “abbb”
- Troverà “ab”: perché c’è una b dopo a.
- Troverà “abb”: perché ci sono due b dopo a.
- Troverà “abbb”: perché ci sono tre b dopo a.
RegEx: a+b
- Troverà stringhe dove a è presente almeno una volta, seguita da b.
- Testo: “ab”, “aab”, “aaab”
- Risultato: Troverà tutte le stringhe menzionate.
RegEx: go+d
- Troverà “god”, “good”, “goood”, ecc., ma non troverà “gd”.
- Testo: “god”, “good”, “goood”
- Risultato: Troverà tutte le stringhe menzionate.
RegEx: ca+t
- Troverà “cat”, “caat”, “caaat”, ecc., ma non troverà “ct”.
- Testo: “cat”, “caat”, “caaat”
- Risultato: Troverà tutte le stringhe menzionate.
Importanza del Più
Il simbolo più è utile quando si vuole assicurare che un certo carattere o gruppo appaia almeno una volta, ma si è anche aperti alla possibilità che appaia più volte. Questo è particolarmente utile per trovare parole con lettere ripetute o per gestire varianti di una stringa che contengono ripetizioni.
È importante distinguere il simbolo più dal punto interrogativo (?), che indica zero o una occorrenza, e dall’asterisco (*), che indica zero o più occorrenze. Comprendere questi quantificatori ti aiuterà a scrivere espressioni regolari più precise ed efficienti.
Il simbolo più (+) nelle espressioni regolari è un potente strumento per trovare pattern con una o più ripetizioni di un carattere o gruppo. Con la pratica, diventerà una parte essenziale del tuo arsenale per la manipolazione e l’analisi dei testi.
Punto interrogativo (?)
Il punto interrogativo (?) è un meta-carattere nelle espressioni regolari che indica zero o una occorrenza del carattere o gruppo precedente. Questo significa che il pattern specificato prima del punto interrogativo può apparire una volta o non apparire affatto.
RegEx: ab?
- Testo: “a”, “ab”
- Troverà “a”: perché ci sono zero occorrenze di b dopo a.
- Troverà “ab”: perché c’è una occorrenza di b dopo a.
RegEx: colou?r
- Troverà “color” e “colour”, accomodando entrambe le varianti ortografiche.
- Testo: “color”, “colour”
- Risultato: Troverà entrambe le stringhe.
RegEx: https?
- Troverà “http” e “https”, gestendo entrambe le versioni del protocollo.
- Testo: “http”, “https”
- Risultato: Troverà entrambe le stringhe.
RegEx: a?bc
- Troverà “abc” e “bc”, poiché a è facoltativa.
- Testo: “abc”, “bc”
- Risultato: Troverà entrambe le stringhe.
Importanza del Punto Interrogativo
Il punto interrogativo è utile per creare pattern flessibili che possono adattarsi a variazioni opzionali. Ad esempio, è particolarmente utile per gestire varianti ortografiche o per trovare parole dove una parte può essere presente o assente.
È importante distinguere il punto interrogativo dall’asterisco (*), che indica zero o più occorrenze, e dal più (+), che indica una o più occorrenze. Comprendere questi quantificatori ti aiuterà a scrivere espressioni regolari precise e adattabili a diverse esigenze.
Il punto interrogativo (?) nelle espressioni regolari è un potente strumento per trovare pattern con zero o una ripetizione di un carattere o gruppo. Con la pratica, diventerà una parte essenziale del tuo arsenale per la manipolazione e l’analisi dei testi.
Slash inverso (\)
Utilizzato per “scappare” i meta-caratteri, permettendo di cercarli letteralmente.
Nelle espressioni regolari, il backslash \ ha la funzione di indicare che il metacarattere successivo deve essere considerato come un carattere semplice, ovvero un carattere letterale. Il backslash viene utilizzato per “sfuggire” ai metacaratteri, in modo che possano essere interpretati come caratteri letterali piuttosto che come simboli speciali all’interno dell’espressione regolare.
Vediamo un esempio.
Spesso capita di dover confrontare stringhe di testo con meta-caratteri. Per filtrare un IP 192.168.1.123, la RegEx giusta potrebbe essere 192.168.1.123 – tuttavia questa stringa corrisponde anche a 192116811123 dato che i punti possono rappresentare qualsiasi carattere. In questo caso quindi il punto va interpretato come tale (meta carattere) e non come variabile della RegEx.
Il backslash (\) definisce quindi che il prossimo carattere va interpretato come carattere semplice e non come meta carattere. Il punto che segue normalmente in una RegEx vorrebbe dire “un carattere qualsiasi”, ma in questo caso significa “un punto”. Quindi lo interpretiamo come un punto letterale.
Precedere un meta-carattere con un backslash indica che il meta-carattere deve essere considerato come carattere e trattato letteralmente. In questo esempio dovresti usare:
192\.168\.1\.123Backslash e caratteri normali
Vediamo l’esempio opposto. Per filtrare da una frase la parola “barba” posso usare l’espressione regolare \bbarba\b – Il carattere “b” preceduto da “\” corrisponde agli spazi bianchi prima o dopo le parole. Esistono molti caratteri che, se preceduti da backslash, possono assumere un significato speciale. Vediamo l’elenco completo:
\A - Inizio del testo.
\a - Codice Bell (segnale acustico).
\b - Bordo di una parola.
\B - Tutto tranne \b.
\c - Codice di controllo (Ctrl). \d - Cifra.
\D - Tutto tranne \d.
\e - Codice di "escape".
\f - Codice di fine pagina.
\n - Codice di fine riga.
\r - Codice di ritorno carrello.
\s - Spazio.
\S - Tutto tranne \s.
\t - Codice di tabulazione.
\uHHHH - Codice di un carattere Unicode.
\v - Codice di tabulazione verticale.
\w - Carattere di una parola.
\W - Tutto tranne \w.
\xHH - Codice di un carattere ASCII.
\Z - Fine del testo. Per filtrare la parola “se” in questa frase: “Dopo sposto la sedia se mi alzo”. Con la RegEx “se” filtrerei due elementi: “Dopo sposto la sedia se mi alzo”. Invece con la RegEx \bse\b filtrerei solo la singola parola “se”: “Dopo sposto la sedia se mi alzo”.
Backslash e caratteri speciali
Come abbiamo visto, backslash ha una duplice funzione: rende speciali i caratteri normali (esempio della barba) e rende normali i caratteri speciali (esempio dell’IP). Il motivo è che nelle espressioni regolari esistono alcuni caratteri speciali che hanno specifici significati, ma quei caratteri potrebbero essere presenti come lettere normali all’interno di un testo. Quindi come riconoscerli? Anteponendo appunto il backslash.
I caratteri speciali delle RegEx sono:
^ - Inizio della stringa/riga.
$ - Fine della stringa/riga. Cosa fare per filtrare un backslash \? Semplice, basta anteporre un backslash: “\\” così non verrà considerato un carattere speciale ma “puntuale”.
Per filtrare “6*6=36” sarebbe errato riscrivere i caratteri tali e quali poiché una RegEx di quel tipo vorrebbe dire “cerca “6=36” seguito da 6 ripetuto zero o più volte. L’espressione corretta è “6\*6=36”.
Operatori di Gruppo e Raggruppamenti nelle Espressioni Regolari
Gli operatori di gruppo e raggruppamenti sono fondamentali per creare espressioni regolari potenti e flessibili. Essi permettono di definire set di caratteri, specificare ripetizioni, creare sotto-espressioni e indicare alternative tra pattern. Di seguito una descrizione dettagliata di ciascun operatore con esempi pratici.
Parentesi Quadre ([])
Le parentesi quadre definiscono una classe di caratteri, cioè un insieme di caratteri tra cui uno può essere una corrispondenza. Puoi anche utilizzare intervalli di caratteri e caratteri speciali all’interno delle parentesi quadre.
- Sintassi: [abc] o [a-z]
- Funzione: Trova uno qualsiasi dei caratteri tra parentesi.
- Esempi:
- RegEx: [abc]
- Troverà: “a”, “b”, o “c”
- Esempi di Corrispondenza: “apple” (trova “a”), “ball” (trova “b”), “cat” (trova “c”)
- Esempi di Non Corrispondenza: “dog”, “fish”
- RegEx: [a-zA-Z0-9]
- Troverà: Qualsiasi lettera maiuscola o minuscola e cifra
- Esempi di Corrispondenza: “a”, “Z”, “5”
- Esempi di Non Corrispondenza: “!”, “@”, “#”
- RegEx: [abc]
Parentesi Graffe ({})
Le parentesi graffe specificano il numero esatto di ripetizioni di un carattere o di un gruppo di caratteri. Possono anche definire un intervallo di ripetizioni.
- Sintassi: a{2} o a{2,4}
- Funzione: Specifica il numero esatto o un intervallo di ripetizioni.
- Esempi:
- RegEx: a{2}
- Troverà: “aa” (esattamente due “a”)
- Esempi di Corrispondenza: “baa”, “aabc”
- Esempi di Non Corrispondenza: “a”, “aaa”, “ab”
- RegEx: a{2,4}
- Troverà: “aa”, “aaa”, “aaaa” (da due a quattro “a”)
- Esempi di Corrispondenza: “aa”, “aaa”, “aaaa”
- Esempi di Non Corrispondenza: “a”, “aaaaa”
- RegEx: a{2}
Parentesi Tonde (())
Le parentesi tonde sono utilizzate per raggruppare caratteri e creare sotto-espressioni. Questo permette di applicare quantificatori all’intero gruppo e di estrarre specifici sottogruppi dalla stringa di corrispondenza.
- Sintassi: (abc)+
- Funzione: Raggruppa caratteri per applicare quantificatori o per catturare sotto-stringhe.
- Esempi:
- RegEx: (abc)+
- Troverà: “abc”, “abcabc”, “abcabcabc” (una o più occorrenze di “abc”)
- Esempi di Corrispondenza: “abc”, “abcabc”, “1abcabc”
- Esempi di Non Corrispondenza: “ab”, “abcd”, “aabbcc”
- RegEx: (\d{2}-\d{2}-\d{4})
- Troverà: Formati di date come “12-34-5678”
- Esempi di Corrispondenza: “12-34-5678”
- Esempi di Non Corrispondenza: “123-45-678”, “12-345-6789”
- RegEx: (abc)+
Barra Verticale (|)
La barra verticale è utilizzata per indicare l’alternativa tra più pattern. Funziona come un operatore logico OR.
- Sintassi: a|b
- Funzione: Trova una corrispondenza con uno dei pattern separati dalla barra verticale.
- Esempi:
- RegEx: a|b
- Troverà: “a” o “b”
- Esempi di Corrispondenza: “apple” (trova “a”), “bat” (trova “b”)
- Esempi di Non Corrispondenza: “cat”, “dog”
- RegEx: (cat|dog|fish)
- Troverà: “cat”, “dog”, o “fish”
- Esempi di Corrispondenza: “I have a cat”, “My dog is cute”, “A fish swims”
- Esempi di Non Corrispondenza: “I have a bird”
- RegEx: a|b
Utilizzo Combinato degli Operatori
Combiniamo alcuni di questi operatori per creare pattern complessi e precisi:
- Pattern: (ab|cd){2,3}
- Funzione: Due o tre occorrenze consecutive del gruppo “ab” o “cd”.
- Esempi di Corrispondenza: “abab”, “cdcd”, “abcdcd”
- Esempi di Non Corrispondenza: “ab”, “cd”, “ababcdcdcd”
- Pattern: ([A-Z][a-z]+|[a-z]+)
- Funzione: Una parola che inizia con una lettera maiuscola seguita da lettere minuscole, oppure una parola composta solo da lettere minuscole.
- Esempi di Corrispondenza: “Apple”, “banana”
- Esempi di Non Corrispondenza: “APPLE”, “Banana1”
Suggerimenti per un Utilizzo Efficace
- Testare le Regex: Utilizza strumenti online come regex101.com per testare le tue espressioni regolari e visualizzare i risultati in tempo reale.
- Commentare le Regex: Se utilizzi regex complesse, includi commenti o suddividi il pattern in componenti più piccoli per una migliore leggibilità.
- Utilizzare Modificatori: Sfrutta i modificatori (come i per case-insensitive, m per multiline) per adattare il comportamento delle regex alle tue esigenze specifiche.
Gli operatori di gruppo e raggruppamenti nelle espressioni regolari offrono una grande flessibilità e potenza, permettendo di creare pattern complessi e specifici per diverse applicazioni pratiche. Comprendere e utilizzare correttamente questi operatori è essenziale per sfruttare appieno le potenzialità delle regex.
Spazi Bianchi
Gli spazi bianchi sono caratteri invisibili che separano parole e altri elementi in un testo. Nelle espressioni regolari, esistono diversi caratteri di spazi bianchi che possono essere utilizzati per rappresentare questi elementi:
\t: Tabulazione (Tab)
Rappresenta un carattere di tabulazione. Viene usato per l’allineamento orizzontale del testo.
- Esempio: In una stringa “Nome\tCognome”, \t rappresenta lo spazio di tabulazione tra “Nome” e “Cognome”.
\r: Ritorno a capo (Carriage Return)
Rappresenta il ritorno a capo, utilizzato principalmente nei sistemi operativi Macintosh.
- Esempio: In una stringa “Prima Linea\rSeconda Linea”, \r porta il cursore all’inizio della stessa riga, sovrascrivendo la “Prima Linea”.
\n: Avanzamento riga (Line Feed)
Rappresenta l’avanzamento di riga, utilizzato nei sistemi operativi Unix/Linux.
- Esempio: In una stringa “Prima Linea\nSeconda Linea”, \n porta il cursore alla linea successiva.
\v: Tabulazione verticale (Vertical Tab)
Rappresenta una tabulazione verticale. Viene utilizzata per spostare il cursore alla stessa posizione in una linea successiva, ma è raramente utilizzata.
- Esempio: In una stringa “Riga 1\vRiga 2”, \v sposta il cursore alla stessa posizione nella linea successiva.
Questi caratteri di spazi bianchi sono utili nelle espressioni regolari per identificare e gestire spazi non visibili nel testo, migliorando la precisione delle operazioni di ricerca e manipolazione.
Flag
Le flag sono opzioni che modificano il comportamento delle espressioni regolari, rendendole più flessibili e potenti. Ecco una descrizione delle flag più comuni:
g (global): Ricerca globale
Quando abilitata, la ricerca non si ferma alla prima corrispondenza trovata, ma continua a cercare in tutto il testo.
- Esempio: Usando /pattern/g, tutte le occorrenze di “pattern” nel testo saranno trovate, non solo la prima.
m (multi-line): Modalità multi-linea
Quando abilitata, i metacaratteri ^ (inizio stringa) e $ (fine stringa) corrispondono all’inizio e alla fine di ogni linea, anziché all’inizio e alla fine dell’intera stringa.
- Esempio: Usando /^pattern$/m, “pattern” sarà trovato all’inizio o alla fine di ogni linea nel testo, non solo all’inizio o alla fine dell’intera stringa.
i (insensitive): Case-insensitive
Quando abilitata, la ricerca diventa insensibile alle maiuscole e minuscole. La RegEx troverà corrispondenze indipendentemente dal caso dei caratteri.
- Esempio: Usando /pattern/i, “Pattern”, “pattern”, e “PATTERN” saranno tutte corrispondenze valide.
Tabella riassuntiva dei caratteri speciali
| Carattere | Significato | Esempio |
|---|---|---|
| * | corrisponde a zero, uno o più del carattere precedente | Ah* corrisponde a Ahhhhh o A |
| ? | corrisponde a zero o uno del carattere precedente | Ah? corrisponde a A o Ah |
| + | corrisponde a uno o più del carattere precedente | Ah+ corrisponde a Ah o Ahhh ma non “A |
| \ | Usato per escludere un carattere speciale | Hungry\? corrisponde a Hungry? |
| . | Wildcard, carattere jolly, corrisponde a qualsiasi carattere | do.* corrisponde a dog door dot etc. |
| ( ) | Gruppo di caratteri | Vedi ad esempio | |
| [ ] | corrisponde ad un range di caratteri |
[cbf]ar corrisponde a “car”, “bar”, o “far”
[0-9]+ corrisponde a qualsiasi numero intero positivo tra 0 e 9 inclusi
[a-zA-Z] corrisponde a lettere ASCII a-z (maiuscole e minuscole)
[^0-9] corrisponde a qualsiasi carattere non numerico |
| | | corrisponde ae previous OR next carattere/group | (Mon)|(Tues)day corrisponde a Monday o Tuesday |
| { } | corrisponde a specified number of occurrences del carattere precedente | [0-9]{3} corrisponde a 315 ma non 31 [0-9]{2,4} corrisponde a 12 123 e 1234 [0-9]{2,} corrisponde a 1234567... |
| ^ | Inizio di una stringa oppure per negare una classe di caratteri []. | ^http corrisponde a stringhe che iniziano con http, come ad esempio un URL.
[^0-9] corrisponde a qualsiasi carattere not 0-9. |
| $ | End of a string. | ing$ corrisponde a exciting ma non ingenious |
Tabella: significato delle classi di caratteri POSIX
POSIX o “Portable Operating System Interface per uniX” è una raccolta di standard che definiscono alcune delle funzionalità che un sistema operativo (UNIX) dovrebbe supportare. Uno di questi standard definisce due modelli di espressioni regolari. I comandi che coinvolgono espressioni regolari, come grep ed egrep, implementano questi modelli su sistemi UNIX conformi a POSIX. Diversi sistemi di database utilizzano anche le espressioni regolari POSIX.
Le espressioni regolari di base – BRE standardizzano funzioni simili a quelle utilizzate dal comando grep UNIX tradizionale. Una cosa che distingue questa funzione è che la maggior parte dei metacaratteri richiede una barra rovesciata \ backslash per conferire al metacarattere la sua funzione. POSIX ERE (Extended Regular Expression), utilizza una barra rovesciata per sopprimere il significato dei metacaratteri. L’uso di una barra rovesciata per uscire annullare un carattere che non è mai un metacarattere è un errore.
Una BRE supporta le espressioni di parentesi POSIX, che sono simili alle classi di caratteri RegEx, con alcune caratteristiche speciali. Le stenografie non sono supportate. Altre caratteristiche che usano i soliti metacaratteri sono il punto per abbinare qualsiasi carattere eccetto un’interruzione di riga, il segno di omissione e il dollaro per abbinare l’inizio e la fine della stringa e la stella per ripetere il token zero o più volte. Per abbinare letteralmente qualcuno di questi caratteri speciali devi anteporre la barra rovesciata.
POSIX BRE non supporta altre funzionalità. Anche l’alternanza non è supportata.
Le espressioni regolari estese dette anche ERE standardizzano alcune funzioni simile a quelle utilizzate dal comando egrep UNIX. “Estese” è relativo al grep UNIX originale, che aveva solo espressioni con parentesi, punto, segno di omissione, dollaro e stella. Una ERE li supporta proprio come una BRE (Basic Regular Expression).
Gli sviluppatori di egrep non hanno provato a mantenere la compatibilità con grep, creando invece uno strumento separato. Quindi egrep e POSIX ERE aggiungono metacaratteri aggiuntivi senza backslash. Puoi usare i backslash per sopprimere il significato di tutti i metacaratteri, proprio come nelle RegEx moderne. L’escape di un carattere che non è un metacarattere è un errore.
| Classe di carattere | Significato |
|---|---|
| [:alpha:] | Qualsiasi lettera, [A-Za-z] |
| [:upper:] | Qualsiasi lettera maiuscola, [A-Z] |
| [:lower:] | Qualsiasi lettera minuscola, [a-z] |
| [:digit:] | Qualsiasi numero, [0-9] |
| [:alnum:] | Qualsiasi carattere alfanumerico, [A-Za-z0-9] |
| [:xdigit:] | Qualsiasi numero esadecimale, [0-9A-Fa-f] |
| [:space:] | Una scheda, una nuova riga, una scheda verticale, un feed di moduli, carriage return, o spazio |
| [:blank:] | Uno spazio o una scheda |
| [:print:] | Qualsiasi carattere stampabile |
| [:punct:] | Qualsiasi carattere di punteggiatura: ! ' # S % & ' ( ) * + , - . / : ; < = > ? @ [ / ] ^ _ { | } ~ |
| [:graph:] | Qualsiasi carattere definito come un carattere stampabile tranne quelli definiti come parte della classe di caratteri spaziali |
| [:word:] | Stringa continua di caratteri alfanumerici e underscore (trattino basso) |
| [:ascii:] | Caratteri ASCII nel range: 0-127 |
| [:cntrl:] | Qualsiasi carattere non parte delle classi di caratteri: [:upper:], [:lower:], [:alpha:], [:digit:], [:punct:], [:graph:], [:print:], [:xdigit:] |
Le RegEx usate con Google Analytics
Come ben sappiamo i filtri di Google Analytics possono essere usati per escludere dai report il traffico interno (all’azienda o al network ad esempio) e, in combinazione con le espressioni RegEx possono filtrare qualsiasi range di IP con una sola stringa.
Nelle impostazioni del profilo di Google Analytics, crea un nuovo filtro customizzato che escluda l’IP aziendale nel campo “Visitor IP Address”. Utilizzando una RegEx del tipo 192\.168\.1\.1[123] si andranno ad escludere gli indirizzi IP 192.168.1.11, 192.168.1.12 e 192.168.1.13. Giocando con le regole sopra descritte potrai rappresentare qualsiasi IP.
Un’altra funzione utile di Google Analytics che può trarre molti vantaggi dall’utilizzo delle espressioni regolari sono i segmenti avanzati. I segmenti avanzati possono essere usati per segmentare le parole chiave non legate al brand così da poter analizzare nello specifico i risultati di attività SEO specifiche.
Per ottenere questi filtri crea un segmento avanzato dove il “medium” deve corrispondere esattamente ad “organic” e come regola successiva aggiungi la RegEx per escludere i termini brand. Ad esempio nel mio profilo ho inserito con filtro “escludi” la RegEx:
[Ee]ve\s?[Mm]ilanoche rappresenta tutti i possibili modi di scrittura possibili del brand (nel limite del ragionevole!).
La stessa cosa con filtro “includi” se vuoi filtrare solo le parole chiave brand:
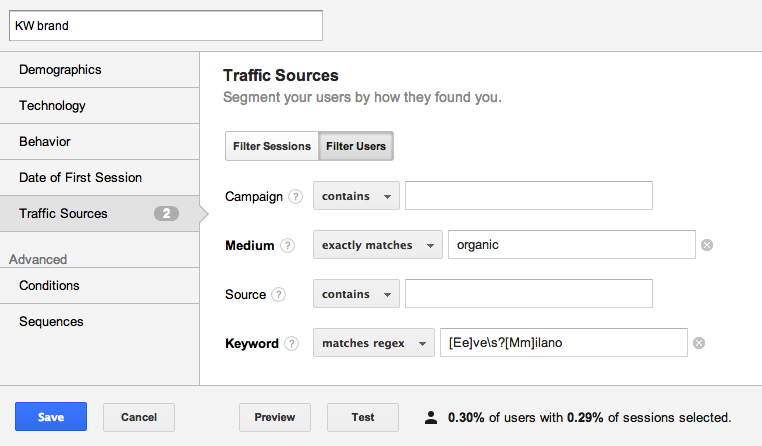
Per filtrare tutte le ricerche a nome mio invece uso l’espressione regolare:
^[Gg]i[oò](vanni)?|^[Ss]acheli|[Gg]i[oò](vanni)?\s?[Ss]acheli|[Ss]acheli\s?[Gg]i[oò](vanni)?Si possono usare i segmenti avanzati anche per filtrare il traffico proveniente dai social network. Nel campo “source” imposta l’espressione regolare del tipo facebook|twitter|youtube|digg etc.
Le espressioni RegEx sono utili anche per impostare i Goals e i vari step nel funnel di conversione. Quando imposti il nuovo Goal come URL di destinazione, usa le espressioni regolari per definire le regole. Ad esempio potresti usare la regola ^/(widgets|gadgets)/checkout/thanks\.php$ per tracciare sia/widgets/checkout/thanks.php e sia /gadgets/checkout/thanks.php. Quando imposti un funnel, tutti gli URl sono trattati come espressioni regolari quindi puoi utilizzare la stessa tecnica.
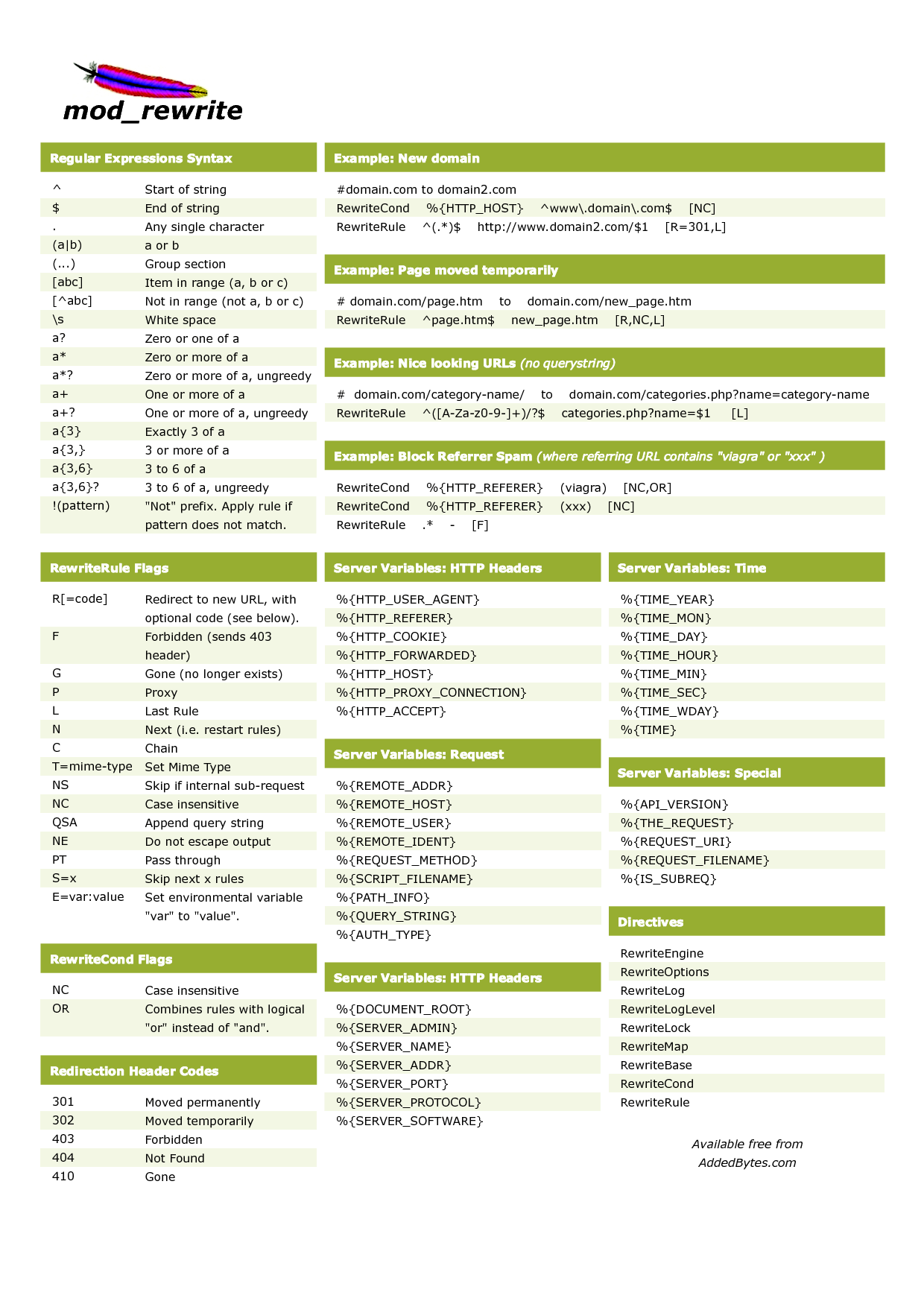
URL Rewriting
Credo che la maggior parte di voi abbia familiarità con gli URL SEO friendly. Gli URL dovrebbero essere statici invece che dinamici e dovrebbero essere anche descrittivi. Spesso questa ottimizzazione è raggiunta con la tecnica dell’URL Rewriting, disponibile su web server Apache tramite il modulo chiamato mod_rewrite. Le regole sono inserite in un file di testo chiamato .htaccess e posizionato nella root del web server. Una semplice regola di rewrite per escludere la categoria dell’URL può essere:
RewriteEngine On
RewriteRule ^categoria/ricette-veloci/?$ categoria.php?cat=ricette-veloci [NC]Questo esempio significa che l’URL www.esempio.it/categoria/ricette-veloci/ dovrebbe attualmente servire la pagina www.esempio.it/categoria.php?cat=ricette-veloci. Come menzionato nelle regole ad inizio articolo, il carattere circonflesso e il dollaro ($) significano che l’URL deve iniziare e finire con ricette-veloci/, e il punto interrogativo significa che lo slash finale è opzionale. Il termine [NC] non fa parte delle espressioni regolari ma è parte della sintassi del mod_rewrite e significa che la regola di rewrite non è case sensitive, ovvero ignora se un carattere è minuscolo o maiuscolo.
Ovviamente questo approccio non è consigliato per grandi siti con migliaia di URL, è proprio in questo caso che le espressioni regolari RegEx tornano particolarmente utili perché è possibile definire un pattern o regole più generali. Una regola di rewrite dinamica che utilizza le RegEx è ad esempio:
RewriteEngine On
RewriteRule ^categoria/([A-Za-z0-9-]+)/?$ categoria.php?cat=$1 [NC]Questa regola imposta che l’URL deve cominciare con categoria/ e che può essere seguito da qualsiasi combinazione di lettere, numeri o simboli fino a quando non ci sono uno o più “+”. Questa parte della regola è racchiusa tra parentesi così che possa fare riferimento nella seconda parte della regola con l’espressione $1. Se hai un set successivo di parentesi ci si può riferire ad esso con $2 e così via. Dato che lo slash finale è opzionale si pone il punto interrogativo, mentre l’accento circonflesso e il dollaro ($) definiscono l’inizio e la fine dell’URL.
Infografica su RegEx e mod_rewrite
Costrutti nella Espressioni Regolari
Characters
x The character x
\\ The backslash character
\0n The character with octal value 0n (0 <= n <= 7)
\0nn The character with octal value 0nn (0 <= n <= 7)
\0mnn The character with octal value 0mnn (0 <= m <= 3, 0 <= n <= 7)
\xhh The character with hexadecimal value 0xhh
\uhhhh The character with hexadecimal value 0xhhhh
\t The tab character ('\u0009')
\n The newline (line feed) character ('\u000A')
\r The carriage-return character ('\u000D')
\f The form-feed character ('\u000C')
\a The alert (bell) character ('\u0007')
\e The escape character ('\u001B')
\cx The control character corresponding to x
Character classes
[abc] a, b, or c (simple class)
[^abc] Any character except a, b, or c (negation)
[a-zA-Z] a through z or A through Z, inclusive (range)
[a-d[m-p]] a through d, or m through p: [a-dm-p] (union)
[a-z&&[def]] d, e, or f (intersection)
[a-z&&[^bc]] a through z, except for b and c: [ad-z] (subtraction)
[a-z&&[^m-p]] a through z, and not m through p: [a-lq-z](subtraction)
Predefined character classes
. Any character (may or may not match line terminators)
\d A digit: [0-9]
\D A non-digit: [^0-9]
\s A whitespace character: [ \t\n\x0B\f\r]
\S A non-whitespace character: [^\s]
\w A word character: [a-zA-Z_0-9]
\W A non-word character: [^\w]
POSIX character classes (US-ASCII only)
\p{Lower} A lower-case alphabetic character: [a-z]
\p{Upper} An upper-case alphabetic character:[A-Z]
\p{ASCII} All ASCII:[\x00-\x7F]
\p{Alpha} An alphabetic character:[\p{Lower}\p{Upper}]
\p{Digit} A decimal digit: [0-9]
\p{Alnum} An alphanumeric character:[\p{Alpha}\p{Digit}]
\p{Punct} Punctuation: One of !"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
\p{Graph} A visible character: [\p{Alnum}\p{Punct}]
\p{Print} A printable character: [\p{Graph}\x20]
\p{Blank} A space or a tab: [ \t]
\p{Cntrl} A control character: [\x00-\x1F\x7F]
\p{XDigit} A hexadecimal digit: [0-9a-fA-F]
\p{Space} A whitespace character: [ \t\n\x0B\f\r]
java.lang.Character classes (simple java character type)
\p{javaLowerCase} Equivalent to java.lang.Character.isLowerCase()
\p{javaUpperCase} Equivalent to java.lang.Character.isUpperCase()
\p{javaWhitespace} Equivalent to java.lang.Character.isWhitespace()
\p{javaMirrored} Equivalent to java.lang.Character.isMirrored()
Classes for Unicode blocks and categories
\p{InGreek} A character in the Greek block (simple block)
\p{Lu} An uppercase letter (simple category)
\p{Sc} A currency symbol
\P{InGreek} Any character except one in the Greek block (negation)
[\p{L}&&[^\p{Lu}]] Any letter except an uppercase letter (subtraction)
Boundary matchers
^ The beginning of a line
$ The end of a line
\b A word boundary
\B A non-word boundary
\A The beginning of the input
\G The end of the previous match
\Z The end of the input but for the final terminator, if any
\z The end of the input
Greedy quantifiers
X? X, once or not at all
X* X, zero or more times
X+ X, one or more times
X{n} X, exactly n times
X{n,} X, at least n times
X{n,m} X, at least n but not more than m times
Reluctant quantifiers
X?? X, once or not at all
X*? X, zero or more times
X+? X, one or more times
X{n}? X, exactly n times
X{n,}? X, at least n times
X{n,m}? X, at least n but not more than m times
Possessive quantifiers
X?+ X, once or not at all
X*+ X, zero or more times
X++ X, one or more times
X{n}+ X, exactly n times
X{n,}+ X, at least n times
X{n,m}+ X, at least n but not more than m times
Logical operators
XY X followed by Y
X|Y Either X or Y
(X) X, as a capturing group
Back references
\n Whatever the nth capturing group matched
Quotation
\ Nothing, but quotes the following character
\Q Nothing, but quotes all characters until \E
\E Nothing, but ends quoting started by \Q
Special constructs (non-capturing)
(?:X) X, as a non-capturing group
(?idmsux-idmsux) Nothing, but turns match flags i d m s u x on - off
(?idmsux-idmsux:X) X, as a non-capturing group with the given flags i d m s u x on - off
(?=X) X, via zero-width positive lookahead
(?!X) X, via zero-width negative lookahead
(?<=X) X, via zero-width positive lookbehind
(?<!X) X, via zero-width negative lookbehind
(?>X) X, as an independent, non-capturing groupRegole utili per Find and Replace
#Selezione tag immagini
<img([\w\W]+?)/>
#Selezione headings
(?s)<h1>.+</h1>
#Selezione div tag
</?\bdiv\b[^>]*>
#Selezione p tag
<p>(.+?)</p>
#Selezione parentesi quadre
\[(.*?)\]
#Selezione parentesi tonde
\(([^\)]+)\)
#Selezione linee bianche
\r\nTester online per le RegEx
Strumenti e approfondimenti
Se desideri testare le funzionalità delle RegEx, puoi utilizzare strumenti come Google Analytics, che offre un filtro sopra i report per sperimentare con le espressioni regolari.
Un’altra ottima risorsa è RegExpal, un tool online che consente di inserire e testare le RegEx in tempo reale, fornendo feedback immediato sui risultati.
Altri strumenti utili:
- developer.mozilla.org/RegExp#Special_caratteres_in_regular_expressions – tutte le info sulle espressioni regolari.
- analytics.blogspot.com/regular-expression-tips-and-tricks.html – alcuni consigli sull’utilizzo delle espressioni regolari con Google Analytics.
- lunametrics.com/Regular-Expressions-Google-Analytics.pdf – un eBook in PDF ben fatto con approfondimenti per ogni meta carattere.
- Informazioni sulle espressioni regolari (RegEx)
- RegExpal.com – strumento online per testare le espressioni regolari.
- Google Analytics Regular Expression Tester
- RegExr.com/ – altro valido strumento online per testare le regole di RegEx.
- moz.com/5-quick-google-analytics-hacks – articolo interessante di @tomcritchlow su come usare le RegEx per filtrare testi in base alla lunghezza delle parole chiave.
- Esercitazioni online – all’uso delle espressioni regolari.
- Regular Expressions – Un mini-linguaggio essenziale per la corrispondenza e la manipolazione del testo.
- Regular-Expressions.info.
- Regexbuddy – software per testare e creare Regex.
- Regexmagic – software per testare e creare Regex.
- Regulator – è un avanzato strumento di test delle espressioni regolari, che include l’evidenziazione della sintassi e l’integrazione con il database online Regexlib.com delle espressioni regolari.
- L’editor Expresso – è adatto sia come strumento didattico per principianti di espressioni regolari sia come ambiente di sviluppo completo per il programmatore esperto o web designer.
- RegexDesigner.NET – è un potente strumento visivo per aiutarti a costruire e testare espressioni regolari .NET. Quando sei soddisfatto della tua espressione regolare, RegexDesigner.NET ti permette di integrarla nella tua applicazione tramite generazione di codice nativo C# o VB.NET.
- Regex Coach è un’applicazione grafica per Windows che può essere utilizzata per sperimentare interattivamente le espressioni regolari (perl compatibili).
- http://regex.larsolavtorvik.com/ – strumento online per testare le RegEx.
- Rubular – è un editor online di espressioni regolari basato su Ruby. È un modo pratico per testare le espressioni regolari mentre le scrivi.
Autore

Mi chiamo Giovanni Sacheli e dal 2009 aiuto le aziende a farsi trovare online. Sono specializzato in SEO tecnica e PPC, competenze che applico quotidianamente nella mia agenzia, Searcus Swiss Sagl. Mi piace sviluppare strumenti a supporto del mio lavoro, ho creato SEOdata.app e cluster.army e co-scritto il libro SEO Audit Avanzato. Curo maniacalmente questo blog per colleghi e appassionati, dove mi "appunto" quello che imparo. Sono un NERD anni '80, motociclista e orgoglioso papà di due bambini.
Link:
Giovanni Sacheli
SEO Audit Avanzato
Searcus Swiss Sagl
SEOdata.app
cluster.army
Commenti |18
Lascia un commentoCiao, se dovessi fare un redirect di decine di URL con questa struttura, che regola dovrei usare?
http://www.sito.it/notizie.asp?action=vis_news&NewsID=68
http://www.sito.it/notizie.asp?action=vis_news&NewsID=74
RewriteRule ^notizie.asp^?$ http://www.sito.it/ [R=301,L] http://www.sito.it/news
Ciao Ele, considera che è sempre meglio fare redirect 1-to1 ed evitare quindi di rimandare tante pagine alla home. Mantenendo l’ID anche nel redirect la regola potrebbe essere una cosa del genere:
RewriteCond %{QUERY_STRING} ^action=vis_news&NewsID=68$ [NC]
RewriteRule ^notizie\.asp$ http://www.sito.it/news.asp?ID=68 [R=301,NE,NC,L]
Ciao Giovanni,
eccellente articolo. Vorrei chiederti un suggerimento…
Hai detto che alcune regole non sono consigliate per grandi siti, ebbene, per un multisito wordpress sottodirectory con molto traffico come posso, nel migliore dei modi, riscrivere l’indirizzo da
nomesito.com/it-it/ *quello che segue
nomesito.com/fr-fr/ *quello che segue
nomesito.com/de-de/ *quello che segue
a
it.it.nomesito.com/ *quello che segue
fr.fr.nomesito.com/ *quello che segue
de.de.nomesito.com/ *quello che segue
Ovviamente i sotto domini saranno precedentemente attivati
Grazie per il cortese suggerimento.
PS Aggiungo che non voglio fare il passaggio da multisito sottodirectory a sotto dominio perché voglio solo riscrivere i siti di lingua nomesito.com/it-it e non nomesito.com/altro, questi ultimi mi vanno bene così.
Ciao Biondo, quasi tutti gli hosting con cPanel ti permettono di creare sottodomini e farli puntare a sottodirectory. Se non hai questa funzione la cosa è un pelo più complessa perchè dovresti far puntare il sottodominio verso il tuo IP e configurare i Virtual Host (cosa fattibile su Hosting dedicati ma non sempre fattibile su VPS).
Per redirezionare la richieste di example.com/blog verso blog.example.com, prova questo redirect:
RewriteEngine on
RewriteCond %{HTTP_HOST} ^(www\.)?example\.com$
RewriteRule ^blog/(.*)$ http://blog.example.com/$1 [L,QSA,R=301]
RewriteCond %{HTTP_HOST} ^blog\.example\.com$
RewriteCond %{REQUEST_URI} !^blog/
RewriteRule ^(.*)$ /blog/$1 [L,QSA]
Una seconda possibilità è mostrata da questa breve guida
Grazie per la celerissima risposta.
Sì, posso farlo con cPanel ma poi l’indirizzo sarebbe accessibile sia da sottodomini che da sotto cartella, con lo stesso contenuto, e a Google questo non piace molto e a me interessa invece che piaccia. :)
Ecco il perché vorrei risolvere in modo tale da non rendere accessibile il sito dalle sotto cartelle.
Sei stato gentilissimo.
Ciao, per bloccare siti di spam con url contenenti trattino – è necessario mettere il backslash davanti?
Cioè quale delle soluzioni è corretta?
RewriteEngine on
RewriteCond %{HTTP_REFERER} buttons\-for\-website\.com [NC,OR]
RewriteCond %{HTTP_REFERER} semalt\.com [NC]
RewriteRule .* – [F,L]
RewriteEngine on
RewriteCond %{HTTP_REFERER} buttons-for-website\.com [NC,OR]
RewriteCond %{HTTP_REFERER} semalt\.com [NC]
Ciao Ele, Semalt è davvero fastidioso :)
La versione corretta è la prima che hai postato:
# blocco referral semalt.com
RewriteEngine on
RewriteCond %{HTTP_REFERER} semalt\.com [NC]
RewriteRule .* – [F]
Ciao Giovanni, scusa se disturbo ma sto impazzendo da un’ora per trovare la giusta espressione regolare per settare una conversione in analytics.
Url da evitare: /book/view/t/e294616c0aa89e21c5936f9201f58c2a/pay/gp
Url da includere: /book/view/t/f3477f7f5a5a4b593b7ecefb4630ae24
Praticamente tutte le url che iniziano con /book/view/t ma che non hanno nella url pay/gp
Ho letto anche le tue guide ma mi manca un passaggio…non trovo il modo di fare AND
Tipo… (book/view/t) AND (^((?!pay/gp).)*$)
Ciao Andrea, grazie per la domanda tecnica :)
L’espressione regolare che seleziona solo gli URL che finiscono con la serie numerica di 32 caratteri potrebbe essere questa:
\/book\/view\/t\/[a-zA-Z0-9]{32}$
Ciao Giovanni, grazie per questo articolo molto chiaro ed esplicativo, volevo chiederti se potrei usare una regex per individuare i nomi ITALIANI in un elenco di nomi MISTI (stranieri ED italiani). Non è un elenco immenso, un po’ meno di 2000 nomi, e credo che per —quantomeno— restringere un po’ il campo andrebbe bene filtrare tutti i nomi senza lettere straniere (xkjwy) e richiedere che ciascuna delle due parole (Cognome, Nome) terminino necessariamente con una vocale. Sei d’accordo con queste regole minime per considerare un nome “italiano”? Sono alle primissime armi in questo frangente , ho già provato a creare qualche regex per trovare nomi italiani come descritto su e ci sono arrivata vicina (purtroppo non la trovo più), ma non ho mai “centrato” l’obiettivo. Perché non esistono elenchi di regex già pronti per l’uso?
Ci ho riprovato, grazie a un editor esplicativo, trovandone di nuovo una che sembra valida, ma non “del tutto” (purtroppo qualcosa ancora viene filtrato- non riesco forse a fargli intendere questa formula —Cognome, Nome— come un’unica entità, perché a volte nel filtraggio si allaccia alla parola successiva che però appartiene a un altro nome e da lì diventa complicato ) :
[A-Za-z][^jkxwy]+[aeiou]\b\,\s[A-Za-z][^jkxwy]+[aeiou]\b
Ho anche provato questa
[^jkxwy]{2,}[aeiou]\b\,\s[a-zA-Z][^jkxwy]{2,}[aeiou]\b$
Ciao Beatrice, dipende dove devi fare questa operazione. Online oppure offline?
Offline non userei le Regex per questo compito. Ti consiglio di partire scaricando un database di nomi italiani (su Google ne trovi diversi) e usare Excel con VLOOKUP per taggare al volo i nomi italiani nella tua lista.
Mi sembra l’approccio più rapido.
Farlo invece online con Regex mi sembra abbastanza complicato date tutte le varianti possibili (“Loris” ad esempio, è un nome italiano ma non lo troverebbe la tua regex).
Ciao Giovanni. Ottimo e chiaro ( ma sono io che probabilmente non riesco a capire bene!! )
Stavo provando ad eseguire una url_regex all’interno di SquidGuard ( squid ) per eseguire questa funzione:
se la chiamata include /.well-known/ ok ( pass ) altrimenti ko ( denied ).
Esempio chiamata: https://www.sito.it/path/.well-known/path
Le regular expression che mi è uscita è:
(^https?:\/\/[^\s”‘&?]+\/[.]well-known\/[^\s”‘]*)
in regex101.com viene validato ma su squid no. E’ pure vero che regex101 valida in PCRE mantre squid legge ERE ( GNUregex ). Mi daresti una mano a capire dove sbaglio ?
Ciao Alessandro,
Hai ragione, SquidGuard utilizza le espressioni regolari Extended (ERE) e non PCRE (Perl Compatible Regular Expressions). Questo significa che alcune funzionalità come il look ahead e il look behind, o il carattere \s per gli spazi bianchi, non sono supportate.
Inoltre, in SquidGuard, l’inizio e la fine dell’URL non devono essere esplicitamente indicati nell’espressioni regolare. SquidGuard applica l’espressione regolare a qualsiasi parte dell’URL.
Potresti provare con la seguente espressione regolare:
(^https?:\/\/[^"'&?]+\/\.well-known\/[^"'&]*)
In questa espressione regolare, ho rimosso l’uso di \s (dato che non è supportato da ERE) e ho sostituito [.] con \. per corrispondere al carattere ‘.’ letterale.
Se questa espressione regolare non funziona come previsto, potrebbe essere utile avere un esempio dell’URL che stai cercando di bloccare e un esempio dell’URL che stai cercando di consentire, così da poter affinare l’espressione regolare.
Grazie Giovanni,
si infatti non va….
Allora nel mio caso il server che sta dietro Squid ha tutto bloccato.
Ho creato un allow list nella quale ho inserito solo un sito pilota: www.ansa.it e funziona.
Oltre il sito pilota, ho inserito una url_regex testata con successo:
^.*\b(roma|pisa)\b.*$
questa regex però mi filtra solo la prima parte della chiamata in uscita che è (non valida al momento) :
https://www.miosito.roma.it/servizi/well-known/check
oppure
https://www.miosito.pisa.it/servizi/well-known/check
quindi viene “colpita” roma o pisa ed è corretto, ma non riesco invece a far validare una keyword che viene dopo lo “/” ( per esempio servizi oppure .well-known )
sigh…
Ciao Alessandro!
Un altro tentativo che puoi fare per filtrare la keyword dopo lo “/” nell’URL, è modificare leggermente l’espressione regolare.
Puoi provare questa:
^./(roma|pisa)/.$
Questa espressione regolare corrisponderà a URL che contengono “roma” o “pisa” dopo lo “/”. Ad esempio, filtrerà URL come:
https://www.miosito.roma.it/servizi/well-known/check
https://www.miosito.pisa.it/servizi/well-known/check
Spero che questa soluzione funzioni. Fammi sapere se bisogno di ulteriori chiarimenti o aiuto.
Grazie Giovanni, alla fine ho capito che questi filtri non riescono ad intercettare il traffico cifrato ( https ). Infatti da debug( debug 23,9 ) non viene mai catturato il path in SSL ( ma solo in chiaro HTTP )…. sigh….
Ciao Alessandro,
Mi dispiace per la frustrazione, capisco il tuo dilemma. Purtroppo, questo è un problema comune quando si cerca di filtrare il traffico HTTPS. La natura crittografata del protocollo HTTPS protegge la privacy degli utenti, ma rende anche più difficile per gli amministratori di sistema vedere e gestire il traffico.
In teoria, è possibile configurare Squid per decifrare e ispezionare il traffico HTTPS utilizzando una funzione chiamata SSL Bump, ma ciò richiede un certo livello di competenza tecnica e presenta alcune sfide legali ed etiche.
L’uso di SSL Bump può potenzialmente violare le leggi sulla privacy, a seconda della giurisdizione in cui ti trovi, e può richiedere il consenso degli utenti finali. Inoltre, implementarlo correttamente può richiedere di installare un certificato di autorità di certificazione (CA) personalizzato su ogni dispositivo che si connette attraverso il proxy.
Se decidi di esplorare questa opzione, ti consiglio di fare una ricerca approfondita e di consultare un professionista della sicurezza informatica o un consulente legale per assicurarti di capire tutte le implicazioni.
Se non è possibile o desiderabile utilizzare SSL Bump, potresti dover cercare altre soluzioni per gestire il traffico HTTPS. Potrebbe valere la pena esplorare soluzioni alternative o commerciali che possano gestire in modo più efficace il traffico HTTPS.
Mi dispiace di non poter essere di più aiuto. Buona fortuna!