Cos’è il PageRank
Il PageRank è un algoritmo sviluppato da Google che assegna un punteggio numerico a ogni pagina web in base alla quantità e alla qualità dei link che riceve. Il principio è semplice: un link da una pagina A verso una pagina B equivale a un “voto” di fiducia. Più voti riceve una pagina, e più autorevoli sono le pagine che la linkano, maggiore sarà il suo PageRank.
Tecnicamente, il PageRank modella il comportamento di un navigatore casuale (random surfer) che segue link ipertestuali in modo aleatorio. Il punteggio di ogni pagina rappresenta la probabilità stazionaria che il navigatore si trovi su quella pagina dopo un numero infinito di click. L’algoritmo opera sul grafo dei link del web, dove le pagine sono nodi e i link sono archi direzionali.
Nonostante Google utilizzi oggi centinaia di segnali di ranking, il PageRank resta uno dei meccanismi fondamentali per la valutazione dell’autorevolezza di una pagina. Documenti interni trapelati nel 2024 confermano che varianti aggiornate dell’algoritmo sono ancora operative nel sistema di ranking di Google.
La storia del PageRank
Il paper di Stanford (1998)
Nel 1996 Larry Page e Sergey Brin, dottorandi alla Stanford University, iniziarono a lavorare su un progetto di ricerca chiamato “BackRub”. L’intuizione era rivoluzionaria: utilizzare la struttura dei link del web come segnale di qualità, ispirandosi alla citation analysis accademica sviluppata da Eugene Garfield negli anni ’50 e alla Hyper Search di Massimo Marchiori dell’Università di Padova.
Nel 1998 pubblicarono il paper fondamentale “The Anatomy of a Large-Scale Hypertextual Web Search Engine” (Computer Networks and ISDN Systems, Volume 30, 1998, pp. 107-117), che descriveva per la prima volta l’architettura di Google e l’algoritmo del PageRank. Nello stesso anno fu pubblicato anche il brevetto di riferimento. Poco dopo, Page e Brin fondarono Google Inc.
Il nome “PageRank” è un gioco di parole tra il cognome di Larry Page e il concetto di “ranking di pagina”.
Il brevetto US6285999
Il brevetto originale del PageRank (U.S. Patent 6,285,999 — “Method for node ranking in a linked database”) fu depositato il 9 gennaio 1998 e pubblicato il 4 settembre 2001. L’inventore formale è il solo Larry Page, anche se Brin contribuì in modo determinante alla ricerca.
Il brevetto fu assegnato alla Stanford University, non a Google. Google ottenne la licenza esclusiva. In cambio, Stanford ricevette 1,8 milioni di azioni Google, vendute nel 2005 per 336 milioni di dollari. Il brevetto è scaduto il 24 settembre 2019, rendendo l’algoritmo originale di pubblico dominio.
La Toolbar PageRank (2000–2016)
Nel dicembre 2000 Google lanciò la Google Toolbar per Internet Explorer, che includeva un indicatore visivo del PageRank: una barra verde con un valore da 0 a 10. Questo valore utilizzava una scala logaritmica, il che significava che passare da PR 4 a PR 5 richiedeva un salto molto maggiore rispetto a passare da PR 1 a PR 2.

La Toolbar PageRank divenne rapidamente un’ossessione per i webmaster. L’ultimo aggiornamento pubblico del valore avvenne il 6 dicembre 2013. Nel Q4 2014 Google confermò che non avrebbe più aggiornato il valore visibile. Il 15 aprile 2016 Google rimosse definitivamente l’indicatore PageRank dalla Toolbar. Il servizio Google Toolbar fu poi interrotto del tutto nel dicembre 2021.
La fine del PageRank pubblico
Il 15 ottobre 2009 un dipendente Google annunciò la rimozione dell’indicatore PageRank da Google Search Console (all’epoca Webmaster Tools), dichiarando: “We’ve been telling people for a long time that they shouldn’t focus on PageRank so much. Many site owners seem to think it’s the most important metric for them to track, which is simply not true.“
La decisione di nascondere il PageRank fu motivata dal fatto che il valore pubblico veniva sistematicamente abusato: i webmaster lo usavano come unica metrica di valutazione, alimentando un mercato di compravendita di link basato esclusivamente sul PR della pagina ospitante. Rimuovendo il dato pubblico, Google eliminò l’incentivo alla manipolazione diretta.
Come funziona l’algoritmo
Il modello del Random Surfer
L’algoritmo del PageRank si fonda sul modello del random surfer (navigatore casuale): un utente immaginario che naviga il web cliccando link in modo del tutto casuale. Ad ogni pagina visitata, il navigatore ha due opzioni:
- Con probabilità d (il fattore di smorzamento), clicca uno dei link presenti nella pagina, scelto a caso con uguale probabilità
- Con probabilità (1 − d), si annoia e salta a una pagina completamente casuale del web (il “teletrasporto”)
Questo modello risolve due problemi strutturali del grafo del web: le pagine senza link in uscita (dead ends, che bloccherebbero il navigatore) e i gruppi isolati di pagine (che intrappolerebbero il navigatore in un ciclo). Il teletrasporto garantisce che il navigatore possa raggiungere qualsiasi pagina del web.
Matematicamente, questo processo è formalizzabile come una catena di Markov ergodica: gli stati sono le pagine web, le transizioni sono i link, e il PageRank di ogni pagina è la probabilità stazionaria di trovarsi su quella pagina a regime.
La formula matematica
La formula del PageRank per una pagina A è:
Dove:
- PR(A) = PageRank della pagina A
- d = fattore di smorzamento (damping factor), tipicamente 0,85
- N = numero totale di pagine nel grafo
- T₁, T₂, …, Tₙ = le pagine che linkano alla pagina A
- L(Tᵢ) = numero di link in uscita dalla pagina Tᵢ
- PR(Tᵢ) = PageRank della pagina Tᵢ
Ogni pagina che linka ad A trasferisce una frazione del proprio PageRank, divisa per il numero totale dei suoi link in uscita. Il termine (1 − d) / N rappresenta la probabilità di teletrasporto: il PageRank minimo che ogni pagina riceve indipendentemente dai link.
Il fattore di smorzamento (d = 0,85)
Il fattore di smorzamento d controlla il bilanciamento tra link equity e teletrasporto. Nel paper originale di Brin e Page, il valore suggerito è 0,85, che significa:
- L’85% del PageRank di una pagina è determinato dai link che riceve
- Il 15% è distribuito uniformemente a tutte le pagine (teletrasporto)
Valori più alti di d (es. 0,95) danno maggior peso alla struttura dei link ma rallentano la convergenza del calcolo. Valori più bassi (es. 0,50) convergono più velocemente ma riducono la capacità discriminante dell’algoritmo. Il valore 0,85 rappresenta un compromesso tra accuratezza e velocità computazionale.
Calcolo iterativo e convergenza
Il PageRank non si calcola con una singola operazione ma tramite un processo iterativo. All’inizio, tutte le pagine ricevono un valore di PageRank uguale (tipicamente 1/N). Ad ogni iterazione, il PageRank di ciascuna pagina viene ricalcolato applicando la formula. Il processo si ripete fino a quando la differenza tra due iterazioni successive scende sotto una soglia di tolleranza predefinita.
Per un web di miliardi di pagine, questo calcolo è un problema di algebra lineare su scala massiva. Google lo esegue come moltiplicazione iterativa tra un vettore di stato e la matrice di transizione del grafo del web. La convergenza è garantita dalle proprietà della catena di Markov sottostante (ergodicità e aperiodicità, assicurate dal fattore di teletrasporto).
Esempio numerico: calcolo su un mini-grafo
Consideriamo un web composto da 4 pagine (A, B, C, D) con questa struttura di link:
- A linka a B e C
- B linka a C
- C linka a A
- D linka a B e C

La matrice di adiacenza (chi linka chi, diviso per i link in uscita):
A B C D A [ 0 1/2 1/2 0 ] B [ 0 0 1 0 ] C [ 1 0 0 0 ] D [ 0 1/2 1/2 0 ]
Usiamo d = 0,85 e N = 4. Valore iniziale: PR₀ = 1/4 = 0,25 per tutte le pagine.
Iterazione 1:
- PR(A) = (1−0,85)/4 + 0,85 × [PR(C)/1] = 0,0375 + 0,85 × 0,25 = 0,2500
- PR(B) = 0,0375 + 0,85 × [PR(A)/2 + PR(D)/2] = 0,0375 + 0,85 × 0,25 = 0,2500
- PR(C) = 0,0375 + 0,85 × [PR(A)/2 + PR(B)/1 + PR(D)/2] = 0,0375 + 0,85 × 0,50 = 0,4625
- PR(D) = 0,0375 + 0,85 × 0 = 0,0375 (nessuna pagina linka a D)
Iterazione 2:
- PR(A) = 0,0375 + 0,85 × [0,4625/1] = 0,4306
- PR(B) = 0,0375 + 0,85 × [0,2500/2 + 0,0375/2] = 0,1597
- PR(C) = 0,0375 + 0,85 × [0,2500/2 + 0,2500/1 + 0,0375/2] = 0,4094
- PR(D) = 0,0375
Dopo circa 20-30 iterazioni i valori convergono. Il risultato evidenzia che C e A ottengono il PageRank più alto perché ricevono link da più pagine o da pagine con meno link in uscita, mentre D — che non riceve nessun link — resta bloccata al valore minimo di teletrasporto.
Questo esempio dimostra un principio chiave: le pagine orfane (senza link in ingresso) hanno il PageRank minimo possibile. Nell’architettura di un sito, ogni pagina importante deve ricevere link interni adeguati.
L’evoluzione: dal Random Surfer al Reasonable Surfer
Il brevetto US8117209 (2010)
Il modello originale del PageRank tratta tutti i link di una pagina come equivalenti: ogni link ha la stessa probabilità di essere cliccato. Nel mondo reale, questo non è vero. Un link prominente nel corpo del testo riceve molti più click di un link nel footer.
Nel 2010 Google brevettò il Reasonable Surfer Model (U.S. Patent 8,117,209 — “Ranking documents based on user behavior and feature data”). Questo modello evolve il random surfer in un navigatore “ragionevole” che clicca i link con probabilità differenti in base alle caratteristiche del link stesso e del contesto in cui si trova.
Fattori che influenzano il peso di un link
Secondo il brevetto, il PageRank trasferito da un link dipende da:
- Posizione nella pagina — un link above the fold (visibile senza scroll) ha più peso di uno nel footer o nella sidebar
- Dimensione e stile del font — link più grandi e visivamente prominenti hanno probabilità di click maggiore
- Anchor text — la lunghezza e la rilevanza del testo di ancoraggio influenzano il peso; anchor generici come “clicca qui” pesano meno di anchor text descrittivi
- Contesto circostante — un link inserito in un paragrafo tematicamente rilevante pesa più di un link in una lista generica
- Tipo di elemento HTML — link di navigazione ripetuti su tutte le pagine (menu, breadcrumb) pesano meno di link editoriali unici nel corpo del testo
Implicazioni pratiche per l’architettura dei link interni
Il Reasonable Surfer Model ha conseguenze dirette sulla strategia di internal linking:
- I link editoriali nel corpo del testo trasferiscono più PageRank rispetto ai link nel menu di navigazione
- I link con anchor text rilevante e descrittivo trasferiscono più valore rispetto ad anchor generici
- La posizione del link nella pagina conta: link nella parte alta del contenuto hanno più peso
- Un link contestualizzato in un paragrafo tematicamente coerente trasferisce più PageRank di un link isolato in una lista di risorse
Questi principi vanno oltre la semplice “distribuzione di link equity” e suggeriscono che la qualità del posizionamento di un link all’interno della pagina è tanto importante quanto la quantità di link stessa.
Varianti avanzate del PageRank
Topic-Sensitive PageRank
Nel 2002 Taher Haveliwala, ricercatore a Stanford, pubblicò “Topic-Sensitive PageRank” (ACM International Conference on World Wide Web, 2002), proponendo un’evoluzione significativa: invece di calcolare un unico vettore di PageRank globale, calcolare vettori multipli, ciascuno orientato verso un topic specifico (sport, tecnologia, finanza, etc.).
Quando un utente esegue una query, il sistema determina il topic della query tramite un classificatore e combina i vettori di PageRank in modo ponderato. Il risultato è un ranking più rilevante per query ambigue o topic-specifiche. Questo approccio ha anticipato la direzione che Google avrebbe poi preso con i sistemi di comprensione semantica e topicale.
TrustRank
Il TrustRank, proposto nel 2004 da ricercatori di Stanford e Yahoo, affronta il problema dello spam. L’idea: partire da un set di seed pages manualmente verificate come affidabili (siti governativi, università, testate giornalistiche) e propagare la fiducia attraverso il grafo dei link.
Le pagine vicine (in termini di link) alle seed pages ricevono un punteggio di trust alto. Le pagine spam, che tendono a trovarsi nella periferia del grafo, ricevono un trust basso. A differenza del PageRank generico, il TrustRank è specificamente progettato per identificare e declassare lo spam.
PageRank personalizzato
Il Personalized PageRank (PPR) modifica il vettore di teletrasporto: invece di redistribuire uniformemente a tutte le pagine, il teletrasporto è orientato verso le pagine preferite dall’utente (basandosi sulla cronologia di navigazione, pagine preferite o profilo di interessi). Il risultato è un ranking personalizzato per ogni utente. Questo concetto è alla base dei sistemi di raccomandazione e della personalizzazione dei risultati di ricerca.
Il PageRank è ancora usato da Google?
La risposta breve è: sì. Nonostante il PageRank pubblico sia stato eliminato nel 2016, l’algoritmo — in versioni evolute — continua a essere parte integrante del sistema di ranking di Google.
Conferme ufficiali
Le dichiarazioni più significative da parte di ingegneri Google:
- Gary Illyes (2016–2017): confermò su X (allora Twitter) che dopo 18 anni Google continuava a utilizzare il PageRank come segnale di ranking, insieme a centinaia di altri segnali
- Gary Illyes (2024): dichiarò che i link sono importanti, ma che le persone sopravvalutano la loro importanza. A suo avviso i link non rientrano nei primi 3 fattori di ranking
- Google SEO Starter Guide (2024): la versione aggiornata della guida ufficiale SEO di Google menziona esplicitamente il PageRank come segnale utilizzato
Il leak delle API Google (marzo 2024)
Nel marzo 2024 sono trapelati documenti interni delle API di Google Search che hanno rivelato l’esistenza di varianti multiple del PageRank ancora attive nei sistemi interni:
- RawPagerank — il PageRank calcolato dal grafo dei link, senza aggiustamenti
- PageRank2 — una versione evoluta con parametri diversi
- Altre varianti specifiche per sottosistemi di ranking
Questo leak ha confermato in modo inequivocabile ciò che molti sospettavano: il PageRank non è un concetto del passato, ma un componente attivo dell’infrastruttura di ranking di Google, seppur evoluto e integrato con decine di altri segnali.
I redirect non perdono PageRank
Una conferma pratica importante arrivò nel 2016, quando Gary Illyes dichiarò che i redirect 301, 302 e 30x non causano più perdita di PageRank. In passato si riteneva che un redirect 301 disperdesse circa il 15% del PageRank — oggi questa perdita non c’è più. Per approfondire la gestione corretta dei redirect, incluse le differenze tecniche tra i vari codici, rimandiamo alla guida dedicata.
L’evoluzione del nofollow e il flusso di PageRank
L’introduzione (2005)
Nei primi mesi del 2005 Google introdusse l’attributo rel="nofollow" per i link HTML, su proposta di Matt Cutts (Google) e Jason Shellen (Blogger). L’obiettivo era combattere lo spam nei commenti dei blog: i link con nofollow non avrebbero trasferito PageRank alla pagina di destinazione. Yahoo e Bing adottarono lo stesso standard.
Da settembre 2005 Google iniziò a raccomandare l’uso di nofollow anche per i link a pagamento e sponsorizzati, estendendo il caso d’uso oltre la semplice prevenzione dello spam.
La fine del PageRank sculpting (2009)
Tra il 2005 e il 2009 si diffuse la pratica del PageRank sculpting: i webmaster usavano il nofollow sui link interni meno importanti (pagine legal, login, etc.) per concentrare tutto il PageRank sulle pagine strategiche.
Il 15 giugno 2009 Matt Cutts annunciò un cambiamento radicale: Google avrebbe smesso di redistribuire il PageRank “risparmiato” dai link nofollow. Il nuovo comportamento:
- Il PageRank totale della pagina viene diviso tra tutti i link, sia dofollow che nofollow
- La quota destinata ai link nofollow evapora: non viene trasferita alla pagina di destinazione, né redistribuita ai link dofollow
- Di conseguenza, usare nofollow su link interni non concentra il PageRank ma lo disperde
Questo cambiamento pose fine definitiva al PageRank sculpting come strategia SEO.
I nuovi attributi (settembre 2019)
Il 10 settembre 2019 Google annunciò tre attributi per i link, in sostituzione dell’unico nofollow:
rel="sponsored"— per link a pagamento, sponsorizzazioni, pubblicitàrel="ugc"— per link in contenuti generati dagli utenti (commenti, forum, wiki)rel="nofollow"— per tutti gli altri casi in cui non si vuole passare link equity
Il cambiamento più significativo: tutti e tre gli attributi passarono da direttive a hint. Google poteva ora scegliere se seguire o meno un link nofollow, sia per il crawling (dal 1° marzo 2020) sia per il ranking. Per un approfondimento completo sulle differenze e l’utilizzo corretto di questi attributi, vedi la guida dedicata a nofollow, ugc e sponsored.
Impatto pratico sulla distribuzione di link equity oggi
Nel 2026 il quadro è chiaro:
- Il nofollow non è più una direttiva assoluta — Google può decidere autonomamente di seguire il link e trasferire segnali
- Usare nofollow su link interni è quasi sempre controproducente — disperde PageRank senza beneficio
- Il
rel="sponsored"è obbligatorio per i link a pagamento: non usarlo espone a rischi di penalizzazione - L’uso corretto degli attributi fornisce a Google contesto sulla natura del link, aiutandolo a valutare meglio il grafo dei link
PageRank e link building nel 2026
Qualità > quantità: il paradigma attuale
L’approccio ai link è cambiato radicalmente rispetto all’era del PageRank pubblico. La quantità di backlink è un segnale debole; ciò che conta è la rilevanza tematica, l’autorevolezza della fonte e il contesto editoriale in cui il link è inserito.
Un singolo link editoriale da una testata giornalistica di settore trasferisce più valore di centinaia di link da directory generiche o blog di bassa qualità. I principi del Reasonable Surfer Model si applicano anche ai backlink: un link prominente, in un contesto rilevante, con anchor text descrittivo, trasferisce più PageRank.
Gli aggiornamenti anti-spam di Google (2022–2025)
Google ha intensificato significativamente la lotta contro la manipolazione dei link:
- Dicembre 2022 — Link Spam Update: introduzione di SpamBrain, un sistema basato su AI per identificare link innaturali, link farm e PBN (Private Blog Networks). Il rollout durò 29 giorni
- Marzo 2024 — Spam Update: targeting di contenuti AI-generated a scala e pratiche manipolative di link building
- 2023–2025: molteplici core update che hanno progressivamente deindicizzato reti di link farm e ridotto il peso dei link da domini non rilevanti
SpamBrain è il sistema chiave: utilizza machine learning per identificare pattern di link innaturali, sia a livello di singolo link che di rete. Include la capacità di individuare sia i siti che vendono link sia quelli che li acquistano.
Manipolazione dei link: rischi attuali
Google identifica e penalizza diverse pratiche manipolative:
- Compravendita di link con il fine di influenzare il ranking
- Scambi di link eccessivi o reciproci su larga scala
- Link building automatizzata tramite software o bot
- Uso di PBN (Private Blog Networks)
- Guest posting su scala con link manipolativi
- Link da siti con contenuti auto-generati o thin content
Le conseguenze vanno dalla semplice svalutazione dei link (Google li ignora) alla penalizzazione manuale del sito tramite azione manuale notificata in Search Console. Lo strumento Disavow Tool resta disponibile per dissociarsi da link tossici, ma va usato con cautela e come ultima risorsa dopo aver tentato la rimozione diretta dei link.
Strategie legittime per acquisire link equity
Le strategie di link building che funzionano nel 2026 si basano sulla creazione di valore reale:
- Contenuti linkabili — ricerche originali, guide tecniche approfondite, tool gratuiti, dataset pubblici
- Digital PR — relazioni con testate di settore, comunicati basati su dati proprietari
- Contributi di expertise — citazioni come esperti, interviste, partecipazione a conferenze di settore
- Broken link building — identificare link rotti su siti autorevoli e proporre il proprio contenuto come sostituto
- Link earning passivo — produrre contenuti talmente utili e completi che attraggano link spontaneamente
PageRank e internal linking
Come distribuire il PageRank internamente
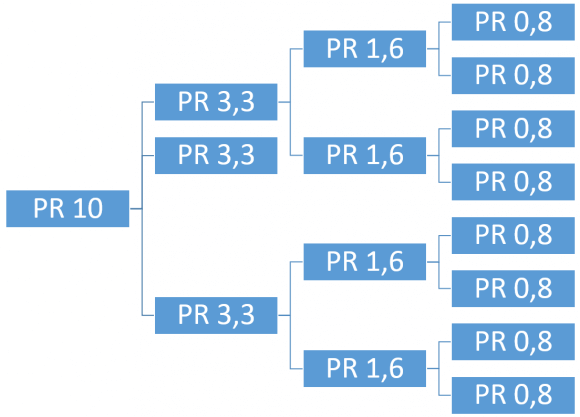
Il PageRank non è solo questione di backlink esterni. La struttura dei link interni determina come il PageRank acquisito dall’esterno viene distribuito all’interno del sito. Un sito che riceve molti backlink verso la homepage ma non distribuisce quel PageRank tramite link interni efficaci sta sprecando la propria link equity.
Principi chiave per la distribuzione interna del PageRank:
- Flat architecture — le pagine più importanti dovrebbero essere raggiungibili in massimo 3 click dalla homepage
- Link contestuali — i link nel corpo del testo (editoriali) trasferiscono più PageRank dei link di navigazione, come indicato dal Reasonable Surfer Model
- Hub pages — creare pagine hub che aggregano e linkano i contenuti di un cluster tematico, concentrando e ridistribuendo il PageRank
- Proporzionalità — le pagine che generano revenue o traffico dovrebbero ricevere più link interni rispetto a pagine secondarie
Per un approccio avanzato alla visualizzazione e analisi del grafo dei link interni con calcolo del PageRank, vedi la guida su come visualizzare il grafo dei link interni con PageRank in Python.
Struttura del sito e architettura dell’informazione
L’architettura dell’informazione ha un impatto diretto sulla distribuzione del PageRank:
- Struttura a silos — organizzare i contenuti in cluster tematici collegati internamente, con una pagina pillar che funge da hub per il topic
- Breadcrumb — i link nella breadcrumb navigation distribuiscono PageRank lungo la gerarchia del sito, dalle pagine profonde verso le categorie
- Paginazione — le paginazioni frammentano il PageRank attraverso le pagine di una serie; valutare se consolidare con lazy loading o “load more” dove possibile
- Canonical — il tag canonical consolida i segnali di PageRank verso la URL preferita quando esistono versioni duplicate di una pagina
Errori comuni che disperdono link equity
- Pagine orfane — pagine senza link interni che le puntano: ricevono solo il PageRank di teletrasporto (minimo), come dimostrato nell’esempio numerico precedente
- Catene di redirect — sebbene i singoli redirect non perdano PageRank, catene lunghe (A→B→C→D) aumentano il rischio che Google smetta di seguire la catena. Meglio correggere i redirect interni puntando direttamente alla destinazione finale
- Link a pagine 404 — il PageRank trasferito a una pagina inesistente è perso. Monitorare gli errori 404 e implementare redirect appropriati
- Nofollow su link interni — come visto, disperde PageRank senza redistribuirlo. Eliminare i nofollow dai link interni salvo casi eccezionali (pagine di login, search results interni)
- Eccesso di link in una pagina — con troppi link in uscita, ogni singolo link trasferisce una frazione minima di PageRank. Mantenere i link focalizzati e rilevanti
Miti e realtà sul PageRank
| Mito | Realtà | Fonte |
|---|---|---|
| Il PageRank è morto | Falso. Non è più visibile pubblicamente ma è ancora utilizzato internamente da Google. Il leak 2024 conferma l’esistenza di varianti attive (RawPagerank, PageRank2). | Google API leak 2024; Gary Illyes 2016–2017 |
| Tutti i link passano lo stesso PageRank | Falso. Il Reasonable Surfer Model (brevetto 2010) assegna pesi diversi ai link in base a posizione, anchor text, prominenza visiva e contesto. | U.S. Patent 8,117,209 |
| I redirect 301 perdono PageRank | Falso (dal 2016). Gary Illyes ha confermato che 301, 302 e 30x non causano più perdita di PageRank. | Gary Illyes, Search Engine Land 2016 |
| I link sono il fattore di ranking #1 | Falso. Gary Illyes ha dichiarato che i link non rientrano nei primi 3 fattori di ranking. Sono importanti ma non dominanti. | Gary Illyes, PubCon 2024 |
| Il nofollow blocca completamente il trasferimento di PageRank | Non più dal 2019. Da settembre 2019, nofollow è un “hint”: Google può scegliere di ignorare l’attributo sia per il crawling che per il ranking. | Google Search Central Blog, settembre 2019 |
| Più link = più PageRank | Parzialmente vero, ma fuorviante. La qualità, la rilevanza tematica e il contesto editoriale contano molto più del numero. Un link da un sito autorevole e tematicamente affine vale più di migliaia di link da siti generici. | Reasonable Surfer Model; SpamBrain |
| Il PageRank della homepage indica l’authority del sito | Semplificazione eccessiva. Il PageRank è calcolato a livello di pagina, non di sito. Pagine interne con molti backlink possono avere PageRank superiore alla homepage. | Paper originale Brin & Page, 1998 |
Note storiche
Per completezza, alcuni concetti storici legati al PageRank che non sono più rilevanti operativamente ma hanno avuto un ruolo significativo nell’evoluzione della SEO.
SERP Rank vs PageRank
In passato si distingueva tra “SERP Rank” (il posizionamento effettivo nei risultati di ricerca) e “PageRank” (il punteggio di autorevolezza basato sui link). Questa distinzione era necessaria perché molti webmaster confondevano i due concetti: un alto PageRank non garantiva un alto posizionamento in SERP, poiché il ranking dipende da centinaia di fattori oltre al PageRank.
Google Directory
La Google Directory, lanciata nel 2000 e basata sui dati di DMOZ (Open Directory Project), utilizzava un sistema simile al PageRank per ordinare i risultati per rilevanza all’interno delle categorie. Il servizio fu chiuso a luglio 2011, vittima della superiorità del motore di ricerca rispetto alle directory editoriali.
PageRank spoofed
Quando il PageRank era visibile nella Toolbar, era possibile “truccare” il valore mostrato sfruttando i redirect HTTP 302 e i meta refresh: redirezionando una pagina verso un sito con PR alto (es. google.com), la pagina di partenza ereditava il valore di PR della destinazione nella Toolbar. Questa vulnerabilità, nota come “PR spoofing”, fu corretta da Google e oggi non è più riproducibile.
Fonti e riferimenti
Paper accademici
- Page, L., Brin, S., Motwani, R., Winograd, T. (1998). “The Anatomy of a Large-Scale Hypertextual Web Search Engine“. Computer Networks and ISDN Systems, 30, 107-117
- Haveliwala, T. (2002). “Topic-Sensitive PageRank“. ACM International Conference on World Wide Web
- Gyöngyi, Z., Garcia-Molina, H., Pedersen, J. (2004). “Combating Web Spam with TrustRank”. Stanford University / Yahoo Research
Brevetti
- US6285999 B1 — “Method for node ranking in a linked database” (PageRank originale, scaduto settembre 2019)
- US8117209 B1 — “Ranking documents based on user behavior and feature data” (Reasonable Surfer Model, 2010)
Documentazione ufficiale Google
- Evolving “nofollow” – new ways to identify the nature of links — Google Search Central Blog, settembre 2019
- December 2022 link spam update — Google Search Central Blog
- Google Search spam updates — cronologia aggiornamenti anti-spam
Dichiarazioni ingegneri Google
- Gary Illyes (2016): i redirect 30x non causano perdita di PageRank — Search Engine Land
- Gary Illyes (2024): i link non sono un fattore top-3 di ranking — Search Engine Land
Risorse tecniche
Articoli correlati
Autore

Mi chiamo Giovanni Sacheli e dal 2009 aiuto le aziende a farsi trovare online. Sono specializzato in SEO tecnica e PPC, competenze che applico quotidianamente nella mia agenzia, Searcus Swiss Sagl. Mi piace sviluppare strumenti a supporto del mio lavoro, ho creato SEOdata.app e cluster.army e co-scritto il libro SEO Audit Avanzato. Curo maniacalmente questo blog per colleghi e appassionati, dove mi "appunto" quello che imparo. Sono un NERD anni '80, motociclista e orgoglioso papà di due bambini.
Link:
Giovanni Sacheli
SEO Audit Avanzato
Searcus Swiss Sagl
SEOdata.app
cluster.army
Commenti |2
Lascia un commentowow che compendio, me lo sono letto tutto di un fiato :) ottimo per la mia ricerca, grazie mille Giovanni!
Grazie Giannino spero prenderai un gran voto per la tua ricerca! Sono felice quando trovo appassionati di SEO :D