Il revamp dei dati strutturati di un sito complesso — guide, categorie, listing, news, tool, area account — è uno dei lavori più sottovalutati della SEO tecnica. Il validatore Schema.org e il Rich Results Test di Google verificano sintassi e gerarchia, ma non leggono il contesto: un Article con author “Leonardo da Vinci”, un priceValidUntil fissato al 2020, un prezzo in yen miliardari hardcoded nel template, un intero racchiuso tra virgolette che diventa stringa — tutti errori che passano i validatori ufficiali senza un warning.
Nel video qui sotto mostro l’approccio operativo che uso per superare questo limite: un server MCP dedicato a Schema.org collegato a Claude Code, un orchestratore di sub-agenti in parallelo, una doppia validazione e la generazione automatica di un report HTML pronto per gli sviluppatori. In questo articolo trovi la guida tecnica passo passo per replicare la pipeline.
Perché i validatori Schema.org tradizionali non bastano
Il validatore di schema.org/validator e il Rich Results Test sono strumenti di verifica sintattica. Confermano che il markup sia parsabile, che i campi obbligatori per un rich result type siano presenti e che la gerarchia sia formalmente coerente. Quello che non fanno è leggere la pertinenza semantica dei valori inseriti. Per i fondamentali sul ruolo dei dati strutturati nella SEO, parto dal presupposto che tu conosca già concetti come JSON-LD, microdata e rich result.
Esempi reali di errori che passano la validazione ufficiale ma rovinano l’intera implementazione:
- Date hardcoded nei template:
priceValidUntilimpostato al 2020 perché copiato anni fa dalla documentazione e mai parametrizzato. Sintatticamente valido, semanticamente morto. - Tipi numerici stringificati:
"price": "29.90"dove la specifica vuole unNumber, oppure"reviewCount": "1247"con virgolette che lo trasformano in stringa. - Author placeholder dimenticati: l’
Article.author.namecon valori di test (“John Doe”, “Mario Rossi”, o peggio “Leonardo da Vinci”) perché qualcuno ha popolato il template e non l’ha mai connesso al CMS. - Currency mismatch:
priceCurrencyfissato aEURma prezzo inJPY, oppure prezzo che mostra una valuta nella UI e un’altra nel JSON-LD. - Gerarchie incomplete: una scheda prodotto e-commerce dichiara
Productma nonOffer, oppure dichiaraOrganizationsulla home senza sfruttare i tipi più specifici comeOnlineStore.
Per chi gestisce un sito con decine di template diversi, intercettare questi errori richiede ore di lettura manuale del JSON-LD pagina per pagina. È esattamente il tipo di lavoro su cui un LLM con accesso diretto al dizionario Schema.org diventa infinitamente più produttivo di un essere umano.
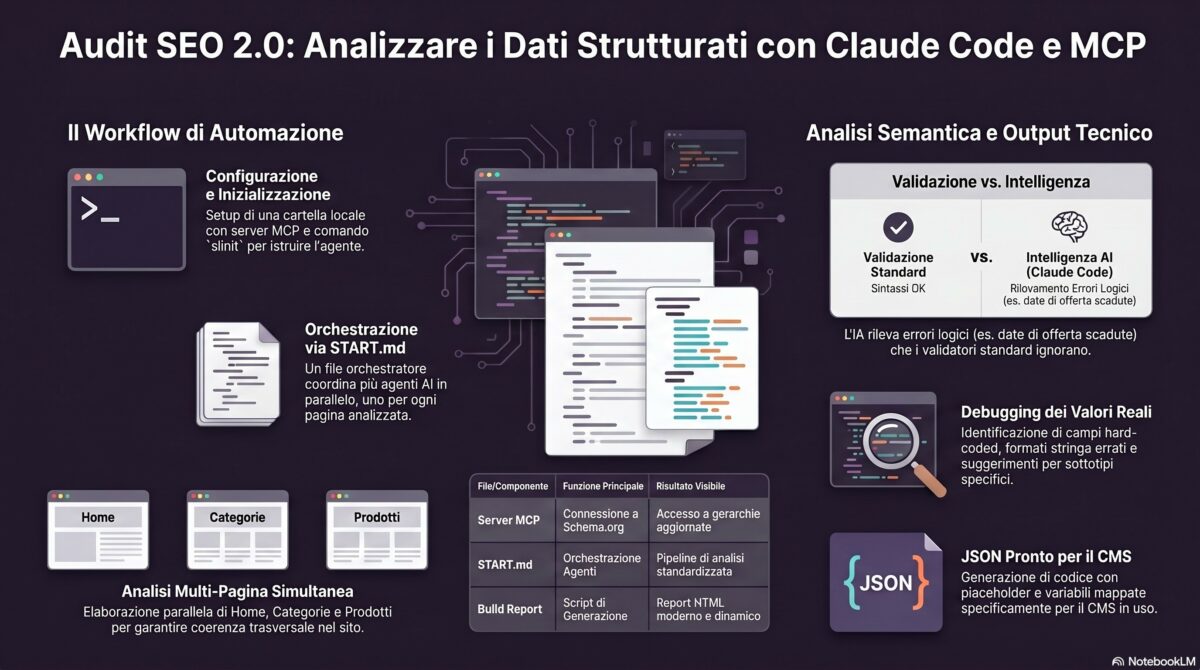
Cos’è un server MCP e perché applicarlo allo Schema.org
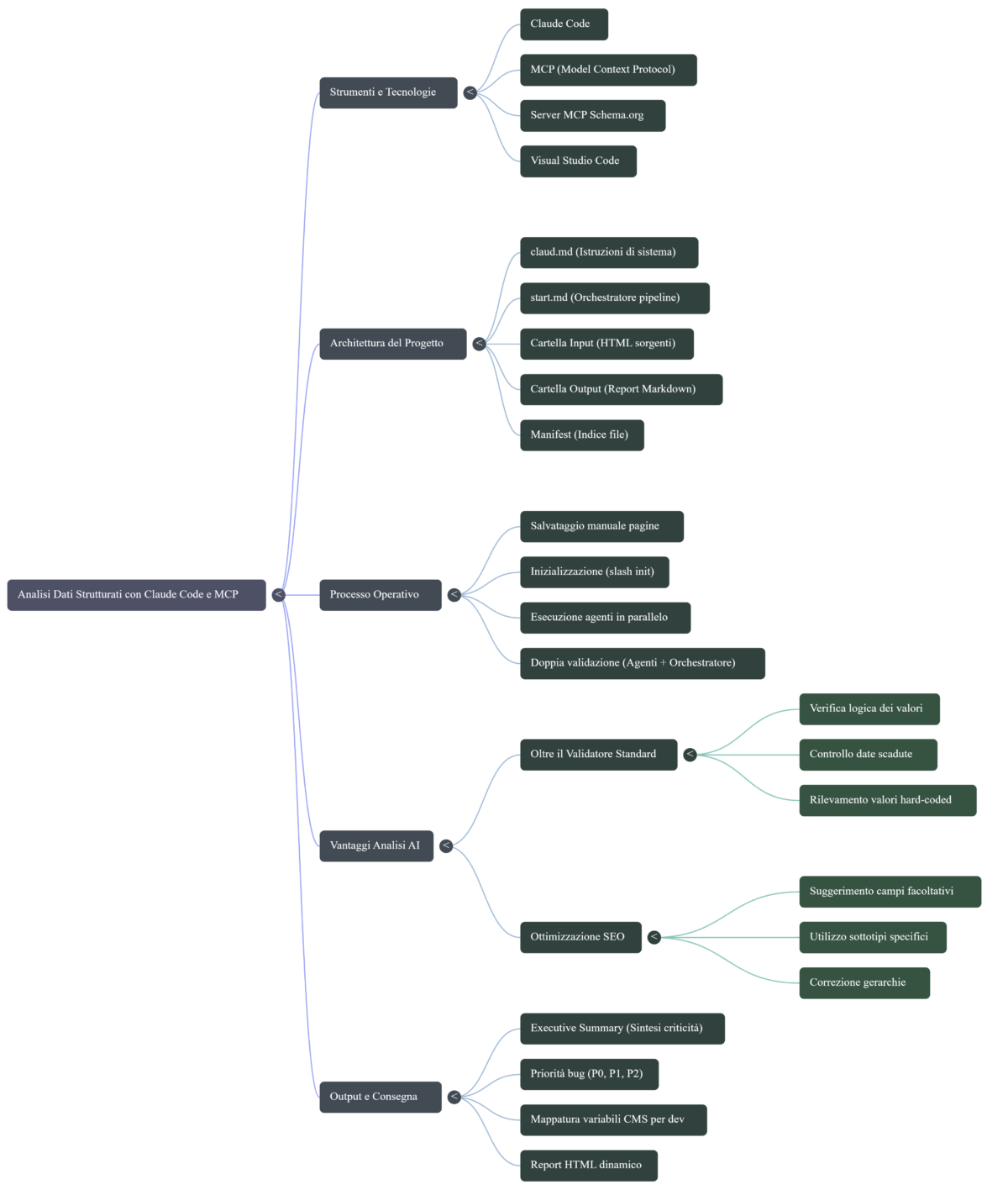
Un server MCP (Model Context Protocol) è una specifica aperta proposta da Anthropic per estendere le capacità di un LLM con strumenti esterni: lettura di file, query a database, chiamate API, accesso a sistemi specifici. Tecnicamente è un processo locale o remoto che espone tool e resource al modello tramite un protocollo standardizzato. Per un inquadramento generale dell’architettura MCP e del suo ruolo nel web intelligente ho già pubblicato una guida dedicata; documentazione ufficiale del protocollo: modelcontextprotocol.io.
Applicato allo Schema.org, un server MCP dedicato dà al modello accesso programmatico all’intera gerarchia dei tipi e delle proprietà, con tre conseguenze operative dirette:
- Validazione semantica delle proprietà. Il modello sa che
Article.dateModifiedè di tipoDateoDateTimee può segnalare valori che hanno la sintassi giusta ma sono fuori range temporale ragionevole. - Suggerimenti di tipo più specifici. Su una pagina di un e-commerce dichiarata come
Organization, il server può proporre l’unione conOnlineStoreo l’estensioneOnlineBusiness, perché conosce la gerarchia completa. - Identificazione di markup mancante per intent. Per una pagina contatti propone
ContactPage; per la home suggerisceWebSiteconSearchAction; per una FAQ proponeFAQPagecon i sottotipiQuestion/Answer. Il criterio di scelta del tipo va sempre incrociato con la guida ai dati strutturati per tipologia di sito web.
Il repository che uso nel video è Theycallmeholla/schema-org-mcp. È un’implementazione MCP open source che espone i tool necessari a Claude per interrogare la gerarchia Schema.org senza affidarsi alla memoria del modello (che, su tipi rari o aggiornamenti recenti della spec, è notoriamente imprecisa).
Architettura della pipeline: input statico in HTML, non Playwright
La prima decisione progettuale è anche la più importante: la pipeline lavora su file HTML statici salvati manualmente, non su URL crawlati live. La motivazione è puramente operativa.
Un crawler basato su requests Python o curl recupera solo l’HTML server-rendered. Per i siti che iniettano dati strutturati via JavaScript (caso comune su SPA React/Next.js, Vue, Angular, ma anche su molti CMS che usano plugin SEO che generano JSON-LD client-side) questo approccio perde proprio il markup che serve analizzare. La soluzione tecnica corretta sarebbe un headless browser come Playwright o Puppeteer, ma l’overhead di setup, gestione dei viewport, attese di rendering, gestione di eventuali captcha o rate-limit trasforma il progetto da “audit Schema.org” a “progetto su Playwright”.
Salvare la pagina dal browser con Ctrl+S in modalità Solo HTML risolve il problema in cinque secondi: si cattura lo stato finale del DOM dopo l’idratazione JavaScript, senza CSS, senza immagini, senza JS bundle che inquinerebbero il contesto del modello. È esattamente l’HTML che il browser mostra all’utente, contenente i microdata, RDFa o gli script application/ld+json nel loro stato di runtime.
Struttura del progetto:
schema-audit/
├── input/ # HTML salvati dal browser (Ctrl+S "Solo HTML")
│ ├── 01_home.html
│ ├── 02_category.html
│ ├── 03_product.html
│ ├── 04_blog_post.html
│ └── 05_contact.html
├── output/ # Report Markdown generati dagli agenti
├── repo/ # Server MCP clonato (creato da Claude)
├── CLAUDE.md # Istruzioni di progetto (generato da /init)
└── Start.md # Orchestratore della pipeline (scritto da te)Le pagine in input/ vanno scelte come campione rappresentativo dei template del sito. Cinque-sette file coprono tipicamente l’80% delle casistiche Schema.org di un e-commerce o di un editoriale: home, archivio categoria, scheda prodotto/articolo, pagina contatti, pagina servizio, eventuale checkout. Aggiungere file ulteriori serve solo se i template divergono in modo significativo (es. landing page custom, pagine evento, schede autore).
Setup del server MCP Schema.org in Claude Code
Il setup completo richiede pochi minuti se si lascia che sia Claude Code stesso a installare il server. Si parte da Claude Code avviato in una cartella di progetto vuota (consiglio Visual Studio Code come editor host, ma funziona anche da terminale puro). Tutta la configurazione del server (e dei progetti) viene scritta sotto ~/.claude/ e ~/.claude.json: per il dettaglio operativo ho mappato dove Claude Code salva configurazione e sessioni.
- Crea le cartelle di lavoro:
input/eoutput/nella root del progetto. Sposta i file HTML salvati dal browser ininput/con una nomenclatura ordinata (prefisso numerico, descrittore breve). - Avvia Claude Code nella root e inserisci come prompt: «Installa il server MCP da https://github.com/Theycallmeholla/schema-org-mcp clonandolo nella cartella
repo/e configura la voce in.mcp.jsondi questo progetto». - Conferma l’attivazione: Claude scrive un blocco di configurazione tipo quello qui sotto. Verifica che il path al binario o allo script di start del server sia corretto rispetto alla tua cartella
repo/. - Riavvia Claude Code e digita
/mcpnel terminale. Devi vedere il serverschema-orgcon statoconnected. Se apparefailed, leggi i log con/mcp logse correggi il path o le dipendenze del server (tipicamentenpm installnella cartellarepo/).
Esempio di configurazione MCP nel file .mcp.json di progetto (l’esatta sintassi dipende dalla versione del repo, verifica il README aggiornato):
{
"mcpServers": {
"schema-org": {
"command": "node",
"args": ["./repo/dist/index.js"],
"env": {}
}
}
}Nota: il file .mcp.json a livello di progetto ha il vantaggio di essere committabile, così l’intero team che clona il repo del cliente può rigenerare la stessa pipeline senza configurazioni manuali aggiuntive.
Inizializzazione del progetto con /init e CLAUDE.md
Una volta che il server MCP è attivo, lancio il comando /init nella root del progetto. Claude Code esegue una scansione del filesystem (incluso il repo MCP appena clonato), legge la documentazione del server e genera un file CLAUDE.md che funge da memoria persistente di progetto.
Il file CLAUDE.md viene caricato automaticamente all’inizio di ogni nuova sessione di Claude Code aperta in quella directory. Questo significa che le convenzioni di nomenclatura, le regole di output, le chiamate-tipo al server MCP e la struttura attesa del lavoro non vanno ripetute ogni volta. Il modello le ha già nel contesto.
Esempio di blocco minimo da assicurarsi sia presente in CLAUDE.md dopo il /init:
# Schema.org Audit Project
## Server MCP attivo
- schema-org (Theycallmeholla/schema-org-mcp)
- Da usare per: validazione tipi, lookup proprietà, suggerimenti gerarchia
## Cartelle
- input/ HTML statici da analizzare (1 file = 1 template)
- output/ Report Markdown (1 file per agente + 00_sintesi.md)
- repo/ NON modificare (server MCP clonato)
## Vincoli operativi
- Niente prosa decorativa nei report. Solo tabelle, codice, bullet point.
- JSON-LD finale con placeholder, mai con valori specifici della pagina.
- Nomenclatura output: NN_nomepagina.md (matching dei prefissi di input/).Start.md: l’orchestratore della pipeline
Il file Start.md è il cuore dell’automazione. Definisce la pipeline operativa che Claude eseguirà ogni volta che invio il prompt procedi (o esegui Start.md). Non lo scrivo riga per riga: lo faccio generare a Claude descrivendo a voce alta i requisiti, poi correggo manualmente i punti deboli.
Le sezioni che il file deve contenere sono cinque, in quest’ordine:
- Generazione del manifest. Prima istruzione operativa: ispezionare
input/, leggere ogni file HTML, estrarre titolo della pagina e tipo (homepage, listing, prodotto, articolo, contatti) e produrre unmanifest.jsoninoutput/che mappi ogni file ai metadati rilevanti. Questo file diventa la fonte di verità per le iterazioni successive. - Spawn dei sub-agenti in parallelo. Per ogni voce del manifest, l’orchestratore lancia un sub-agente con un prompt parametrizzato. Cinque file in input = cinque agenti che girano simultaneamente. Su un piano Claude con sufficiente concorrenza il tempo totale di analisi è quello del file più complesso, non la somma.
- Regole di output identiche per tutti gli agenti. Ogni agente produce un file
NN_nomepagina.mdinoutput/con sezioni fisse: stato attuale del markup, criticità individuate (P0/P1/P2), JSON-LD finale ottimizzato con placeholder, tabella delle variabili da mappare, riferimenti a tipi Schema.org consultati via MCP. - Vincoli stilistici rigidi. Niente introduzioni, niente conclusioni motivazionali, niente spiegazioni di concetti che lo sviluppatore già conosce. Se un’informazione non sta in una tabella, in un blocco di codice o in un bullet point, non va scritta. Questo elimina il 70% del rumore tipico degli output LLM.
- Doppia validazione e sintesi. Quando tutti i sub-agenti hanno terminato, l’orchestratore principale riprende il controllo, rilegge i file generati, ri-interroga il server MCP sui JSON-LD proposti e produce il file
00_sintesi.md(executive summary).
Nota: più rigido è Start.md, più prevedibile è il risultato. È controintuitivo, ma lasciare libertà stilistica al modello degrada l’output. La pipeline funziona perché ogni agente sa esattamente quale tabella deve riempire e quale formato deve produrre.
Sub-agenti in parallelo e standardizzazione dell’output
I sub-agenti operano in totale isolamento: ognuno legge il proprio file HTML, interroga il server MCP solo per i tipi rilevanti alla pagina che sta analizzando, scrive il proprio file Markdown e termina. Non hanno visibilità l’uno sull’altro. La sintesi trasversale è compito esclusivo dell’orchestratore.
Lo schema operativo di un singolo sub-agente, come definito in Start.md:
- Estrazione del markup esistente: parsing degli script
application/ld+json, microdataitemscope/itemtype, eventuali RDFatypeof/property. - Verifica gerarchica via MCP: ogni tipo dichiarato viene confrontato con la gerarchia ufficiale Schema.org (es.
Productdeve estendereThing,Offerè proprietà legittima diProduct,aggregateRatingrichiedeAggregateRatingconratingCountminimo). - Identificazione delle proprietà mancanti per intent: il modello, conoscendo il tipo di pagina dal manifest, propone proprietà ad alto valore SEO non presenti (es.
brand,gtin13,skusu un prodotto). - Costruzione del JSON-LD ottimizzato con placeholder al posto dei valori specifici della pagina di esempio.
- Scrittura del report Markdown in
output/seguendo il template imposto.
La classificazione delle criticità segue tre livelli operativi:
| Priorità | Tipologia | Esempi |
|---|---|---|
| P0 | Bloccante | Tipo dichiarato inesistente; markup malformato che invalida tutto lo script; valori di test in produzione |
| P1 | Warning | Proprietà obbligatoria per rich result mancante; valori sintatticamente corretti ma fuori range (date 2020, prezzi negativi) |
| P2 | Miglioramento | Tipo più specifico disponibile (Organization → OnlineStore); proprietà raccomandata ma non obbligatoria |
Doppia validazione ed executive summary
Il rischio di una pipeline a sub-agenti è la divergenza: cinque agenti possono inventare cinque interpretazioni leggermente diverse della stessa proprietà breadcrumb. La doppia validazione esiste per neutralizzarlo.
Quando i sub-agenti hanno scritto i loro file, l’orchestratore principale rilegge tutti i JSON-LD proposti e li sottopone una seconda volta al server MCP, questa volta in batch. La validazione cross-page individua tre classi di problemi che il singolo agente non poteva vedere:
- Inconsistenze trasversali: l’
Organizationdichiarata sulla home haname“Acme SRL” ma sull’articolo del blog appare come “Acme S.r.l.” e nei contatti come “ACME”. Lo sviluppatore deve sapere quale variabile del CMS usare per garantire consistenza. - Pattern di errore ripetuti: la breadcrumb è strutturata male su tutte le pagine. Conviene una correzione architetturale al template, non cinque correzioni puntuali.
- Opportunità di linking via @id: collegare l’
Organizationdella home con ilpublisherdegli articoli e con ilsellerdei prodotti tramite@id, per costruire un knowledge graph interno coerente che Google possa interpretare come un’entità unica. Per il quadro teorico su come Google modella le entità, rimando alla mia analisi sull’architettura del Knowledge Graph e le strategie di Semantic Optimization.
Il file 00_sintesi.md raccoglie l’output della doppia validazione in un executive summary strutturato: tabella generale con stato di ogni template, lista dei pattern trasversali da correggere a livello globale, ranking delle priorità di intervento per impatto SEO atteso, riferimenti incrociati ai file Markdown dei singoli agenti.
Mappatura delle variabili dinamiche per WordPress e PrestaShop
Questo è il passaggio che separa un audit accademico da un audit consegnabile. Il JSON-LD finale prodotto dagli agenti non contiene mai valori specifici della pagina di esempio: contiene placeholder. Lo sviluppatore non deve indovinare cosa sostituire e dove.
Esempio di output per una scheda prodotto e-commerce, con dichiarazione esplicita del CMS in Start.md o nel prompt iniziale («Il sito gira su WordPress + WooCommerce» oppure «PrestaShop 8.x con tema custom»). Spesso Claude inferisce il CMS direttamente dall’HTML di input — meta generator, classi CSS, pattern di URL — ma è più affidabile dichiararlo.
{
"@context": "https://schema.org",
"@type": "Product",
"name": "{{PRODUCT_NAME}}",
"sku": "{{PRODUCT_SKU}}",
"image": "{{PRODUCT_IMAGE_URL}}",
"description": "{{PRODUCT_DESCRIPTION}}",
"brand": {
"@type": "Brand",
"name": "{{BRAND_NAME}}"
},
"offers": {
"@type": "Offer",
"url": "{{PRODUCT_URL}}",
"priceCurrency": "{{CURRENCY_CODE}}",
"price": "{{PRODUCT_PRICE}}",
"priceValidUntil": "{{PRICE_VALID_UNTIL}}",
"availability": "{{AVAILABILITY_SCHEMA_URL}}",
"itemCondition": "https://schema.org/NewCondition"
}
}Tabella di mappatura per WordPress + WooCommerce generata dall’agente:
| Placeholder | Sorgente WP/WooCommerce | Esempio chiamata PHP |
|---|---|---|
{{PRODUCT_NAME}} | Titolo prodotto | $product->get_name() |
{{PRODUCT_SKU}} | SKU WooCommerce | $product->get_sku() |
{{PRODUCT_IMAGE_URL}} | Immagine in evidenza | wp_get_attachment_url( $product->get_image_id() ) |
{{PRODUCT_DESCRIPTION}} | Descrizione breve o lunga | $product->get_short_description() |
{{BRAND_NAME}} | Tassonomia “brand” (Perfect Brands o simili) | get_the_terms( $product->get_id(), 'product_brand' ) |
{{PRODUCT_URL}} | Permalink prodotto | get_permalink( $product->get_id() ) |
{{CURRENCY_CODE}} | Valuta WooCommerce | get_woocommerce_currency() |
{{PRODUCT_PRICE}} | Prezzo (con/senza tasse secondo settings) | $product->get_price() |
{{PRICE_VALID_UNTIL}} | Data scadenza offerta o calcolata dinamicamente | date('Y-m-d', strtotime('+30 days')) |
{{AVAILABILITY_SCHEMA_URL}} | Stock status mappato a URL Schema.org | $product->is_in_stock() ? 'https://schema.org/InStock' : 'https://schema.org/OutOfStock' |
La stessa tabella, generata per PrestaShop, restituisce variabili Smarty del template ({$product.name}, {$product.reference}, {$product.price_amount}) e i path agli oggetti del controller. Per Magento il modello restituirebbe blocchi $_product->getName() e $_product->getFinalPrice(). Per Shopify, riferimenti Liquid ({{ product.title }}, {{ product.featured_image }}).
Nota: la mappatura va sempre verificata da chi conosce il setup specifico del cliente. Plugin custom, override del tema, costruttori di pagine come Elementor o Bricks possono spostare le variabili in posti non standard. La tabella è un punto di partenza, non un manuale definitivo.
Generazione del report HTML finale
I file Markdown sono comodi per il modello e per chi lavora in editor. Per il cliente o per il dev team ha più senso un report HTML a pagina singola, formattato in modo professionale, con sezioni navigabili, tabelle stilizzate e blocchi di codice copiabili.
Trasformare l’output in HTML è banale proprio perché i file Markdown sono fortemente strutturati. Chiedo a Claude di generare uno script build_report.py (o .js, a seconda della stack del cliente) che legga tutti i file .md in output/ ordinati per prefisso numerico, popoli un template HTML con header, sommario, sezione executive summary in apertura, sezioni per template e footer con metadata di generazione.
Lo script tipico fa tre cose:
- Legge i file Markdown con una libreria di parsing (python-markdown con estensioni
tables,fenced_code,toc) e li converte in HTML. - Inietta CSS minimal (Tailwind via CDN, oppure un foglio di stile inline) per resa professionale: tabelle a stripe, syntax highlighting via highlight.js, header sticky, anchor nei titoli.
- Genera un file singolo
report.htmlautocontenuto, inviabile via email o pubblicabile su un’area cliente senza dipendenze esterne.
Una volta che lo script è stato generato e testato, il comando per produrre il report finale dopo ogni run della pipeline è uno solo: python build_report.py. Il deliverable per il cliente passa da un’operazione manuale di mezza giornata a un comando di trenta secondi.
Quando questo approccio fa la differenza e dove si ferma
La pipeline è ottimizzata per audit di template, non per scansione di interi siti URL per URL. Cinque-sette template coprono tipicamente le casistiche di un sito anche grande, ma se l’obiettivo è verificare che il singolo JSON-LD del prodotto X sia corretto, basta il Rich Results Test ufficiale.
I casi in cui questo approccio fornisce un valore che gli strumenti tradizionali non possono offrire:
- Revamp completo dei dati strutturati di un sito con architettura complessa, dove il template Schema.org è invecchiato e va riprogettato da zero.
- Audit pre-migrazione: documentare cosa ha il sito attuale, decidere cosa portare avanti e cosa correggere nel nuovo CMS.
- Onboarding di un cliente nuovo: produrre in poche ore un deliverable tecnico approfondito che dimostri competenza e individui le quick win.
- Cross-template consistency check su entità chiave (Organization, Brand, Author): garantire che la stessa entità sia dichiarata in modo consistente su tutto il sito e linkata via
@id.
I limiti operativi di cui tenere conto:
- L’output è un punto di partenza, non un’implementazione finale. Ogni JSON-LD proposto va testato con il Rich Results Test ufficiale prima del go-live, perché Google ha requisiti per i rich result che vanno oltre la conformità Schema.org pura.
- Il modello può proporre tipi corretti ma non supportati per i rich result. Schema.org definisce molti tipi che Google non utilizza per generare snippet. La discriminazione tra “valido secondo Schema.org” e “utile secondo Google” richiede ancora supervisione umana.
- HTML salvato dal browser cattura lo stato a quell’istante. Se il sito modifica il markup in base a A/B test, geolocalizzazione o stato di login, l’analisi può non essere rappresentativa di ciò che vede Googlebot. Per casi sensibili, conviene salvare l’HTML usando
curlcon lo user-agent di Googlebot. - La dimensione dei file di input contribuisce al consumo di token. Pagine HTML troppo pesanti possono saturare il contesto degli agenti. Per template molto verbosi vale la pena pre-pulire l’HTML rimuovendo SVG inline, contenuti header/footer ripetuti e blocchi non rilevanti per l’analisi.
L’unione di un LLM con accesso programmatico al dizionario Schema.org tramite MCP cambia il rapporto tra costo e profondità dell’audit. Quello che fino a un anno fa richiedeva un giorno di lavoro per template, oggi lo risolvi in venti minuti di setup e cinque minuti di esecuzione, con un deliverable più consistente e meno soggetto a errori umani. Il giudizio finale resta in capo a chi sa cosa Google effettivamente premia — quello, per ora, non si automatizza.
Risorse citate:
Articoli correlati
Autore

Mi chiamo Giovanni Sacheli e dal 2009 aiuto le aziende a farsi trovare online. Sono specializzato in SEO tecnica e PPC, competenze che applico quotidianamente nella mia agenzia, Searcus Swiss Sagl. Mi piace sviluppare strumenti a supporto del mio lavoro, ho creato SEOdata.app e cluster.army e co-scritto il libro SEO Audit Avanzato. Curo maniacalmente questo blog per colleghi e appassionati, dove mi "appunto" quello che imparo. Sono un NERD anni '80, motociclista e orgoglioso papà di due bambini.
Link:
Giovanni Sacheli
SEO Audit Avanzato
Searcus Swiss Sagl
SEOdata.app
cluster.army