La similarità del coseno è una metrica usata per misurare quanto due vettori sono simili tra loro calcolando il coseno dell’angolo tra di essi in uno spazio multidimensionale. È ampiamente utilizzata in campi come l’elaborazione del linguaggio naturale (NLP), il machine learning e il data mining, in particolare per confrontare documenti o rappresentazioni vettoriali di parole (embedding).
Se vuoi approfondire come i vettori vengono utilizzati per rappresentare parole, frasi o documenti e scoprire come tecniche avanzate come gli embeddings trasformano i dati testuali in forme comprensibili per i modelli di machine learning, avevo scritto una guida dedicata. In questa guida esploro il concetto di embeddings, come funzionano, e perché sono fondamentali per applicazioni come il clustering, la ricerca semantica e i sistemi di raccomandazione. Leggi l’articolo sugli embeddings per scoprire di più: Embeddings – La guida completa.
Formula Matematica
La formula della similarità del coseno è:
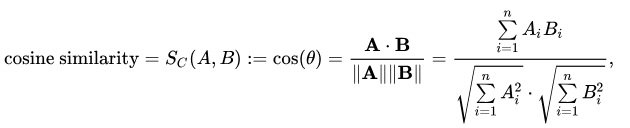
Dove:
- A e B sono i due vettori.
- A ⋅ B è il prodotto scalare dei due vettori.
- ∥A∥ e ∥B∥ sono le norme (lunghezze) dei vettori.
- θ è l’angolo tra i due vettori.
La similarità del coseno aiuta a capire quanto due insiemi di dati (rappresentati come vettori) sono orientati nella stessa direzione in uno spazio multidimensionale. Non misura la loro distanza effettiva, ma quanto “vanno d’accordo” in termini di direzione.
Direzione e distanza?
Per capire la differenza tra direzione e distanza, possiamo immaginare due frecce (vettori) che partono dallo stesso punto in uno spazio. Ogni freccia rappresenta un insieme di dati o un oggetto.
Distanza
La distanza misura quanto lontani sono due punti o vettori nello spazio. In termini pratici, risponde alla domanda: “Quanto sono separati questi due oggetti?”. È influenzata sia dall’orientamento dei vettori sia dalla loro lunghezza.
Ad esempio:
- Se due vettori hanno magnitudini molto diverse (uno è molto lungo e l’altro è corto), la distanza tra di loro sarà grande anche se puntano nella stessa direzione.
- Nei dati numerici o spaziali, la distanza è utile quando vuoi confrontare valori assoluti, come la posizione geografica o il valore numerico.
La distanza Euclidea è la misura più comune e si calcola come la lunghezza della linea retta che unisce due punti. Immagina due città su una mappa: la distanza Euclidea è come tracciare una linea dritta tra di loro.
Direzione
La direzione misura l’orientamento di un vettore nello spazio, ignorando la sua lunghezza. In termini pratici, risponde alla domanda: “Questi due oggetti si muovono o puntano nella stessa direzione?”.
Quando consideriamo solo la direzione, non importa quanto grandi o piccoli siano i vettori; ci interessa solo se “guardano” nella stessa direzione o in direzioni simili. Due vettori che puntano nella stessa direzione avranno un coseno dell’angolo tra di loro vicino a 1, indipendentemente dalla loro lunghezza.
Ad esempio:
- Nei dati testuali, un documento lungo e uno corto possono avere lo stesso argomento (puntano nella stessa direzione) anche se il primo contiene molte più parole.
- Questo è il motivo per cui la similarità del coseno è usata per confrontare documenti o insiemi di dati che devono essere valutati per il contenuto, non per la lunghezza.
Esempio pratico
Immagina due recensioni:
- “Questa macchina è molto veloce e moderna.”
- “Macchina veloce, moderna e davvero innovativa.”
Se rappresentiamo queste recensioni come vettori di parole significative (ad esempio, usando TF-IDF), noteremo che puntano in una direzione simile: entrambe parlano di “velocità”, “modernità” e “innovazione”. Anche se la seconda recensione è più lunga, la direzione dei vettori rimane simile, quindi la similarità del coseno sarà alta.
Ora, considera una recensione diversa: 3. “La macchina è lenta e vecchia.”
Qui, il vettore avrà una direzione molto diversa perché usa parole come “lenta” e “vecchia”, che sono concettualmente opposte a “veloce” e “moderna”. La similarità del coseno sarà quindi bassa, anche se la lunghezza del testo è simile.
Quando usare la direzione e quando la distanza?
- Direzione (similarità del coseno) è utile quando vuoi confrontare il contenuto o il significato di oggetti indipendentemente dalla loro grandezza. È per questo che è comune nei dati testuali o nei sistemi di raccomandazione.
- Distanza (es. Euclidea) è utile quando la posizione assoluta o i valori numerici contano, come nella classificazione di dati fisici o quando la magnitudine è importante.
La scelta tra direzione e distanza dipende dal tipo di dati e dal problema che stai cercando di risolvere.
Interpretazione del Risultato
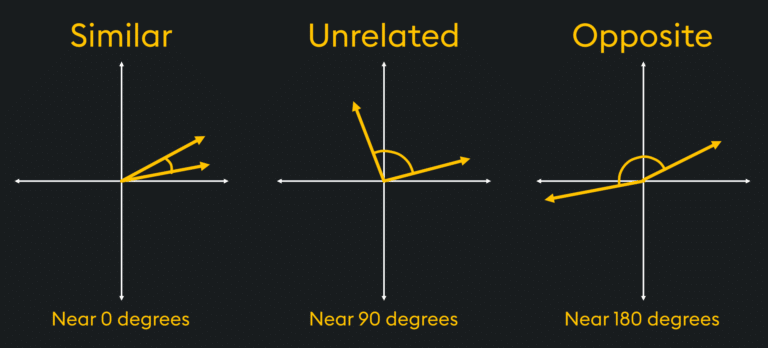
La similarità del coseno restituisce un valore compreso tra -1 e 1, a seconda dell’angolo tra i due vettori nello spazio. Questo valore riflette il grado di somiglianza tra i due vettori in termini di direzione.
Valore vicino a 1:
I due vettori puntano quasi nella stessa direzione, il che significa che i due oggetti rappresentati dai vettori sono molto simili o correlati.
Ad esempio, due documenti che parlano quasi dello stesso argomento avranno una similarità del coseno alta.
Valore vicino a 0:
I due vettori sono perpendicolari o indipendenti. Non hanno nulla in comune dal punto di vista delle loro caratteristiche.
Ad esempio, un documento che parla di “sport” e un altro di “fisica quantistica” potrebbero avere una similarità vicina a 0.
Valore vicino a -1 (meno comune in pratica):
I vettori puntano in direzioni opposte, indicando una correlazione negativa (cioè ciò che è alto in un vettore è basso nell’altro e viceversa).
Ad esempio, potrebbe succedere se usi il metodo in contesti dove una caratteristica positiva per un oggetto è negativa per l’altro (come sentiment opposti).
Esempio con un’analogia
Immagina due persone che descrivono lo stesso film. Se entrambe usano parole simili per raccontarlo (es. “azione”, “avventura”, “coinvolgente”), i loro vettori avranno una direzione molto simile, quindi la similarità del coseno sarà alta.
Se invece una descrive il film come “noioso” e “lento”, mentre l’altra dice “veloce” e “entusiasmante”, i vettori saranno molto diversi e la similarità del coseno sarà bassa.
Perché non si basa sulla distanza?
La similarità del coseno ignora la lunghezza dei vettori, concentrandosi solo sulla loro direzione. Questo è utile, ad esempio, quando i dati rappresentano frequenze o pesi, perché non importa quanto siano grandi i valori assoluti, ma solo come si relazionano tra loro.
Similarità del coseno nel contesto SEO
La similarità del coseno è molto utile in ambito SEO per confrontare i contenuti perché aiuta a misurare il grado di somiglianza tra due testi, valutandone le parole o le frasi più significative senza considerare la loro lunghezza. Questo approccio è fondamentale, ad esempio, per identificare contenuti duplicati o per valutare quanto due pagine web siano semanticamente correlate.
Quando si parla di SEO, uno degli obiettivi principali è assicurarsi che ogni pagina di un sito abbia un contenuto unico e rilevante per una specifica intenzione di ricerca. Tuttavia, capita spesso che ci siano testi simili tra loro su diverse pagine, specialmente in siti di grandi dimensioni (e-commerce, portali di notizie, ecc.), dove la ripetizione di frasi standardizzate o descrizioni di prodotto potrebbe creare problemi di duplicazione.
La similarità del coseno entra in gioco qui: rappresentando il testo di ogni pagina come un vettore numerico che riflette la frequenza o l’importanza delle parole (ad esempio usando tecniche come TF-IDF, che dà più peso alle parole uniche e significative), è possibile confrontare due contenuti in termini di orientamento nello spazio. Se due testi sono molto simili, il loro vettore avrà una direzione quasi identica, portando a un valore di similarità vicino a 1.
Facciamo un esempio pratico. Immagina un sito di e-commerce che vende scarpe sportive. Se due pagine di prodotto hanno descrizioni come:
- Pagina A: “Scarpe da corsa leggere e comode. Adatte per lunghe distanze e attività quotidiane. Design moderno e traspirante.”
- Pagina B: “Scarpe leggere e comode. Ideali per lunghe camminate e attività quotidiane. Realizzate con un design moderno.”
Anche se le due descrizioni non sono identiche, sono semanticamente molto simili. La similarità del coseno permetterebbe di calcolare il grado di sovrapposizione tra i due contenuti, rivelando che i vettori delle parole più importanti puntano in direzioni quasi uguali. In questo caso, il valore risultante potrebbe essere intorno a 0.9, indicando che i contenuti sono molto simili e potrebbero essere percepiti dai motori di ricerca come duplicati.
Questo tipo di analisi è cruciale perché i motori di ricerca, come Google, cercano di evitare di indicizzare contenuti duplicati che non apportano valore aggiunto agli utenti. Se molte pagine di un sito sono troppo simili tra loro, il rischio è che il motore di ricerca ne indicizzi solo alcune, riducendo la visibilità complessiva del sito.
La similarità del coseno può essere utile anche per verificare l’unicità dei contenuti rispetto alla concorrenza. Supponiamo che un blog pubblica un articolo su “I benefici del camminare”. Confrontando il contenuto del blog con altri già pubblicati sul web, la similarità del coseno può mostrare se il testo si distingue realmente o se ripete concetti già presenti. Ad esempio, se il valore di similarità rispetto a un articolo di un competitor fosse superiore a 0.8, si potrebbe concludere che il contenuto non è abbastanza originale e necessiterebbe di revisioni per migliorare la sua unicità.
La similarità del coseno aiuta i SEO a garantire che i contenuti di un sito siano distintivi, originali e ben ottimizzati, sia per evitare penalizzazioni dovute a contenuti duplicati, sia per competere in modo più efficace nei risultati di ricerca.
Applicazioni concrete nella SEO e casi d’uso specifici
Un’applicazione pratica della similarità del coseno in ambito SEO è il confronto di contenuti per identificare duplicazioni o similitudini. Ad esempio, in un sito e-commerce con migliaia di pagine prodotto, le descrizioni potrebbero risultare simili tra loro. Usando tecniche basate su TF-IDF e similarità del coseno, è possibile calcolare un punteggio per ogni coppia di pagine, evidenziando quali contenuti necessitano di essere differenziati. Un altro caso è il confronto tra il contenuto di una pagina del proprio sito e quelli dei competitor, per verificare se il proprio testo si distingue abbastanza o se ripete concetti già presenti online.
Collegamento al concetto di “Search Intent”
La similarità del coseno è strettamente legata al concetto di search intent. Quando un consulente SEO ottimizza una pagina, uno degli obiettivi è rispondere all’intento di ricerca dell’utente in modo più completo rispetto ai competitor. Usando la similarità del coseno, puoi confrontare il contenuto della tua pagina con i primi risultati per una determinata keyword e misurare quanto il tuo testo sia simile in termini semantici. Questo aiuta a identificare gap informativi o migliorare il focus dell’articolo per allinearlo meglio all’intento dell’utente.
Ad esempio, se il tuo articolo risulta semanticamente troppo distante dai contenuti che dominano la SERP per una keyword, potrebbe non rispondere correttamente all’intento di ricerca. In questi casi, analizzare i contenuti top-ranking con la similarità del coseno può darti una direzione chiara per migliorare.
Strumenti e workflow per SEO
Per calcolare la similarità del coseno, puoi utilizzare diversi strumenti e workflow, anche senza essere un programmatore esperto. Ad esempio:
- Screaming Frog: Esporta i testi di un sito web, inclusi title, meta description e contenuti principali. Questi dati possono essere elaborati con Excel o Python.
- Python + Scikit-learn: Con poche righe di codice, puoi rappresentare i testi come vettori TF-IDF e calcolare la similarità del coseno. Librerie come spaCy o NLTK possono aiutare nella pre-elaborazione dei testi.
- Strumenti avanzati: Piattaforme come Semrush o Ahrefs non calcolano direttamente la similarità del coseno, ma puoi esportare i dati e integrarli in analisi personalizzate.
Un workflow semplice potrebbe essere:
- Esporta i contenuti del tuo sito con Screaming Frog dopo aver calcolato gli embeddings.
- Usa Python per calcolare la similarità del coseno rispetto a competitor o pagine interne.
- Analizza i risultati per individuare contenuti troppo simili o non abbastanza distintivi.
Similarità del coseno nel clustering
La similarità del coseno è una metrica che può essere utilizzata nel clustering, ma non è l’unico approccio possibile né sempre il più adatto. La clusterizzazione è un processo di raggruppamento di dati simili in insiemi (cluster), e la scelta della misura di somiglianza (o distanza) e dell’algoritmo dipende dai dati e dagli obiettivi specifici.
La Similarità del coseno è particolarmente utile nel clustering quando i dati sono rappresentati come vettori e l’importante non è tanto la distanza assoluta, ma la direzione o la relazione proporzionale tra i dati. È molto efficace con dati sparsificati e ad alta dimensionalità, come nei seguenti contesti:
- Documenti e testo: Quando rappresentiamo documenti come vettori (ad esempio con il modello TF-IDF), la Similarità del coseno può identificare documenti che trattano argomenti simili, ignorando la lunghezza o la frequenza assoluta dei termini.
- Word embeddings: Nella comparazione di rappresentazioni vettoriali di parole, la Similarità del coseno misura quanto due parole sono semanticamente correlate.
Nel clustering basato su Similarità del coseno, gli algoritmi più usati sono:
- K-means con Similarità del coseno: Si modifica la funzione di distanza standard (Euclidea) usando la Similarità del coseno come misura di somiglianza per raggruppare i vettori.
- Agglomerative clustering: Gli elementi sono raggruppati in cluster usando metriche di somiglianza come Similarità del coseno.
Tuttavia, l’uso della Similarità del coseno può essere meno efficace se i dati non sono vettorializzati o se la distanza assoluta è importante.
Alternative e altre metriche per il clustering
Nel clustering e nell’analisi dei dati, la scelta della metrica per valutare la somiglianza o la distanza tra i dati è fondamentale. Oltre alla similarità del coseno, esistono numerose altre metriche che possono essere utilizzate, ognuna adatta a contesti e tipi di dati specifici. Ecco una panoramica delle principali:
- Distanza Euclidea: Misura la distanza “fisica” tra due punti in uno spazio cartesiano. È una delle metriche più comuni e si basa sulla radice quadrata della somma dei quadrati delle differenze tra le coordinate. Applicabile in contesti con dati continui e ben definiti.
- Distanza di Manhattan (L1): Somma delle differenze assolute tra le coordinate di due punti. È adatta quando i cambiamenti lungo ogni dimensione sono indipendenti.
- Distanza di Jaccard: Ideale per dati binari o insiemi, misura la dissimilarità tra due insiemi come il rapporto tra l’intersezione e l’unione.
- Distanza di Hamming: Calcola il numero di posizioni in cui due stringhe binarie o simboliche di uguale lunghezza differiscono. È particolarmente utile per dati categorici o binari.
- Distanza Mahalanobis: Tiene conto delle correlazioni tra le variabili e della loro varianza, rendendola utile per dati multivariati. Utilizza la matrice di covarianza per normalizzare la distanza.
- Distanza di Levenshtein (o Edit Distance): Conta il numero minimo di operazioni richieste per trasformare una stringa in un’altra. Le operazioni includono inserimenti, cancellazioni e sostituzioni. È particolarmente rilevante per il confronto di testi o stringhe.
- Divergenza di Kullback-Leibler (KL Divergence): Utilizzata per confrontare due distribuzioni di probabilità. Misura la perdita di informazione nel considerare una distribuzione 𝑄 come approssimazione di un’altra distribuzione 𝑃.
- Indice di Bray-Curtis: Misura la dissimilarità tra due insiemi basandosi sulla somma delle differenze assolute divisa per la somma dei valori totali. È spesso usato per dati ecologici o biologici.
- Distanza Coseno: Una variazione della similarità del coseno, calcola effettivamente 1−cos(θ) per rappresentare la distanza.
- Entropia di Shannon: Sebbene non sia una “distanza” diretta, viene usata per misurare la dissimilarità basandosi sull’incertezza o la diversità di informazioni. Può essere combinata con altre metriche per calcolare la divergenza tra distribuzioni.
- Distanza Minkowski: Una generalizzazione delle distanze Euclidea e di Manhattan. Introduce un parametro 𝑝 che controlla il tipo di distanza.
- Distanza Wasserstein (Earth Mover’s Distance): Utilizzata per confrontare distribuzioni di probabilità, misura il “costo” minimo per trasformare una distribuzione in un’altra. È ampiamente applicata in analisi di immagini e deep learning.
- Distanza Canberra: Una variazione della distanza Manhattan, penalizza maggiormente le differenze relative su piccole magnitudini.
- Kernel-based Measures: Metriche basate su kernel (ad esempio, RBF o polinomiale) che trasformano i dati in uno spazio di dimensione superiore per calcolare la somiglianza in modo non lineare.
Algoritmi di clustering
I principali algoritmi di clustering si basano su metriche diverse e possono essere personalizzati per usare Similarità del coseno o altre metriche. Alcuni esempi:
- K-means: Solitamente usa la distanza Euclidea, ma può essere adattato per usare Similarità del coseno.
- DBSCAN: Si basa su densità e vicinanza, ideale per dati con cluster di forma irregolare. Può usare metriche diverse.
- Agglomerative clustering: Metodo gerarchico che può adottare metriche come Similarità del coseno, Euclidea o Jaccard.
- Spectral clustering: Si basa su grafi e matrici di somiglianza, in cui la Similarità del coseno può essere usata per costruire la matrice di adiacenza.
- Gaussian Mixture Models (GMM): Modella i cluster come distribuzioni gaussiane, basandosi su metriche probabilistiche.
Quale metodo è migliore?
La scelta del metodo e della metrica dipende da diversi fattori:
- Tipo di dati: Per vettori testuali o word embeddings, la Similarità del coseno è spesso più adatta perché ignora la magnitudine dei vettori e si concentra sulle loro direzioni. Per dati numerici continui o spaziali, la distanza Euclidea è una scelta comune.
- Obiettivi del clustering: Se si vuole raggruppare documenti per argomento, la Similarità del coseno funziona bene. Se i cluster devono riflettere distanze fisiche o numeriche, la distanza Euclidea potrebbe essere più significativa.
- Forma dei cluster: Algoritmi come K-means funzionano bene con cluster di forma circolare e usano spesso metriche come la distanza Euclidea. DBSCAN o Agglomerative clustering sono migliori per cluster di forma irregolare o quando i dati contengono rumore.
Conclusione
La Similarità del coseno è molto efficace in contesti in cui la direzione (e non la distanza assoluta) è ciò che conta, come nei dati testuali o di alto livello semantico. Tuttavia, non è sempre la scelta migliore. Per ottenere risultati ottimali, è essenziale scegliere la metrica e l’algoritmo di clustering in base alla natura dei dati e agli obiettivi specifici. Non esiste una metrica “migliore” in assoluto; la scelta dipende dal contesto.
Vuoi migliorare il posizionamento del tuo sito e creare contenuti realmente efficaci per i motori di ricerca? Attraverso tecniche avanzate come la Similarità del Coseno e gli Embeddings, puoi ottimizzare i tuoi contenuti in modo strategico, distinguerti dai competitor e raggiungere i tuoi obiettivi di visibilità. Prenota una consulenza personalizzata con i nostri esperti di EVE Milano o iscriviti al nostro corso SEO avanzato per approfondire queste tecniche e applicarle al tuo progetto.
Contattaci per saperne di più e iniziare a lavorare su una strategia SEO concreta e mirata.
Articoli correlati
Autore

Mi chiamo Giovanni Sacheli e dal 2009 aiuto le aziende a farsi trovare online. Sono specializzato in SEO tecnica e PPC, competenze che applico quotidianamente nella mia agenzia, Searcus Swiss Sagl. Mi piace sviluppare strumenti a supporto del mio lavoro, ho creato SEOdata.app e cluster.army e co-scritto il libro SEO Audit Avanzato. Curo maniacalmente questo blog per colleghi e appassionati, dove mi "appunto" quello che imparo. Sono un NERD anni '80, motociclista e orgoglioso papà di due bambini.
Link:
Giovanni Sacheli
SEO Audit Avanzato
Searcus Swiss Sagl
SEOdata.app
cluster.army