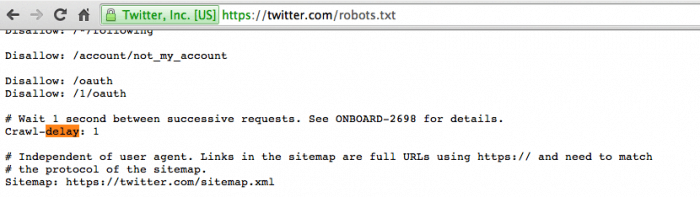
Molti crawler supportano la direttiva “Crawl-delay” la quale imposta il numero di secondi che i bot e crawler dei motori di ricerca (e non solo) devono attendere prima di effettuare la richiesta successiva al web server.
Il parametro Crawl-delay veniva generalmente usato da grandi portali aggiornati di frequente. Nel caso di Twitter ad esempio, Googlebot e altri principali bot amano visitare continuamente il suo server perché è facile trovare contenuti nuovi. Attraverso una scansione continua dei siti web i motori di ricerca possono fornire risultati di ricerca aggiornati praticamente in tempo reale.
Dato che la visita costante di numerosi bot potrebbe mettere sotto stress il web server, Twitter ha impostato un intervallo di crawling per ogni richiesta nel suo file Robots.txt (vedi immagine).
Cose da sapere
L’obiettivo principale del parametro crawl-delay è quello di evitare il sovraccarico del web server causato dalle frequenti richieste dei bot, risulta quindi utile in siti grandi con molti contenuti pubblicati frequentemente. Siti di piccole dimensioni non necessitano di questa direttiva.
YahooSlurp, MSNBot supportano la direttiva Crawl-delay, altri bot invece la ignorano. Per questo motivo è consigliato assegnare la direttiva a specifici bot e non come regola generale:
Come fare:
User-agent: MSNBot
Crawl-delay: 5
Come non fare:
User-agent: *
Crawl-delay: 5
Il tempo rappresentato nel crawl-rate è indicato in secondi. Se il tuo server ospita più siti web consiglio di utilizzare crawl-delay maggiori di 1 secondo. Valori uguali o inferiori a 1 secondo non ridurranno il sovraccarico del web server.
Googlebot non supporta il crawl-delay
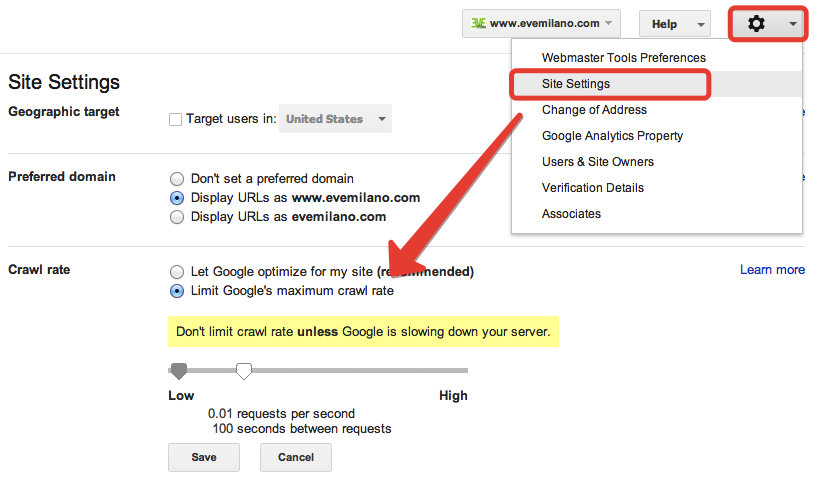
Per impostare il ritardo di crawling per Google è necessario utilizzare la funzione “crawl-rate” in Google Search Console che trovate in “Site configuration” cliccando su “Settings” (vedi immagine). In questo box puoi impostare il valore che preferisci affinchè il tuo web server possa lavorare rilassato :)
La nuova impostazione tuttavia non durerà per sempre ma per un tempo limitato di 90 giorni.
Articoli correlati
Autore

Mi chiamo Giovanni Sacheli e dal 2009 aiuto le aziende a farsi trovare online. Sono specializzato in SEO tecnica e PPC, competenze che applico quotidianamente nella mia agenzia, Searcus Swiss Sagl. Mi piace sviluppare strumenti a supporto del mio lavoro, ho creato SEOdata.app e cluster.army e co-scritto il libro SEO Audit Avanzato. Curo maniacalmente questo blog per colleghi e appassionati, dove mi "appunto" quello che imparo. Sono un NERD anni '80, motociclista e orgoglioso papà di due bambini.
Link:
Giovanni Sacheli
SEO Audit Avanzato
Searcus Swiss Sagl
SEOdata.app
cluster.army
Commenti |2
Lascia un commentoCiao Giovanni,
sto seguendo un sito su Siteground.
Ti è mai capitato di scrivere www.indirizzodelsito.it/robots.txt e vedere che c’è una regola tipo:
Crawl-delay: 10
Poi vai a scaricare il file robots e quella regola non c’è più?
Ti aggiungo che nella GSC è tutto settato di default “Lascia che Google esegua l’ottimizzazione per il mio sito (consigliata)”
Sai per caso se dal Cpanel di Siteground si possa riscrivere un file robots.txt ?
Grazie
Ciao Fausto, scusa il ritardo.
Non ho siti su Siteground ma credo che quello che descrivi sia più un problema di plugin che sovrascrive il robots standard (Yoast?).
Proverei a disabilitare tutti i plugin, cancellare cache & Co, e riproverei ad aprire il Robots.txt.
Fammi sapere :D