Definizione di embedding
In questi giorni il termine embedding è sulla bocca di molti SEO, dato che il nostro tool preferito (Screaming Frog) nell’ultima versione (20.0) ha implementato la possibilità di estrarre gli embedding tramite script JS che usano le API di GPT.
Ma cosa sono questi embeddings?
In informatica, un embedding è una rappresentazione numerica di dati in uno spazio vettoriale di dimensioni ridotte.
Le parole sono legate al concetto di linguaggio, che i computer non comprendono, per lavorare con le parole dobbiamo prima trasformarle in numeri.
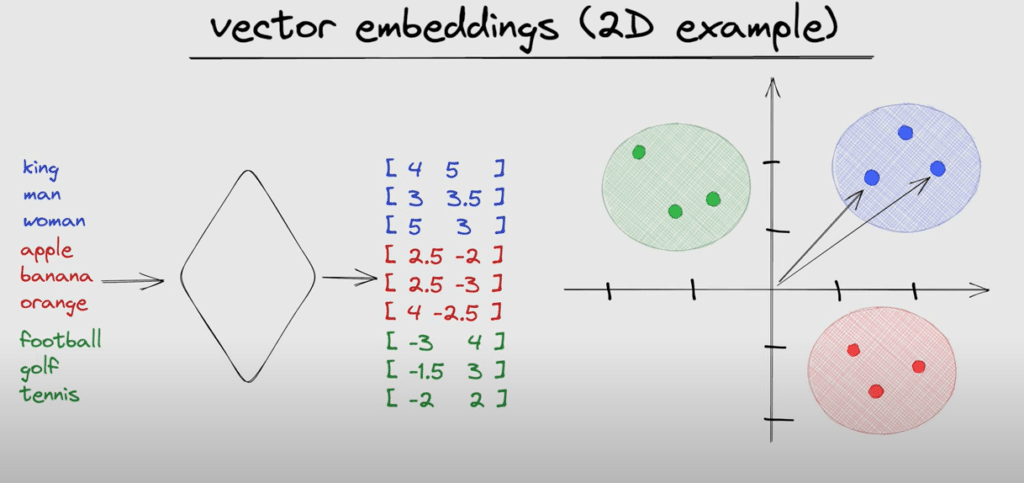
Più semplicemente, embedding è un modo per trasformare le parole in numeri che i computer possono capire e lavorare. Ogni parola viene rappresentata come un vettore, cioè una lista di numeri. Questi vettori hanno una dimensione fissa che dipende dai metodi di embedding che utilizziamo e contengono informazioni che rappresentano il significato delle parole.
Le dimensioni rappresentano la capacità del vettore di rappresentare i significati di una parola o di un documento. Più in dettaglio, le dimensioni di un vettore di embedding rappresentano la quantità di informazioni numeriche o “features” che possono essere codificate per ogni elemento all’interno dello spazio dell’embedding. Ogni dimensione in un vettore di embedding può essere vista come una “caratteristica latente” che contribuisce a definire l’oggetto rappresentato nell’ambito di un particolare modello o compito. Le dimensioni dello spazio di embedding sono scelte in base a diversi fattori, come la complessità del dataset e del compito specifico, e influenzano sia la capacità del modello di catturare dettagli significativi sia la sua efficienza computazionale.
Ad esempio, in un modello linguistico, le dimensioni di un vettore di embedding di parole potrebbero catturare aspetti semantici, sintattici e anche relazioni contestuali delle parole. Maggiore è il numero delle dimensioni, più dettagliate possono essere le informazioni rappresentate, ma aumenta anche la complessità computazionale e il rischio di sovra adattamento (overfitting) del modello.
Gli embedding di GPT-4 (come quelli di altri modelli GPT di OpenAI) tipicamente hanno una dimensione di 12.288 per il modello di punta, anche se la dimensione può variare in base alla specifica configurazione del modello utilizzato.
Per il modello GPT-3, ci sono vari modelli con dimensioni diverse:
- GPT-3 Small: 768 dimensioni.
- GPT-3 Medium: 1.536 dimensioni.
- GPT-3 Large: 3.072 dimensioni.
- GPT-3 XL: 6.144 dimensioni.
- GPT-3.5 e GPT-4 più grandi: possono avere dimensioni superiori, come i 12.288 per il modello di punta di GPT-4.
Queste dimensioni rappresentano la lunghezza del vettore di embedding che il modello utilizza per rappresentare i token di testo. Questi vettori vengono utilizzati come input nei livelli successivi del modello per generare risposte o continuare testi.
La tecnica di embedding consente di trasformare dati complessi, come parole o immagini, in vettori di numeri reali che preservano le caratteristiche semantiche dei dati originali. Gli embedding vengono utilizzati per catturare relazioni e somiglianze tra i dati, facilitando operazioni di machine learning come classificazione, clustering e ricerca semantica. Un esempio comune sono gli embedding di parole, che rappresentano termini con vettori che riflettono il loro significato nel contesto linguistico.
Immagina di avere una lista di parole come “gatto”, “cane”, “automobile”. Invece di usare le parole direttamente, le trasformiamo in vettori numerici. Questo ci permette di usare tecniche matematiche e algoritmi per analizzare e capire il linguaggio.
In questo blog avevo già parlato di embedding e vettori quando avevo approfondito Word2Vec. Word2Vec è una tecnica di natural language processing (NLP) introdotta da ricercatori di Google nel 2013 che ci aiuta a creare questi embedding. È un modello che impara a rappresentare le parole in uno spazio numerico in modo che le parole con significati simili siano vicine tra loro.
Vettori e spazi vettoriali
Un vettore è un oggetto matematico che ha una magnitudine (lunghezza) e una direzione. È rappresentato come una sequenza ordinata di numeri, ad esempio, in uno spazio a due dimensioni, un vettore potrebbe essere (𝑥,𝑦).
Uno spazio vettoriale, invece, è una struttura matematica formata da un insieme di vettori, dove si possono eseguire operazioni di clustering, di somma di vettori e moltiplicazione per uno scalare. Questi vettori seguono regole specifiche, come la chiusura sotto somma e moltiplicazione, e contengono uno zero vettoriale.
Applicazioni pratiche di embedding
Gli embeddings hanno molte applicazioni pratiche nel campo della SEO. Ecco alcuni esempi:
- Clustering: Raggruppamento di parole o documenti in base alla loro somiglianza.
- Classificazione: Assegnazione di categorie a parole o documenti basata su modelli addestrati.
- Raccomandazioni: Suggerimento di articoli rilevanti agli utenti.
- Misurazione di Somiglianza e Diversità: Valutazione delle somiglianze e differenze tra parole e documenti.
- Rilevamento di Anomalie: Identificazione di elementi che si discostano significativamente dai dati.
- Recupero di Informazioni: Ottenimento di informazioni rilevanti da grandi dataset.
- Traduzione Automatica: Traduzione automatica di testi tra lingue.
- Generazione di Testo: Produzione automatica di testi, spesso simili a quelli scritti da umani.
Questi esempi mostrano come gli embeddings possano migliorare varie applicazioni grazie alla loro capacità di rappresentare dati complessi in spazi vettoriali di dimensioni ridotte.
Cosa fare con gli embedding ottenuti da SF?
Una volta che hai una serie di URL di un sito web con i relativi embeddings, ci sono molteplici applicazioni e analisi che puoi eseguire in ambito SEO con Python.
Ecco alcune delle possibilità:
Clustering dei Contenuti
Da amante del clustering non potevo che partire con questo esempio.
Il clustering è una tecnica di apprendimento automatico non supervisionato utilizzata per raggruppare oggetti o dati in insiemi omogenei, chiamati cluster. Gli oggetti all’interno di un cluster sono più simili tra loro rispetto a quelli di altri cluster. L’obiettivo principale del clustering è scoprire la struttura intrinseca di un insieme di dati, suddividendolo in sottogruppi significativi senza etichette predefinite. Esistono vari algoritmi di clustering, tra cui K-means, DBSCAN (Density-Based Spatial Clustering of Applications with Noise) e l’algoritmo gerarchico. Questi algoritmi utilizzano diverse metriche di similarità e approcci per determinare come raggruppare i dati.
Puoi usare algoritmi di clustering come K-means o Hdbscan per raggruppare gli URL in base alla somiglianza dei loro embeddings. Questo ti permetterà di identificare gruppi di pagine web con contenuti simili.
Vediamo un esempio di clustering con K-means:
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
from sklearn.metrics.pairwise import cosine_similarity
# Supponiamo di avere una lista di URL e una funzione che scarica il contenuto di una pagina web
urls = ["http://example.com", "http://example.org", "http://example.net"]
# Funzione che scarica il contenuto di una pagina web (dummy function per l'esempio)
def fetch_content(url):
return "Dummy content from " + url
# Scarica i contenuti delle pagine web
contents = [fetch_content(url) for url in urls]
# Usa TF-IDF per creare embeddings testuali dai contenuti delle pagine web
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(contents)
# Applica K-means clustering
num_clusters = 2
kmeans = KMeans(n_clusters=num_clusters, random_state=42)
kmeans.fit(X)
# Stampa i risultati
labels = kmeans.labels_
for i, url in enumerate(urls):
print(f"URL: {url} - Cluster: {labels[i]}")Con K-means, specifichiamo il numero di cluster desiderati (num_clusters) e applichiamo l’algoritmo agli embeddings.
Esempio di clustering con Hdbscan:
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import hdbscan
# Supponiamo di avere una lista di URL e una funzione che scarica il contenuto di una pagina web
urls = ["http://example.com", "http://example.org", "http://example.net"]
# Funzione che scarica il contenuto di una pagina web (dummy function per l'esempio)
def fetch_content(url):
return "Dummy content from " + url
# Scarica i contenuti delle pagine web
contents = [fetch_content(url) for url in urls]
# Usa TF-IDF per creare embeddings testuali dai contenuti delle pagine web
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(contents)
# Applica HDBSCAN clustering
clusterer = hdbscan.HDBSCAN(min_cluster_size=2, metric='euclidean')
labels = clusterer.fit_predict(X.toarray())
# Stampa i risultati
for i, url in enumerate(urls):
print(f"URL: {url} - Cluster: {labels[i]}")Il vantaggio di HDBSCAN è che non è necessario specificare il numero di cluster in anticipo. Invece, si specifica la dimensione minima del cluster (min_cluster_size), e l’algoritmo determina il numero ottimale di cluster.
Analisi di Similarità
Puoi calcolare la somiglianza tra diverse pagine con Sklearn per identificare contenuti duplicati o correlati. L’algoritmo di similarità del coseno è comunemente usato per questo scopo.
import requests
from bs4 import BeautifulSoup
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
# Lista di URL da analizzare
urls = ["http://example.com", "http://example.org", "http://example.net"]
# Funzione per scaricare e pulire il contenuto di una pagina web
def fetch_content(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
# Rimuove script e stile
for script in soup(["script", "style"]):
script.decompose()
# Ottiene il testo pulito
text = soup.get_text()
return text
# Scarica i contenuti delle pagine web
contents = [fetch_content(url) for url in urls]
# Usa TF-IDF per creare embeddings testuali dai contenuti delle pagine web
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(contents)
# Calcola la similarità del coseno tra tutti i documenti
cosine_similarities = cosine_similarity(X)
# Stampa la matrice di similarità
print("Matrice di similarità del coseno:")
print(cosine_similarities)
# Identifica contenuti duplicati o altamente correlati
threshold = 0.8 # Soglia di similarità per considerare i contenuti duplicati
for i in range(len(urls)):
for j in range(i + 1, len(urls)):
if cosine_similarities[i, j] > threshold:
print(f"I contenuti di {urls[i]} e {urls[j]} sono altamente correlati (similarità: {cosine_similarities[i, j]:.2f})")Raccomandazioni di Contenuti
Utilizzando la somiglianza tra embeddings, puoi implementare un sistema di raccomandazione che suggerisce agli utenti pagine web correlate in base alle loro preferenze o alla cronologia di navigazione.
import requests
from bs4 import BeautifulSoup
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
# Lista di URL da analizzare
urls = [
"http://example.com",
"http://example.org",
"http://example.net",
"http://example.edu",
"http://example.biz"
]
# Funzione per scaricare e pulire il contenuto di una pagina web
def fetch_content(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
# Rimuove script e stile
for script in soup(["script", "style"]):
script.decompose()
# Ottiene il testo pulito
text = soup.get_text()
return text
# Scarica i contenuti delle pagine web
contents = [fetch_content(url) for url in urls]
# Usa TF-IDF per creare embeddings testuali dai contenuti delle pagine web
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(contents)
# Calcola la similarità del coseno tra tutti i documenti
cosine_similarities = cosine_similarity(X)
# Stampa la matrice di similarità
print("Matrice di similarità del coseno:")
print(cosine_similarities)Classificazione dei Contenuti
Puoi addestrare un modello di classificazione per etichettare le pagine web in diverse categorie basate sui loro embeddings. Ad esempio, potresti voler classificare le pagine in categorie come “Blog”, “Prodotto”, “Servizio”, ecc.
import requests
from bs4 import BeautifulSoup
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, accuracy_score
# Supponiamo di avere una lista di URL con le loro rispettive categorie
data = [
{"url": "http://example.com/blog1", "category": "Blog"},
{"url": "http://example.com/product1", "category": "Prodotto"},
{"url": "http://example.com/service1", "category": "Servizio"},
{"url": "http://example.com/blog2", "category": "Blog"},
{"url": "http://example.com/product2", "category": "Prodotto"},
{"url": "http://example.com/service2", "category": "Servizio"}
]
# Funzione per scaricare e pulire il contenuto di una pagina web
def fetch_content(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
# Rimuove script e stile
for script in soup(["script", "style"]):
script.decompose()
# Ottiene il testo pulito
text = soup.get_text()
return text
# Scarica i contenuti delle pagine web e crea una lista di testi e categorie
texts = []
categories = []
for item in data:
content = fetch_content(item["url"])
texts.append(content)
categories.append(item["category"])
# Usa TF-IDF per creare embeddings testuali dai contenuti delle pagine web
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(texts)
y = categories
# Suddivide i dati in set di addestramento e di test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Crea e addestra il classificatore Random Forest
clf = RandomForestClassifier(random_state=42)
clf.fit(X_train, y_train)
# Effettua le predizioni sul set di test
y_pred = clf.predict(X_test)
# Valuta il modello
print("Accuracy:", accuracy_score(y_test, y_pred))
print("Classification Report:")
print(classification_report(y_test, y_pred))Visualizzazione dei Contenuti
Puoi ridurre la dimensionalità degli embeddings e visualizzarli per comprendere meglio la distribuzione e la relazione tra le pagine del sito web.
Tecniche come PCA (Principal Component Analysis) o t-SNE (t-distributed Stochastic Neighbor Embedding) sono utili per questo scopo.
Questo esempio mostra come utilizzare PCA per ridurre la dimensionalità degli embeddings e visualizzarli.
import requests
from bs4 import BeautifulSoup
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
# Lista di URL da analizzare
urls = [
"http://example.com",
"http://example.org",
"http://example.net",
"http://example.edu",
"http://example.biz"
]
# Funzione per scaricare e pulire il contenuto di una pagina web
def fetch_content(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
# Rimuove script e stile
for script in soup(["script", "style"]):
script.decompose()
# Ottiene il testo pulito
text = soup.get_text()
return text
# Scarica i contenuti delle pagine web
contents = [fetch_content(url) for url in urls]
# Usa TF-IDF per creare embeddings testuali dai contenuti delle pagine web
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(contents)
# Riduce la dimensionalità degli embeddings usando PCA
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X.toarray())
# Visualizza gli embeddings ridotti
plt.figure(figsize=(10, 6))
plt.scatter(X_pca[:, 0], X_pca[:, 1], c='blue', edgecolor='k', s=50)
for i, url in enumerate(urls):
plt.text(X_pca[i, 0], X_pca[i, 1], url, fontsize=9)
plt.title('Visualizzazione delle Pagine Web con PCA')
plt.xlabel('Component 1')
plt.ylabel('Component 2')
plt.grid(True)
plt.show()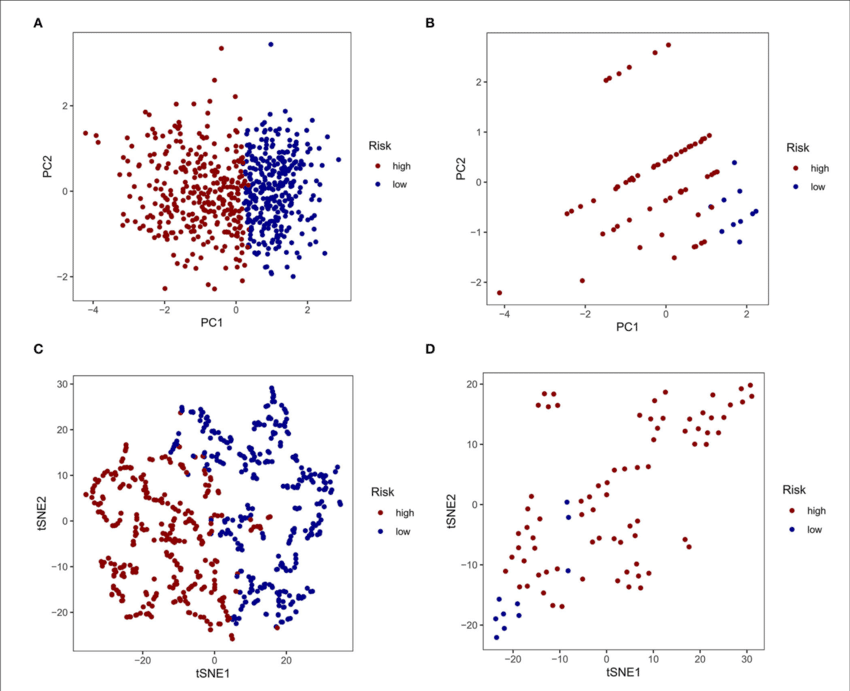
Questi sono solo alcuni degli esempi di ciò che puoi fare con gli embeddings dei tuoi URL. Le possibilità sono vaste e dipendono dagli obiettivi specifici del tuo progetto e dalle caratteristiche dei dati di cui disponi.
Come ottenere gli embedding di pagine web?
Ora vediamo dei metodi alternativi a SF per ottenere embeddings da testi.
Questa è una pratica fondamentale nell’elaborazione del linguaggio naturale (NLP) per trasformare parole, frasi o documenti in rappresentazioni numeriche che i computer possono processare. Ci sono diversi metodi e modelli per ottenere questi embeddings, tra cui Word2Vec (w2v), GloVe, FastText, e i più recenti modelli di trasformatori come GPT (Generative Pre-trained Transformer). Vediamo ciascuno di questi metodi in dettaglio.
Word2Vec (w2v)
Word2Vec è un modello sviluppato da Google che trasforma le parole in vettori di numeri. Ci sono due varianti principali del modello: Continuous Bag of Words (CBOW) e Skip-gram.
Caratteristiche:
- Continuous Bag of Words (CBOW): Questo metodo predice una parola basata sul contesto che la circonda. Ad esempio, data una frase come “Il gatto __ sulla sedia”, il modello cerca di indovinare che la parola mancante è “dorme” usando le parole circostanti “Il gatto” e “sulla sedia”.
- Skip-gram: Questo metodo fa l’opposto. Dato un termine centrale, cerca di prevedere le parole circostanti. Ad esempio, data la parola “gatto”, cerca di indovinare che le parole circostanti potrebbero essere “il”, “dorme”, “sedia”.
Vantaggi:
È efficace per catturare le relazioni semantiche tra parole. Le parole simili vengono mappate in vicinanza nello spazio vettoriale.
Come utilizzarlo:
Esempio in Python usando Gensim:
from gensim.models import Word2Vec
# Esempio di corpus
sentences = [["il", "gatto", "dorme"], ["il", "cane", "abbaia"]]
# Addestramento del modello
model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, workers=4)
# Ottenere l'embedding di una parola
vector = model.wv['gatto']
print(vector)GloVe (Global Vectors for Word Representation)
GloVe è un modello sviluppato da Stanford che utilizza statistiche globali del testo per rappresentare le parole in uno spazio vettoriale.
Caratteristiche:
Statistiche globali: Utilizza le co-occorrenze delle parole in un corpus.
Vantaggi:
Efficace per catturare relazioni semantiche e sintattiche.
Come utilizzarlo:
GloVe pre-addestrato può essere scaricato e utilizzato direttamente:
import numpy as np
# Carica il file GloVe pre-addestrato
embeddings_index = {}
with open('glove.6B.100d.txt', 'r') as f:
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
# Ottenere l'embedding di una parola
vector = embeddings_index.get('gatto')
print(vector)FastText
FastText è un modello sviluppato da Facebook che estende Word2Vec includendo informazioni sui caratteri.
Caratteristiche:
Subparole: Considera anche le subparole (es. “gatt” e “atto” per “gatto”).
Vantaggi:
Migliora la rappresentazione delle parole rare o non presenti nel vocabolario.
Come utilizzarlo:
Esempio in Python usando Gensim:
from gensim.models import FastText
# Esempio di corpus
sentences = [["il", "gatto", "dorme"], ["il", "cane", "abbaia"]]
# Addestramento del modello
model = FastText(sentences, vector_size=100, window=5, min_count=1, workers=4)
# Ottenere l'embedding di una parola
vector = model.wv['gatto']
print(vector)Trasformatori (Transformers) – GPT e BERT
I transformers (no, non sto parlando di Optimus Prime), come GPT (Generative Pre-trained Transformer) e BERT (Bidirectional Encoder Representations from Transformers), rappresentano lo stato dell’arte nell’NLP.
Caratteristiche di GPT:
- Unidirezionale: Prevede il testo in modo sequenziale (da sinistra a destra).
- Generazione di testo: Eccellente nella generazione di testo coerente e naturale.
Caratteristiche di BERT:
- Bidirezionale: Considera il contesto sia a sinistra che a destra della parola.
- Comprensione del contesto: Eccellente per attività come domande e risposte e classificazione del testo.
Come utilizzarlo:
Esempio in Python usando Hugging Face Transformers:
from transformers import BertTokenizer, BertModel
import torch
# Carica il tokenizer e il modello BERT pre-addestrato
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
# Frase di cui ottenere l'embedding
phrase = "Il gatto dorme sulla sedia"
# Tokenizza la frase
inputs = tokenizer(phrase, return_tensors='pt')
# Ottieni l'output del modello
outputs = model(**inputs)
# L'output contiene gli embedding del livello nascosto
last_hidden_states = outputs.last_hidden_state
# Prendi la media degli embeddings per ottenere un singolo vettore per la frase
embedding = torch.mean(last_hidden_states, dim=1).detach().numpy()
print(embedding)Le tecniche di embedding come Word2Vec, GloVe, FastText e i modelli di trasformatori come GPT e BERT hanno rivoluzionato il modo in cui elaboriamo e comprendiamo il linguaggio naturale. Ogni metodo ha i suoi vantaggi e applicazioni specifiche. La scelta del metodo dipende dalle esigenze specifiche del tuo progetto e dalle risorse computazionali a disposizione.
That’s all folks
Ora che hai capito perché Screaming Frog ha implementato questa funzione non resta che metterti all’opera e sfruttare questi nuovi dati per valutare in modo più approfondito i contenuti di un sito web. Buon lavoro!
Articoli correlati
Autore

Mi chiamo Giovanni Sacheli e dal 2009 aiuto le aziende a farsi trovare online. Sono specializzato in SEO tecnica e PPC, competenze che applico quotidianamente nella mia agenzia, Searcus Swiss Sagl. Mi piace sviluppare strumenti a supporto del mio lavoro, ho creato SEOdata.app e cluster.army e co-scritto il libro SEO Audit Avanzato. Curo maniacalmente questo blog per colleghi e appassionati, dove mi "appunto" quello che imparo. Sono un NERD anni '80, motociclista e orgoglioso papà di due bambini.
Link:
Giovanni Sacheli
SEO Audit Avanzato
Searcus Swiss Sagl
SEOdata.app
cluster.army