Ogni navigazione tra pagine web implica una sequenza di operazioni: risoluzione DNS, handshake TCP/TLS, fetch del documento HTML, download delle subresource e rendering completo. Anche su connessioni veloci, questa catena introduce centinaia di millisecondi di latenza percepita dall’utente. Il caricamento speculativo (speculative loading) è l’insieme di tecniche che permettono al browser di anticipare la prossima navigazione dell’utente, preparando risorse o intere pagine prima che il click avvenga.
Dall’esperienza diretta nell’ottimizzazione di siti con milioni di pagine, il caricamento speculativo è una delle leve più sottoutilizzate per ridurre il tempo al primo byte (TTFB) percepito nella navigazione intra-sito. In questa guida analizzo l’evoluzione completa delle tecniche disponibili: dalle legacy Resource Hints (prefetch, prerender) fino alla moderna Speculation Rules API, con codice, dati e strategie di implementazione per ambienti di produzione.
Evoluzione del caricamento speculativo nei browser
Da Resource Hints a Speculation Rules: la timeline
Il caricamento speculativo nei browser ha attraversato tre generazioni distinte. Comprendere questa evoluzione è essenziale per scegliere la tecnica corretta nel contesto attuale.
- 2011 — Chrome introduce
<link rel="prerender">: il browser crea una tab nascosta e renderizza l’intera pagina in background, inclusa l’esecuzione JavaScript. - 2014 — Il W3C pubblica la bozza della specifica Resource Hints, formalizzando
dns-prefetch,preconnect,prefetcheprerendercome hint dichiarativi per il browser. - 2017 — Chrome 63 depreca il prerender completo e lo sostituisce con No-State Prefetch: il tag
<link rel="prerender">continua a esistere ma il comportamento cambia radicalmente. - 2022 — Chrome 108 introduce la Speculation Rules API con supporto per prefetch tramite una nuova sintassi JSON dichiarativa.
- 2023 — Chrome 121 aggiunge il supporto per prerender, document rules e il parametro
eagerness, rendendo l’API completa. - 2024 — Google Search inizia a usare le Speculation Rules nelle proprie SERP per prerenderizzare il primo risultato di ricerca.
- 2025 — L’API è stabile su tutti i browser basati su Chromium. Firefox e Safari non la supportano ancora, ma il fallback ai Resource Hints classici garantisce compatibilità.
Questa evoluzione riflette il passaggio da meccanismi semplici ma limitati (un singolo hint HTML) a un sistema programmabile e granulare che gestisce il caricamento speculativo in base a regole condizionali, livelli di urgenza e protocolli HTTP moderni.
Prefetch: come funziona e quando usarlo
Il meta tag link rel=”prefetch”
Il prefetch è incluso nelle specifiche WHATWG HTML. Indica al browser di scaricare una risorsa a priorità idle — ovvero solo dopo che il caricamento della pagina corrente è completato. La risorsa viene salvata nella HTTP cache del browser per una navigazione futura.
A differenza del preload (che forza il download di risorse per la pagina corrente), il prefetch prepara risorse per una pagina successiva. Questa distinzione è fondamentale: usare preload al posto di prefetch spreca banda e compete con le risorse critiche della pagina attiva.
<!-- Prefetch di un documento HTML per la prossima navigazione -->
<link rel="prefetch" href="/next-page/" as="document">
<!-- Prefetch di una risorsa specifica (immagine, font, script) -->
<link rel="prefetch" href="/assets/hero-image.webp" as="image">L’attributo as indica al browser il tipo di risorsa attesa, permettendo di applicare la corretta Content Security Policy e prioritizzazione.
Prefetch via intestazione HTTP Link
Il prefetch può essere dichiarato anche tramite l’intestazione HTTP Link, approccio più efficiente perché il browser processa l’header prima ancora di parsare l’HTML. È particolarmente utile per le risorse che devono essere pre-caricate senza modificare il template della pagina — ad esempio tramite configurazione server-side degli header HTTP.
Link: </next-page/>; rel=prefetch; as=document
Link: </assets/critical-font.woff2>; rel=prefetch; as=font; crossoriginCosa viene effettivamente scaricato
Con as="document", il browser scarica solo il documento HTML. Le subresource (CSS, JS, immagini) non vengono recuperate fino alla navigazione effettiva. La risposta viene conservata nella HTTP cache seguendo le normali direttive di Cache-Control: se la risorsa ha un max-age attivo, verrà servita dalla cache locale al momento della navigazione.
Nota: il prefetch non garantisce che la risorsa sarà ancora in cache al momento della navigazione. Se passa troppo tempo o se il browser ha bisogno di liberare memoria, la risorsa prefetchata potrebbe essere eliminata dalla cache.
Limiti e comportamento cross-origin
Il prefetch cross-origin funziona, ma con restrizioni. La richiesta viene inviata senza cookie e include l’header Sec-Purpose: prefetch, che permette al server di riconoscere la natura speculativa della richiesta. Il server può rifiutarla restituendo un codice di stato non-2xx.
Il supporto browser per il prefetch è praticamente universale: Chrome, Firefox, Edge e Opera lo supportano. Safari ha aggiunto il supporto dalla versione 17.0.
Prerender: storia, deprecazione e No-State Prefetch
Il vecchio link rel=”prerender” (2011-2017)
Il prerender originale, introdotto da Chrome nel 2011, era la tecnologia più aggressiva tra le Resource Hints. Il browser creava una tab nascosta e vi caricava l’intera pagina: download di tutte le subresource, esecuzione JavaScript, costruzione del DOM e rendering completo del layout. Quando l’utente cliccava il link, Chrome sostituiva il contenuto della tab attiva con quello pre-renderizzato, producendo una navigazione percepita come istantanea.
<!-- Prerender legacy: il browser crea una tab nascosta completa -->
<link rel="prerender" href="https://example.com/next-page/">Questa tecnologia alimentava anche “Google Search with Instant Pages”, dove Google prerenderizzava il primo risultato di ricerca direttamente dalla SERP:
No-State Prefetch in Chrome 63+
Da dicembre 2017, Chrome ha sostituito il prerender completo con il No-State Prefetch. Il tag <link rel="prerender"> continua a essere accettato dal parser HTML, ma il comportamento è radicalmente diverso: Chrome esegue solo uno scan leggero dell’HTML della pagina target per identificare le subresource (CSS, JS, font, immagini) e le scarica in anticipo. Non esegue JavaScript, non costruisce il DOM e non renderizza nulla.
In pratica, dal 2017 al 2022, il tag <link rel="prerender"> in Chrome eseguiva un’operazione equivalente a un prefetch avanzato, non un vero prerender. Chi continuava a usarlo pensando di ottenere un rendering completo in background, otteneva un beneficio limitato al pre-download delle risorse. Comprendere come viene generata una pagina web aiuta a capire quante fasi del rendering pipeline venivano saltate dal No-State Prefetch.
Perché il prerender classico è stato abbandonato
Il prerender originale è stato deprecato per tre ragioni tecniche:
- Consumo di memoria eccessivo — Creare una tab nascosta completa equivaleva ad aprire una pagina aggiuntiva. Su dispositivi con RAM limitata, questo poteva degradare le prestazioni dell’intera sessione di navigazione, vanificando il beneficio. Il costo in termini di rendering budget era troppo elevato per un’azione speculativa.
- Side effects dall’esecuzione JavaScript — Script di analytics, tracking pixel, timer, WebSocket e qualsiasi codice con effetti collaterali venivano eseguiti nella tab nascosta. Questo causava double-counting nelle metriche, attivazione prematura di session timeout e comportamenti imprevedibili.
- Rischi di sicurezza cross-origin — L’esecuzione completa di una pagina in background creava superfici di attacco: un sito malevolo poteva sfruttare il prerender per eseguire codice nel contesto del browser senza interazione esplicita dell’utente.
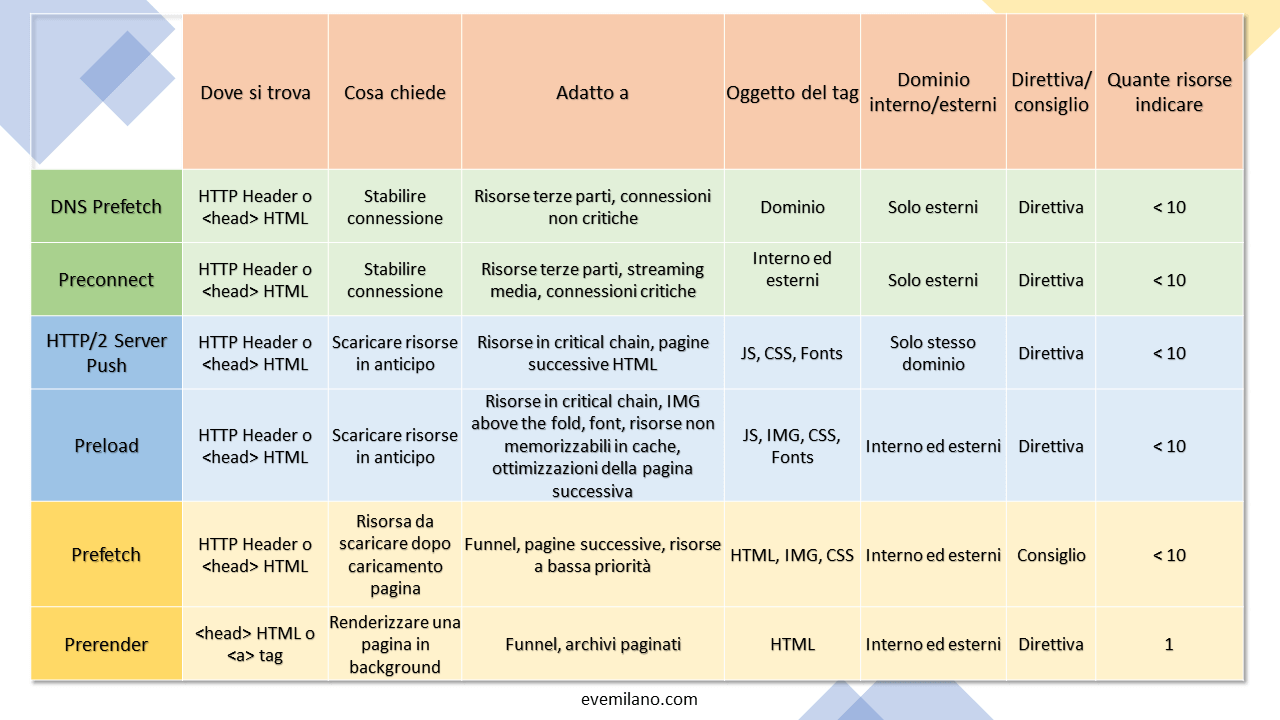
Resource Hints a confronto: preload, preconnect, dns-prefetch, prefetch e prerender
Prima di analizzare la Speculation Rules API, è utile avere una visione d’insieme di tutte le Resource Hints disponibili. La tabella seguente confronta le tecniche per scope, comportamento e caso d’uso ottimale. Per approfondimenti su ciascuna tecnica, consulta le guide dedicate su Preload, Preconnect e dns-prefetch e Early Hints 103.
| Hint | Scope | Cosa fa | Quando usarlo | Priorità |
|---|---|---|---|---|
dns-prefetch | Origin | Risolve il DNS | Domini terzi usati nella pagina | Bassa |
preconnect | Origin | DNS + TCP + TLS | Font, CDN, API esterne critiche | Media |
prefetch | Risorsa/Documento | Scarica risorsa per navigazione futura | Pagina successiva probabile | Idle |
preload | Risorsa | Scarica risorsa per la pagina corrente | Font, CSS critici, LCP image | Alta |
prerender (legacy) | Documento | No-State Prefetch (dal 2017) | Deprecato — usare Speculation Rules | Idle |
modulepreload | Modulo JS | Scarica e compila modulo ES | Moduli JS della pagina corrente | Alta |
La distinzione chiave è tra hint per la pagina corrente (preload, preconnect, dns-prefetch, modulepreload) e hint per la navigazione futura (prefetch, prerender). Confondere i due ambiti è un errore comune che produce risultati opposti a quelli desiderati.
Speculation Rules API: il nuovo standard
La Speculation Rules API è il meccanismo moderno per dichiarare prefetch e prerender nei browser Chromium. A differenza dei Resource Hints classici (un singolo tag HTML per una singola risorsa), le Speculation Rules permettono di definire regole condizionali in formato JSON che il browser applica automaticamente ai link presenti nella pagina.
Sintassi JSON e implementazione inline
Le regole vengono inserite in un elemento <script type="speculationrules">. Il browser ignora i tipi di script sconosciuti, quindi i browser che non supportano l’API semplicemente saltano il blocco — il progressive enhancement è nativo.
<script type="speculationrules">
{
"prefetch": [
{
"source": "list",
"urls": ["/pagina-successiva/", "/checkout/"]
}
],
"prerender": [
{
"source": "list",
"urls": ["/pagina-piu-probabile/"],
"eagerness": "moderate"
}
]
}
</script>Il JSON accetta due azioni principali: prefetch (scarica il documento) e prerender (scarica e renderizza completamente, incluso JavaScript). A differenza del legacy <link rel="prerender">, il prerender via Speculation Rules esegue un vero rendering completo in un frame nascosto, con gestione sicura dei side effects.
Nota: se la Content Security Policy della pagina usa la direttiva script-src, è necessario aggiungere 'inline-speculation-rules' oppure il nonce/hash corrispondente.
Implementazione via header HTTP Speculation-Rules
Per ambienti in cui modificare l’HTML non è pratico, le regole possono essere distribuite tramite un response header che punta a un file JSON esterno. Questo approccio è ideale per la configurazione centralizzata su Nginx o altri reverse proxy.
# Response header che punta al file delle regole
Speculation-Rules: "/rules/speculation.json"
# Il file deve essere servito con il Content-Type corretto:
# Content-Type: application/speculationrules+jsonList Rules vs Document Rules
La proprietà source determina come vengono selezionati gli URL candidati:
"source": "list"— Array esplicito di URL, definito dall’autore della pagina. Adatto quando conosci a priori gli URL candidati (es. step successivo di un wizard, pagina checkout, articolo correlato specifico)."source": "document"— Il browser scopre automaticamente i link candidati analizzando gli elementi<a>nel DOM della pagina. Le condizioni di selezione sono definite tramite clausolewhere. Questo approccio scala automaticamente al variare dei contenuti della pagina.
Il parametro eagerness
Il parametro eagerness controlla quando il browser avvia la speculazione. È il meccanismo chiave per bilanciare reattività e consumo di risorse.
| Valore | Trigger | Latenza tipica | Uso consigliato |
|---|---|---|---|
immediate | Appena le regole vengono parsate | 0 ms | List rules con poche URL ad alta probabilità |
eager | Appena possibile (attualmente = immediate) | 0 ms | Equivalente a immediate nelle implementazioni attuali |
moderate | Hover su link per 200 ms (desktop) o touchstart (mobile) | ~200 ms | Document rules — bilanciamento tra copertura e risorse |
conservative | Pointer down o touch down | ~80 ms | Document rules — minimo spreco, massima probabilità |
Il default per le list rules è immediate, per le document rules è conservative. In scenari reali, moderate offre il miglior rapporto costo/beneficio per le document rules: 200 ms di hover coprono la maggior parte delle interazioni reali e lasciano tempo sufficiente al browser per completare il prefetch prima del click.
Limiti di Chrome: quante speculazioni simultanee
Chrome impone limiti al numero di speculazioni attive contemporaneamente per evitare consumo eccessivo di memoria e banda.
| Eagerness | Prefetch max | Prerender max | Comportamento al limite |
|---|---|---|---|
immediate / eager | 50 | 10 | Limite fisso, le speculazioni in eccesso vengono ignorate |
moderate / conservative | 2 | 2 | FIFO: la nuova speculazione cancella la più vecchia |
I limiti per moderate e conservative sono volutamente bassi perché queste speculazioni sono guidate dall’interazione utente (hover, touch) e hanno un tasso di conversione elevato. Il meccanismo FIFO garantisce che la speculazione più recente — e quindi più probabile — sia sempre attiva.
Document Rules: prefetch e prerender automatici basati sul DOM
Le document rules sono la funzionalità più potente della Speculation Rules API. Il browser analizza gli elementi <a> nel DOM della pagina e applica le regole di speculazione ai link che soddisfano le condizioni definite nella clausola where.
Struttura della clausola where
<script type="speculationrules">
{
"prefetch": [
{
"source": "document",
"where": {
"and": [
{ "href_matches": "/*" },
{ "not": { "href_matches": "/logout" } },
{ "not": { "href_matches": "/wp-admin/*" } },
{ "not": { "selector_matches": ".no-prefetch" } }
]
},
"eagerness": "moderate"
}
]
}
</script>Questa regola esegue il prefetch di tutti i link interni al sito, escludendo la pagina di logout, l’area di amministrazione e i link con classe .no-prefetch. L’eagerness: moderate attiva il prefetch solo dopo 200 ms di hover.
Pattern matching con href_matches
La condizione href_matches accetta pattern URL con wildcard, simili alla sintassi URLPattern:
"/blog/*"— tutti gli URL che iniziano con /blog/"/products/*/reviews"— le pagine recensioni di qualsiasi prodotto"https://cdn.example.com/*"— URL su un dominio specifico"/*\\?*"— URL con query string (utile per esclusioni)
Selezione con selector_matches
La condizione selector_matches filtra i link in base a selettori CSS applicati sull’elemento <a>:
".prerender-candidate"— link con una classe specifica"[data-prerender]"— link con un data attribute dedicato"nav a"— solo i link nella navigazione principale":not([rel~=nofollow])"— escludere link con rel nofollow
Combinare condizioni con and, or, not
Le condizioni sono componibili tramite operatori logici and, or e not, permettendo regole arbitrariamente complesse:
{
"where": {
"or": [
{ "href_matches": "/blog/*" },
{
"and": [
{ "href_matches": "/servizi/*" },
{ "not": { "selector_matches": ".external" } }
]
}
]
}
}Questa regola seleziona tutti i link del blog oppure i link dell’area servizi che non hanno la classe .external.
Header HTTP per il caricamento speculativo
Sec-Purpose: identificare le richieste speculative
Quando il browser esegue una richiesta speculativa, include l’header Sec-Purpose per informare il server della natura della richiesta. Questo header permette al server di decidere se servire la risorsa, rifiutarla con un codice di stato non-2xx, o registrarla separatamente nei log.
# Header inviato dal browser per una richiesta prefetch
Sec-Purpose: prefetch
# Header inviato per una richiesta prerender
Sec-Purpose: prefetch;prerenderEsempio di configurazione Nginx per separare le richieste speculative nel log:
# nginx.conf - Log separato per richieste speculative
map $http_sec_purpose $is_speculative {
default 0;
"~prefetch" 1;
}
server {
# Log richieste speculative su file separato
access_log /var/log/nginx/speculative.log combined if=$is_speculative;
}Supports-Loading-Mode: opt-in per prerender cross-origin
Il prerender cross-origin (stesso sito, origin diversa) richiede un opt-in esplicito dal server di destinazione tramite l’header:
Supports-Loading-Mode: credentialed-prerenderSenza questo header, Chrome annulla il prerender cross-origin per ragioni di sicurezza. È necessario solo quando origin di partenza e destinazione differiscono (es. www.example.com → shop.example.com).
Invalidare le speculazioni dopo cambiamenti di stato
Dopo azioni che modificano lo stato dell’utente (logout, modifica carrello, cambio lingua), le pagine prerenderizzate potrebbero contenere dati obsoleti. L’header Clear-Site-Data può essere usato per invalidare le risorse speculative in cache.
Rilevare prefetch e prerender lato client
document.prerendering e prerenderingchange
JavaScript ha accesso a proprietà e eventi specifici per rilevare lo stato di prerendering e gestire correttamente analytics, tracker e side effects:
// Verificare se la pagina è in fase di prerender
if (document.prerendering) {
// Differire analytics e side effects fino all'attivazione
document.addEventListener("prerenderingchange", () => {
initAnalytics();
trackPageView();
}, { once: true });
} else {
// Pagina caricata normalmente
initAnalytics();
trackPageView();
}L’evento prerenderingchange viene emesso nel momento esatto in cui la pagina prerenderizzata diventa visibile all’utente (attivazione). Questo è il punto corretto per registrare la page view nei sistemi di analytics.
Performance API e activationStart
La Performance API espone il timestamp di attivazione, utile per misurare il beneficio effettivo del prerender:
const navEntry = performance.getEntriesByType("navigation")[0];
if (navEntry.activationStart > 0) {
const tempoPrerender = Math.round(navEntry.activationStart);
console.log(`Pagina prerenderizzata ${tempoPrerender} ms prima dell'attivazione`);
// Calcolare LCP effettivo per una pagina prerenderizzata
const lcpObserver = new PerformanceObserver((list) => {
const entries = list.getEntries();
const lastEntry = entries[entries.length - 1];
const lcpAdjusted = lastEntry.startTime - navEntry.activationStart;
console.log(`LCP percepito: ${Math.round(lcpAdjusted)} ms`);
});
lcpObserver.observe({ type: "largest-contentful-paint", buffered: true });
}deliveryType per il prefetch
Per le navigazioni prefetchate (senza prerender completo), la proprietà deliveryType della Navigation Timing Entry identifica l’origine della risorsa:
const navEntry = performance.getEntriesByType("navigation")[0];
if (navEntry.deliveryType === "navigational-prefetch") {
console.log("Questa navigazione ha usato un documento prefetchato");
}Feature detection per progressive enhancement
Per inserire dinamicamente regole di speculazione con fallback per browser non supportati, si usa la feature detection tramite HTMLScriptElement.supports(). Questo approccio è particolarmente utile in contesti dove il caricamento degli script segue pattern async e defer.
if (
HTMLScriptElement.supports &&
HTMLScriptElement.supports("speculationrules")
) {
// Browser supporta Speculation Rules: inserire regole dinamiche
const rules = document.createElement("script");
rules.type = "speculationrules";
rules.textContent = JSON.stringify({
prefetch: [{
source: "document",
where: { href_matches: "/*" },
eagerness: "moderate"
}]
});
document.head.append(rules);
} else {
// Fallback: link rel="prefetch" per singola risorsa
const link = document.createElement("link");
link.rel = "prefetch";
link.href = "/next-page/";
link.as = "document";
document.head.append(link);
}Casi in cui il prerender non funziona o viene annullato
Il prerender via Speculation Rules è più robusto del predecessore, ma opera comunque sotto vincoli precisi. JavaScript in contesti complessi rimane una variabile critica.
API differite durante il prerendering
Diverse Web API sono differite (non eseguite) fino al momento dell’attivazione della pagina prerenderizzata. Questo previene i side effects che avevano causato la deprecazione del prerender originale:
- Geolocation —
getCurrentPosition()ewatchPosition()restituiscono solo dopo l’attivazione - Media Devices —
getUserMedia()eenumerateDevices()sono sospesi - Notifications —
requestPermission()viene differita - Service Worker —
navigator.serviceWorker.register()è posticipata all’attivazione - Dialog modali —
alert(),confirm(),prompt()sono no-op durante il prerender - window.open() — differita fino all’attivazione
- Web Bluetooth, HID, Serial, USB — tutti sospesi
- Payment Request API — sospesa per ragioni di sicurezza
URL e condizioni che annullano il prerender
Il browser annulla o rifiuta il prerender nei seguenti casi:
- Navigazione cross-site (eTLD+1 diverso dal sito corrente)
- URL con schema
javascript:,data:oblob: - Download link (risposta con
Content-Disposition: attachment) - Risposta con codice di stato non-2xx
- Pagina con
<meta name="robots" content="noarchive"> - Modalità Data Saver attiva nel browser
- Memory pressure — il sistema ha poca RAM disponibile
- Impostazione utente “Precarica pagine” disabilitata in Chrome
- Battery saver attivo su dispositivi con batteria scarica
Interazione con Service Worker e bfcache
Durante il prerender, i Service Worker non vengono avviati: le richieste fetch dalla pagina prerenderizzata non passano attraverso il SW. Dopo l’attivazione, il Service Worker prende il controllo normalmente. Le pagine prerenderizzate sono eleggibili per il bfcache (back/forward cache) dopo l’attivazione, il che significa che navigazioni successive avanti/indietro possono beneficiare del doppio caching.
Debugging con Chrome DevTools
Il pannello Speculations in Application
Chrome DevTools include una sezione dedicata al debugging delle speculazioni, accessibile da Application > Background services > Speculative loads. Il workflow di debug è il seguente:
- Apri Chrome DevTools (F12) e vai su Application
- Nella sezione Background services, clicca su Speculative loads
- Visualizza tutte le regole di speculazione parsate dalla pagina
- Per ogni URL candidato, verifica lo stato: Not triggered, Prefetched, Prerendered o Failure
- Clicca sulle singole entry per vedere i motivi di eventuali fallimenti
- Nel tab Network, le richieste speculative mostrano l’header
Sec-Purposenella colonna degli header della richiesta
Per un’analisi più approfondita del rendering, la guida all’analisi del rendering fornisce tecniche complementari.
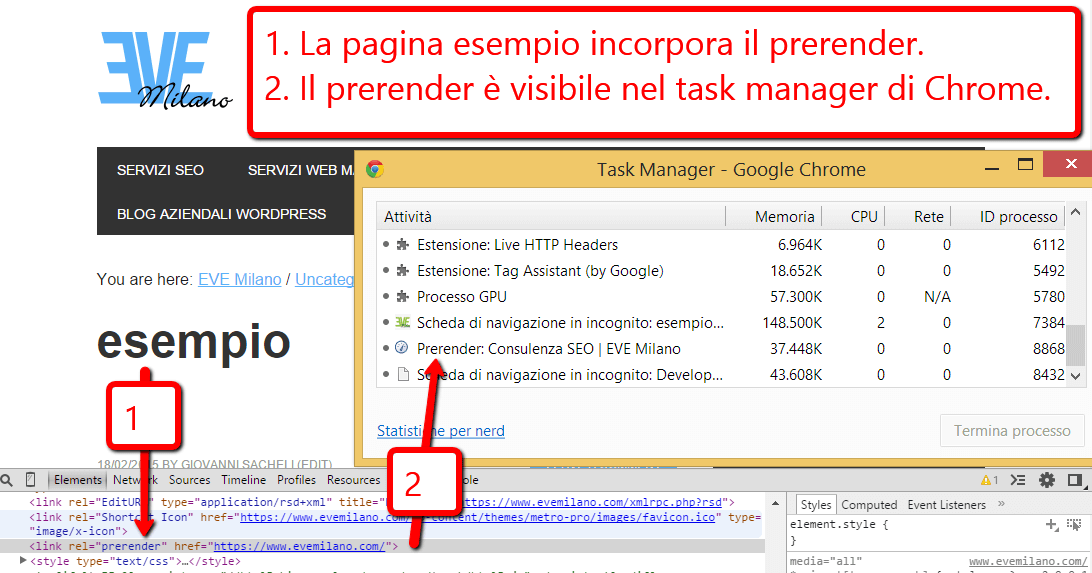
Nota: lo screenshot seguente mostra la verifica del prerender tramite il Task Manager di Chrome, tecnica valida per il prerender legacy. Nelle versioni attuali di Chrome (108+), il pannello Speculative loads in Application offre una diagnostica più dettagliata con stato per ogni URL.
Verificare lo stato delle speculazioni via console
// Leggere tutte le regole di speculazione caricate nella pagina
document.querySelectorAll('script[type="speculationrules"]')
.forEach(r => console.log(JSON.parse(r.textContent)));
// Verificare se la pagina corrente è prerenderizzata
console.log("Prerendering attivo:", document.prerendering);
// Verificare i dati di navigazione
const nav = performance.getEntriesByType("navigation")[0];
console.log("activationStart:", nav.activationStart);
console.log("deliveryType:", nav.deliveryType);Implicazioni SEO del caricamento speculativo
Impatto su crawl budget e rendering budget
Il caricamento speculativo è un’ottimizzazione browser-side che non impatta direttamente su Googlebot. Il crawler di Google non esegue <script type="speculationrules"> e non processa le Resource Hints come farebbe un browser utente. Il crawl budget e il rendering budget non vengono influenzati dalle regole di speculazione.
L’impatto SEO è indiretto ma significativo: il miglioramento della velocità di navigazione percepita riduce i Core Web Vitals (in particolare LCP e INP), che sono segnali di ranking. Su un sito e-commerce dove il prerender riduce l’LCP percepito da 2.5 s a 0.2 s nella navigazione tra listing e scheda prodotto, il beneficio sull’esperienza utente — e quindi sui segnali di engagement — è misurabile.
Come Google Search usa le Speculation Rules
Dal 2024, la pagina dei risultati di Google (google.com/search) include Speculation Rules per prerenderizzare il primo risultato organico. Quando l’utente clicca sul primo link, la pagina si carica in modo percepito come istantaneo perché Chrome l’ha già renderizzata in background. Questo è il successore diretto della tecnologia “Instant Pages” del 2011, implementato con la nuova API.
L’adozione da parte di Google Search è il segnale più forte della maturità e stabilità della Speculation Rules API.
Speculation Rules e WordPress
WordPress ha integrato il supporto ufficiale per le Speculation Rules tramite il plugin Performance Lab (poi incorporato nel modulo Speculation Rules standalone). Il plugin inserisce automaticamente document rules con eagerness moderate per tutti i link interni del sito.
Per implementazioni custom su WordPress, i plugin WordPress Dynamic Prerender e eve_prerender offrono approcci alternativi con maggiore controllo sulle regole di speculazione.
Quale strategia usare: framework decisionale
La scelta della tecnica dipende dallo scenario, dalla prevedibilità della navigazione e dal profilo dell’utente target. La tabella seguente sintetizza i casi d’uso principali.
| Scenario | Tecnica consigliata | Eagerness | Note |
|---|---|---|---|
| Pagina successiva certa (wizard, checkout step 2) | Prerender con list rules | immediate | Massimo beneficio, URL nota a priori |
| Top 2-3 link ad alta probabilità | Prerender con list rules | eager | Max 2-3 URL per limitare risorse |
| Link di navigazione nel documento | Prefetch con document rules | moderate | Bilanciamento copertura/risorse |
| E-commerce: listing → pagina prodotto | Prefetch con document rules | moderate | Escludere add-to-cart e logout |
| Connessioni lente / mobile | Prefetch con document rules | conservative | Minimo spreco di banda |
| Browser non Chromium (Firefox, Safari) | Fallback <link rel="prefetch"> | n/a | Feature detection obbligatoria |
| SSR con navigazione prevedibile | Speculation-Rules via HTTP header | moderate | Configurazione centralizzata su server o CDN |
Regola generale: parti con prefetch e document rules a eagerness moderate per tutti i link interni. Aggiungi prerender con list rules solo per gli URL ad altissima probabilità di navigazione. Monitora l’impatto tramite le Performance API e i dati di Chrome DevTools prima di estendere le regole.
Implementazione pratica: esempi completi
Blog o sito editoriale
Per un blog, la strategia ottimale combina il prerender dell’articolo più letto (o del link di navigazione più probabile) con il prefetch on-hover per tutti i link interni:
<script type="speculationrules">
{
"prerender": [
{
"source": "list",
"urls": ["/blog/articolo-piu-letto/"],
"eagerness": "eager"
}
],
"prefetch": [
{
"source": "document",
"where": {
"and": [
{ "href_matches": "/blog/*" },
{ "not": { "href_matches": "/blog/tag/*" } },
{ "not": { "href_matches": "/blog/category/*" } },
{ "not": { "selector_matches": ".no-prefetch" } }
]
},
"eagerness": "moderate"
}
]
}
</script>E-commerce con pagine prodotto
In un e-commerce, le esclusioni sono critiche: pagine con stato utente (carrello, account, checkout) non devono essere prerenderizzate perché il contenuto dipende dalla sessione.
<script type="speculationrules">
{
"prerender": [
{
"source": "list",
"urls": ["/checkout/step-2/"],
"eagerness": "conservative"
}
],
"prefetch": [
{
"source": "document",
"where": {
"and": [
{ "href_matches": "/prodotti/*" },
{ "not": { "href_matches": "*add-to-cart*" } },
{ "not": { "href_matches": "*logout*" } },
{ "not": { "href_matches": "/account/*" } },
{ "not": { "href_matches": "/carrello/*" } },
{ "not": { "selector_matches": "[rel~=nofollow]" } }
]
},
"eagerness": "moderate"
}
]
}
</script>L’approccio complementare al prefetch speculativo include il lazy loading delle immagini per le risorse below-the-fold: mentre il prefetch accelera la navigazione tra pagine, il lazy loading ottimizza il caricamento della pagina corrente.
SPA e applicazioni JavaScript
Le Speculation Rules sono progettate per MPA (multi-page applications), dove ogni navigazione richiede il fetch di un nuovo documento. Per le SPA con routing client-side (React Router, Vue Router), le navigazioni interne non attivano un fetch del documento e quindi le Speculation Rules non si applicano.
Le architetture ibride SSR/SSG (Next.js, Nuxt, Astro) beneficiano delle Speculation Rules quando la navigazione iniziale è un full document fetch. Il rendering path del CSS critico, analizzato nella guida su come ottimizzare il CSS, rimane una priorità indipendente dal meccanismo di speculazione adottato.
Risorse e specifiche di riferimento
- Chrome: Prerender pages for instant page navigations — Documentazione ufficiale Chrome sulla Speculation Rules API
- WICG: Speculation Rules specification — Specifica tecnica completa dell’API
- web.dev: Speculative loading — Guida pratica all’implementazione
- MDN: rel=prefetch — Riferimento per il prefetch classico
- MDN: Speculation Rules API — Documentazione MDN sull’API
- W3C: Resource Hints specification — Specifica W3C delle Resource Hints legacy
- WHATWG HTML: link type prefetch — Standard HTML per il prefetch
- Can I Use: link-rel-prefetch — Supporto browser per il prefetch
Articoli correlati
Autore

Mi chiamo Giovanni Sacheli e dal 2009 aiuto le aziende a farsi trovare online. Sono specializzato in SEO tecnica e PPC, competenze che applico quotidianamente nella mia agenzia, Searcus Swiss Sagl. Mi piace sviluppare strumenti a supporto del mio lavoro, ho creato SEOdata.app e cluster.army e co-scritto il libro SEO Audit Avanzato. Curo maniacalmente questo blog per colleghi e appassionati, dove mi "appunto" quello che imparo. Sono un NERD anni '80, motociclista e orgoglioso papà di due bambini.
Link:
Giovanni Sacheli
SEO Audit Avanzato
Searcus Swiss Sagl
SEOdata.app
cluster.army