Costruire una lista di keyword per Google Ads non è più una questione di brainstorming su un foglio Excel e poi caricamento manuale via Keyword Planner. Le campagne moderne convivono con broad match potenziato da Smart Bidding, Performance Max con search themes, varianti simili sempre più larghe e Search Terms Report che esplodono in migliaia di query uniche da governare. In questo scenario, la keyword research si fa pipeline: dati grezzi in ingresso, ranking e clustering programmatici, output strutturato pronto per Ads Editor.
Questa guida descrive una pipeline replicabile in Python che combina quattro fonti dati ortogonali — Google Search Console API, Google Ads API, DataForSEO Labs ed embeddings semantici — per generare, scorare e clusterizzare la lista keyword di una campagna SEM. Ogni stage è accompagnato da uno snippet eseguibile, dalle scelte di filtraggio e dalle insidie operative che emergono quando la pipeline va in produzione su account reali con centinaia di campagne e migliaia di keyword.
Il taglio è engineering-grade: presuppone padronanza di Python, pandas, autenticazione OAuth/service account, e familiarità con la terminologia Google Ads del 2026 (no BMM, phrase match allargata, broad + Smart Bidding come combo nativa). La sezione finale racconta gli errori più comuni in produzione e come evitarli.
Perché un revamp ingegnerizzato della keyword research
La keyword research di Google Ads è cambiata in profondità tra il 2021 e il 2024. Tre eventi hanno reso obsolete le checklist scritte fino a quel momento e hanno spostato il baricentro del lavoro dall’editing manuale all’orchestrazione di dati.
Cosa cambia nel 2026: broad + Smart Bidding, search themes, sparizione del BMM
Il Broad Match Modifier è stato deprecato a febbraio 2021 e definitivamente assorbito dal phrase match esteso a luglio dello stesso anno. Da allora i match type disponibili sono tre più la lista delle negative: broad, phrase, exact. Contestualmente Google ha spinto sulla combinazione broad + Smart Bidding (tCPA, tROAS, Maximize Conversion Value), portando la piattaforma a interpretare le keyword più come signal che come filtri rigidi. Performance Max, lanciata a fine 2021 e potenziata con i search themes nel 2024, ha completato il quadro: le keyword non sono più l’unica leva di targeting, ma restano lo scheletro semantico su cui le strategie ibride costruiscono ad group e asset group.
La conseguenza operativa è che oggi una lista keyword serve a tre cose distinte e va costruita avendole tutte e tre in mente: alimentare gli ad group di Search a phrase/exact per le query ad alto intent, fornire seed di discovery alle campagne broad+Smart Bidding, e contribuire come search themes ai pacchetti Performance Max. Per dettagli sui match type rimando alla guida dedicata sulla corrispondenza delle parole chiave in Google Ads.
Quando la ricerca manuale non scala più
Tre soglie operative segnano il passaggio obbligato dal foglio Excel alla pipeline:
- Inventario superiore a 500 SKU o catalogo articolato per categoria/brand/feature: la combinatoria delle query brand × prodotto × intent supera rapidamente i limiti di gestione manuale. Per scenari da catalogo grande conviene affiancare le Dynamic Search Ads alla ricerca tradizionale.
- Search Terms Report con oltre 5.000 query uniche al mese: il negative keyword mining manuale diventa impraticabile e si perde gettito su query da escludere ma high-volume.
- Account multi-mercato con localizzazioni linguistiche: tradurre/adattare la lista a mano produce errori sistematici sulle varianti idiomatiche. L’embedding multilingua risolve il problema nativamente.
Sotto queste soglie l’overhead della pipeline non si ripaga; sopra, è l’unica strada per non lasciare gettito a terra.
Architettura della pipeline
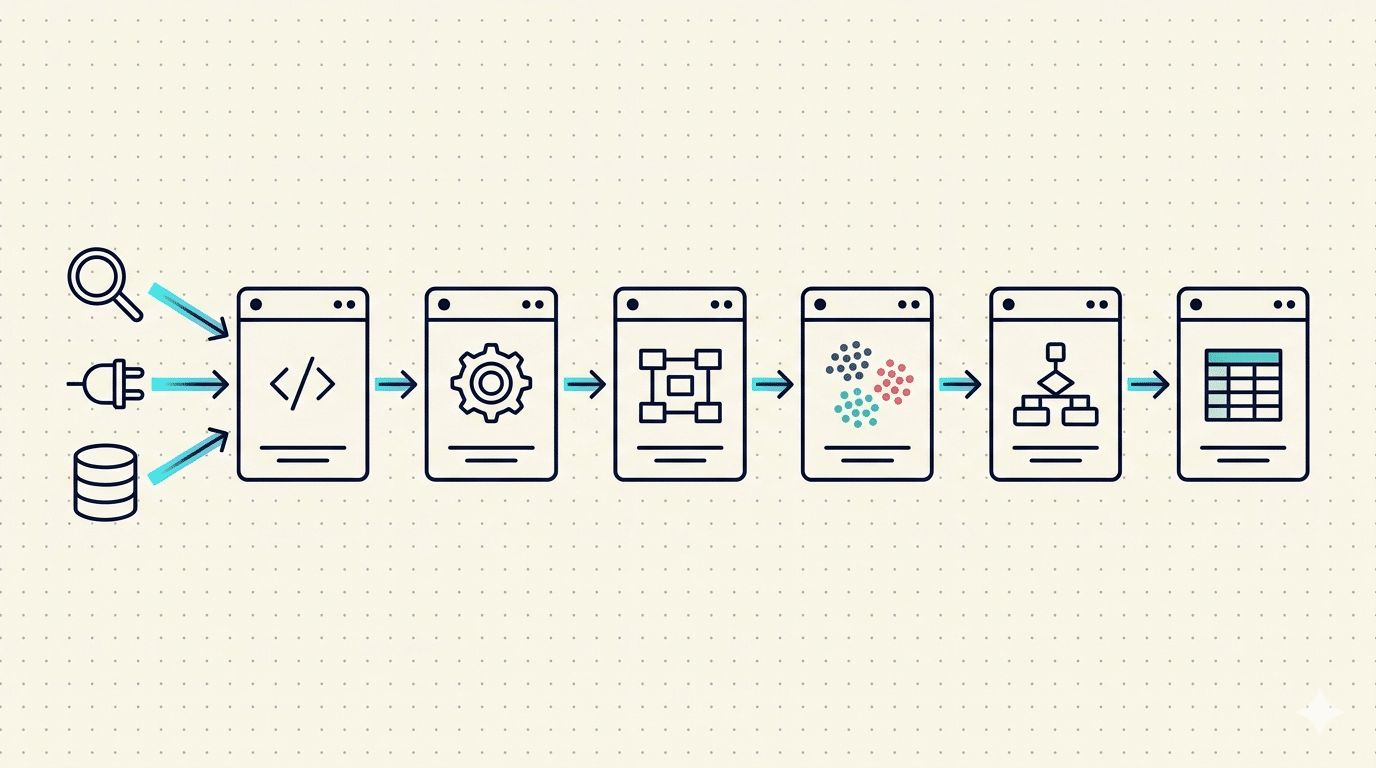
La pipeline si articola in sette stage sequenziali, ciascuno con responsabilità definita e contratto di I/O chiaro. Ogni stage produce un DataFrame pandas che diventa input dello stage successivo, in modo da rendere il processo ispezionabile passo per passo e ripartibile da qualunque checkpoint intermedio.
Diagramma a stage: i sette passaggi
- Seed generation — Estrazione query organiche performanti da Google Search Console come base semantica.
- Espansione semantica — Generazione varianti tramite Google Ads Keyword Plan Idea Service, DataForSEO Labs e LLM-assisted expansion.
- Enrichment metriche — Volume mensile, CPC top of page bid, competition index, search intent.
- Scoring multi-fattore — Combinazione pesata di volume, intent, competition e CPC per ranking finale.
- Clustering semantico — Embedding multilingua, riduzione dimensionale UMAP, clustering HDBSCAN per la struttura ad group.
- Negative keyword mining — N-gram analysis del Search Terms Report storico per identificare termini da escludere.
- Export Ads Editor — Generazione CSV con assegnazione match type per cluster e checklist pre-attivazione.
Setup ambiente: credenziali e dipendenze
Prima di iniziare servono tre set di credenziali e uno stack Python predefinito. Le credenziali Google (GSC + Ads) vivono in service account JSON; quelle DataForSEO in coppia login/password caricata da .env. Lo stack minimo per la pipeline:
# requirements.txt — stack pipeline keyword research
pandas>=2.2
numpy>=1.26
python-dotenv>=1.0
google-api-python-client>=2.130 # GSC API
google-ads>=24.0 # Google Ads API (Keyword Plan Idea Service)
httpx>=0.27 # DataForSEO REST
sentence-transformers>=3.0 # embedding multilingua
umap-learn>=0.5
hdbscan>=0.8
scikit-learn>=1.5
tldextract>=5.1
Se l’account Ads non è ancora attivo, la guida di partenza è come creare un account Google Ads con i prerequisiti di fatturazione e setup property. Il developer token Google Ads va richiesto separatamente dal Manager Account (MCC).
Stage 1 — Seed generation da Search Console
Il primo errore della keyword research tradizionale è partire da un’ipotesi commerciale (“queste sono le keyword del mio mercato”). Il modo corretto è partire da dati osservati: quali query già portano traffico al sito e con quale performance. La Search Console API searchanalytics.query permette di estrarre fino a 50.000 righe per chiamata, filtrabili per device, country, search appearance.
Estrazione query organiche via searchanalytics API
L’obiettivo è raccogliere il pool di query organiche degli ultimi 90-180 giorni con almeno una soglia minima di impression. Il payload va in formato dimensioni multiple (query, page) per poter poi associare ogni query alla landing page corrispondente, utile in fase di scoring per il match keyword-LP.
from google.oauth2 import service_account
from googleapiclient.discovery import build
import pandas as pd
creds = service_account.Credentials.from_service_account_file(
"service-account.json",
scopes=["https://www.googleapis.com/auth/webmasters.readonly"],
)
webmasters = build("searchconsole", "v1", credentials=creds)
request = {
"startDate": "2025-11-01",
"endDate": "2026-05-01",
"dimensions": ["query", "page"],
"rowLimit": 25000,
"startRow": 0,
}
resp = webmasters.searchanalytics().query(
siteUrl="sc-domain:evemilano.com", body=request
).execute()
rows = resp.get("rows", [])
df_gsc = pd.DataFrame([{
"query": r["keys"][0],
"page": r["keys"][1],
"clicks": r["clicks"],
"impressions": r["impressions"],
"ctr": r["ctr"],
"position": r["position"],
} for r in rows])
Filtri operativi: impressioni, CTR, posizione, branded
Le query estratte vanno filtrate prima di entrare nello stage successivo. I criteri minimi sono:
- Soglia impressioni: scartare query con < 30 impressioni nel periodo (rumore, query rarissime).
- Esclusione query branded: il termine brand non va comprato (cannibalizza l’organico e genera CPC inutilmente alto). Si filtra via regex sul nome del brand e sue varianti.
- Posizione media: separare il pool in due bucket — query già in top 3 (potenziale espansione su intent affini) e query in posizione 5-30 (low-hanging fruit per Ads in attesa che maturi la SEO).
- Deduplicazione lessicale: applicare normalizzazione lowercase + strip accenti + unicode NFKC per evitare di duplicare “scarpe running” e “Scarpe Running”.
Il pool risultante è tipicamente nell’ordine di qualche migliaio di query. Questo è il seed set della pipeline.
Stage 2 — Espansione semantica
Il seed set di GSC è ricco ma incompleto: contiene solo query che già rankano sul sito. Per coprire l’intero spazio semantico del mercato bisogna espanderlo con fonti esogene. Tre canali, da combinare:
Google Ads KeywordPlanIdeaService
Endpoint nativo di Google Ads API che restituisce idee di keyword correlate alle seed, con metriche storiche di volume, competition e CPC range. Vantaggio: dati ufficiali Google, gli stessi che vede il Keyword Planner web. Limite: una chiamata accetta fino a 20 seed e restituisce fino a 10.000 idee, quindi su seed set di migliaia di query servono batch e gestione del rate limit. Lo stesso servizio supporta anche modalità generateKeywordIdeas da URL della landing page, utile per recuperare semantiche legate al posizionamento attuale.
DataForSEO Labs: related, suggestions, search intent
DataForSEO Labs offre tre endpoint chiave che si integrano nel flusso senza overlap con Google Ads API:
dataforseo_labs_google_related_keywords— keyword semanticamente correlate con grafo di profondità (depth) configurabile, utile per coprire varianti non emerse da Google Ads.dataforseo_labs_google_keyword_suggestions— espansione long-tail per ogni seed, copre prefissi e suffissi tematici.dataforseo_labs_google_ranked_keywordsapplicato a competitor diretti — recupera l’intero spazio keyword dei concorrenti, fondamentale per scoprire intent non coperti.
LLM-assisted expansion: varianti, intent, modificatori
Gli LLM (Claude, GPT-5, Gemini) sono particolarmente efficaci per due task che le API tradizionali non coprono bene: la generazione di modificatori commerciali per intent (transactional vs informational vs comparison) e la traduzione/localizzazione idiomatica delle keyword in mercati multipli. Prompt strutturato di esempio, da chiamare in batch su gruppi di 20-30 seed alla volta:
SYSTEM_PROMPT = """Sei un keyword researcher Google Ads.
Per ogni seed in input genera fino a 15 varianti raggruppate per intent:
- transactional (compra, acquista, prezzo, sconto, offerta)
- comparison (vs, migliore, recensione, opinioni)
- informational (cos'e, come funziona, guida)
Output JSON: {seed: {transactional: [], comparison: [], informational: []}}.
Mantieni la lingua del seed. Niente keyword branded di competitor.
"""
import json
from anthropic import Anthropic
client = Anthropic()
def expand_seeds(seeds: list[str]) -> dict:
msg = client.messages.create(
model="claude-opus-4-7",
max_tokens=4096,
system=SYSTEM_PROMPT,
messages=[{"role": "user", "content": json.dumps(seeds)}],
)
return json.loads(msg.content[0].text)
La combinazione delle tre fonti produce un expanded set tipicamente 10-30x più grande del seed iniziale. La deduplicazione finale si fa via embedding (cosine similarity > 0.95 = duplicato semantico) per non perdere varianti utili ma anche non gonfiare la lista con sinonimi inutili.
Stage 3 — Enrichment metriche
L’expanded set è una lista grezza di keyword senza dati. Per poter applicare uno scoring servono almeno quattro metriche per ciascuna: volume di ricerca mensile, CPC range, competition index, search intent. Le prime tre vengono dal Keyword Planner via API o da DataForSEO, l’ultima da DataForSEO Labs search_intent o da classificazione LLM.
Volume, CPC, competition da Keyword Planner
La generateKeywordHistoricalMetrics di Google Ads API accetta fino a 10.000 keyword per chiamata e restituisce per ciascuna: avg_monthly_searches, monthly_search_volumes (ultimi 12 mesi mese per mese, per analisi stagionalità), competition (LOW/MEDIUM/HIGH + index 0-100), low_top_of_page_bid_micros e high_top_of_page_bid_micros (CPC bid range, in micro-euro).
Search intent classification via DataForSEO Labs
DataForSEO Labs search_intent classifica ogni keyword in quattro categorie — informational, navigational, commercial, transactional — con probabilità associata. Per le campagne Ads gli intent rilevanti sono commercial e transactional: le informational vanno tipicamente verso campagne Display o YouTube, non Search. La classificazione automatica risparmia ore di etichettatura manuale e si rivela coerente con quella umana nel ~85% dei casi (test empirico su dataset italiani).
Stagionalità: monthly searches per picchi e trend
Il dato di volume medio mensile nasconde stagionalità che cambiano la pianificazione budget. Una keyword come “regali natale” può avere 100k impressioni medie/anno ma concentrare il 70% del traffico in novembre-dicembre. L’array monthly_search_volumes permette di calcolare un seasonality coefficient per ogni keyword:
import numpy as np
def seasonality_score(monthly_volumes: list[int]) -> float:
"""Coefficient of variation: 0 = traffico costante, >0.5 = stagionale forte."""
arr = np.array(monthly_volumes, dtype=float)
if arr.mean() == 0:
return 0.0
return float(arr.std() / arr.mean())
def peak_month(monthly_volumes: list[int]) -> int:
"""Mese (1-12) di picco assoluto."""
return int(np.argmax(monthly_volumes)) + 1
df_kw["seasonality_cv"] = df_kw["monthly_volumes"].apply(seasonality_score)
df_kw["peak_month"] = df_kw["monthly_volumes"].apply(peak_month)
Le keyword con seasonality CV > 0.5 vanno in campagne dedicate con programmazione attivazione/sospensione, non miscelate con quelle a domanda costante.
Stage 4 — Scoring multi-fattore
Con tutte le metriche disponibili si può finalmente costruire un punteggio composito che ordini le keyword per attrattività. Il principio: una keyword vale se ha volume alto, intent giusto, competition bassa (cioè CPC abbordabile), e se la landing page disponibile è coerente con la query.
Formula di score: pesata volume × intent × competition × CPC
Lo scoring va vettorizzato in pandas per poter girare su decine di migliaia di keyword in pochi secondi. La formula non ha pretese teoriche: serve a ottenere un ranking ragionevole come punto di partenza che poi viene tarato sui risultati di campagna delle prime due settimane.
import numpy as np
INTENT_WEIGHT = {"transactional": 1.0, "commercial": 0.7,
"navigational": 0.3, "informational": 0.1}
def score_keywords(df):
# Normalizzazione log per smorzare la coda lunga del volume
df["vol_norm"] = np.log1p(df["avg_monthly_searches"]) / np.log1p(df["avg_monthly_searches"].max())
# Competition gia 0-1; ribaltata: bassa competition = punteggio alto
df["comp_inv"] = 1 - df["competition_index"] / 100
# CPC bid: usiamo il low bid come proxy di accessibilita
df["cpc_norm"] = 1 - (df["low_top_of_page_bid_eur"] / df["low_top_of_page_bid_eur"].quantile(0.95)).clip(0, 1)
df["intent_w"] = df["intent"].map(INTENT_WEIGHT).fillna(0.1)
df["score"] = (
0.40 * df["vol_norm"] +
0.30 * df["intent_w"] +
0.20 * df["comp_inv"] +
0.10 * df["cpc_norm"]
)
return df.sort_values("score", ascending=False)
Soglie di pruning: rimuovere quello che non serve
Lo scoring produce una distribuzione continua. Il pruning serve a tagliare la coda. Soglie operative tipiche:
| Criterio | Soglia di taglio | Motivo |
|---|---|---|
| Volume medio mensile | < 50 | Sotto questa soglia il dato è troppo rumoroso per gestire bid in modo affidabile |
| Intent | = informational | Da spostare in campagne Display/Discovery, non Search |
| Competition index | > 90 con CPC > 5 € | Mercato saturato, ROI a rischio salvo budget enterprise |
| Score composito | < percentile 25 | Coda inferiore, basso rendimento atteso |
Quality Score atteso: matching keyword–landing page
Il Quality Score non è osservabile prima dell’attivazione, ma il suo principale driver — la pertinenza tra keyword e landing page — sì. Calcolando la cosine similarity tra l’embedding della keyword e l’embedding del title+H1+meta della LP candidata si ottiene un proxy quantitativo. Sotto similarity 0.45 la keyword va o riassegnata a un’altra LP o esclusa, perché un Quality Score basso porta CPC alti e Ad Rank scarso. Per il dettaglio dei fattori che pesano sul Quality Score rimando alla guida come aumentare il Quality Score di Google Ads.
Stage 5 — Clustering semantico per ad group structure
Raggruppare a mano alcune migliaia di keyword in ad group coerenti è lavoro tanto noioso quanto soggetto a errori sistematici: l’occhio si stanca, si tende a creare ad group troppo larghi o troppo granulari, e si perdono relazioni semantiche non lessicali (“scarpe corsa” e “running shoe” finiscono in ad group separati se ci si basa sul testo). L’approccio basato su embedding risolve entrambi i problemi.
Embedding multilingua con sentence-transformers
Il modello di riferimento per il clustering keyword cross-lingua è paraphrase-multilingual-mpnet-base-v2 della libreria sentence-transformers: vettori da 768 dimensioni, supporto nativo a 50+ lingue, qualità di sentence embedding superiore ai modelli generici tipo multilingual BERT. Per dataset molto grandi si può scendere a paraphrase-multilingual-MiniLM-L12-v2 (384 dim, 3x più veloce, qualità leggermente inferiore).
UMAP + HDBSCAN per cluster naturali
I 768 dimensioni dell’embedding sono troppi sia per la visualizzazione sia per la qualità del clustering (curse of dimensionality). UMAP riduce a 5-15 dimensioni preservando la struttura locale, e HDBSCAN trova cluster di densità variabile senza richiedere di specificare k a priori, marcando come noise i punti che non appartengono a nessun cluster denso. Combinazione che funziona meglio di KMeans su dati testuali, dove cluster sono naturalmente di dimensioni asimmetriche.
from sentence_transformers import SentenceTransformer
import umap
import hdbscan
model = SentenceTransformer("paraphrase-multilingual-mpnet-base-v2")
embeddings = model.encode(df_kw["keyword"].tolist(),
batch_size=64, show_progress_bar=True)
# Riduzione dimensionale per il clustering
reducer = umap.UMAP(n_neighbors=15, n_components=10,
metric="cosine", random_state=42)
emb_reduced = reducer.fit_transform(embeddings)
# Clustering density-based
clusterer = hdbscan.HDBSCAN(min_cluster_size=8, min_samples=3,
cluster_selection_method="eom")
df_kw["cluster"] = clusterer.fit_predict(emb_reduced)
# cluster == -1 sono noise: keyword "orfane" da gestire manualmente
Validazione cluster: silhouette e naming ad group
HDBSCAN va validato prima di essere accettato in produzione. Tre check:
- Silhouette score medio per cluster (escludendo noise): valori > 0.3 indicano cluster ben separati. Valori sotto 0.15 segnalano che l’embedding non distingue bene le keyword e va valutato un modello migliore o seed più diversificati.
- Ispezione manuale dei primi 5 cluster per dimensione: se contengono keyword evidentemente eterogenee (es. brand mescolati con prodotti generici), abbassare
min_cluster_sizeo aumentaren_neighborsdi UMAP per cluster più granulari. - Naming automatico ad group: per ogni cluster, estrai i 3 token più frequenti (TF-IDF) e usali come ad group name. Naming alternativo: usare un LLM per generare un nome semantico data una lista di 10 keyword campione del cluster.
Stage 6 — Negative keyword mining via n-gram analysis
Le negative keyword sono il fattore più sottovalutato della keyword research. In account maturi, una negative list ben costruita può abbattere il CPA del 20-40% in due settimane senza modificare nient’altro. Il problema è scoprire quali negative aggiungere, e qui l’n-gram analysis del Search Terms Report è lo strumento più affilato disponibile.
Estrazione Search Terms Report storico
Il Search Terms Report di Google Ads contiene tutte le query effettive che hanno attivato gli annunci. Estraibile via Google Ads API con query GAQL search_term_view: campi essenziali sono search_term, clicks, impressions, cost_micros, conversions, conversions_value. Periodo consigliato: ultimi 90 giorni con almeno 100 click per dare significatività statistica all’analisi successiva.
N-gram analysis: 1, 2, 3-gram su query non-converting
L’idea: scomporre ogni search term in 1-gram, 2-gram e 3-gram, e aggregare costo e conversioni per ogni n-gram. Gli n-gram con alto costo cumulato e zero o pochissime conversioni sono candidati negative. Il livello di n-gram conta: gli 1-gram catturano negative generici (“gratis”, “lavoro”), i 2-gram e 3-gram pattern più specifici (“come fare”, “fai da te”).
from collections import defaultdict
import pandas as pd
def ngrams(text: str, n: int) -> list[str]:
tokens = text.lower().split()
return [" ".join(tokens[i:i+n]) for i in range(len(tokens) - n + 1)]
def mine_negatives(df_terms: pd.DataFrame, n: int = 2,
min_cost: float = 20.0, max_cvr: float = 0.005) -> pd.DataFrame:
stats = defaultdict(lambda: {"cost": 0, "conv": 0, "imp": 0})
for _, row in df_terms.iterrows():
for g in ngrams(row["search_term"], n):
stats[g]["cost"] += row["cost_eur"]
stats[g]["conv"] += row["conversions"]
stats[g]["imp"] += row["impressions"]
out = pd.DataFrame([
{"ngram": k, **v, "cvr": v["conv"] / max(v["imp"], 1)}
for k, v in stats.items()
])
return out[(out["cost"] >= min_cost) & (out["cvr"] <= max_cvr)] \
.sort_values("cost", ascending=False)
Promozione dei top n-gram a livello campagna o ad group
I top n-gram candidati vanno classificati prima di essere caricati come negative:
- Negative trasversali (es. “gratis”, “torrent”, “lavoro”, “stipendio”) → livello account o lista negativa condivisa.
- Negative di intent (es. “come fare”, “fai da te”, “tutorial”) → livello campagna per le sole campagne transactional.
- Negative di segmento (es. “usato” per un brand che vende solo nuovo) → livello ad group dell’ad group specifico.
La revisione manuale prima dell’upload è non negoziabile: un n-gram che sembra negativo può nascondere intent legittimi su query specifiche. Esempio classico: “economico” è candidate negative per un brand premium ma legitimate keyword per un’altra campagna dello stesso account.
Stage 7 — Export per Google Ads Editor
L’output finale della pipeline è un CSV importabile in Google Ads Editor con le colonne nello schema esatto richiesto dalla piattaforma. Ads Editor è preferibile alla UI web per upload bulk per due motivi: la validazione preventiva degli errori prima del push e la possibilità di fare diff visivi tra stato locale e stato live.
Schema CSV Ads Editor: le colonne obbligatorie
| Colonna | Valore | Note |
|---|---|---|
| Campaign | Nome campagna esistente | Deve esistere o essere creata in altro foglio |
| Ad group | Nome cluster derivato dallo Stage 5 | Naming automatico da TF-IDF o LLM |
| Keyword | Testo keyword | Senza wildcard, lowercase consigliato |
| Match type | Broad, Phrase o Exact | Assegnazione automatica da regole cluster (vedi sotto) |
| Status | Enabled o Paused | Default consigliato Paused, attivazione manuale post-review |
| Max CPC | Cifra in euro (opzionale) | Sovrascritto se la campagna è in Smart Bidding |
| Final URL | Landing page assegnata | Derivata dal matching keyword-LP dello Stage 4 |
Assegnazione automatica match type per cluster
La regola operativa che funziona meglio in account misti:
- Exact per keyword con intent transactional, score > percentile 75, già presenti come query convertenti nel Search Terms storico.
- Phrase per keyword con intent commercial o transactional, score percentile 50-75. È il match type più equilibrato post-2021 dopo l’assorbimento del BMM.
- Broad da usare solo in campagne con Smart Bidding attivo (tCPA o tROAS) e con negative list robusta: senza queste due condizioni il broad disperde budget.
def assign_match_type(row, score_q75, score_q50, converting_terms: set) -> str:
kw = row["keyword"]
if row["intent"] == "transactional" and row["score"] >= score_q75 \
and kw in converting_terms:
return "Exact"
if row["intent"] in {"commercial", "transactional"} and row["score"] >= score_q50:
return "Phrase"
return "Broad"
q75 = df_kw["score"].quantile(0.75)
q50 = df_kw["score"].quantile(0.50)
df_kw["match_type"] = df_kw.apply(
lambda r: assign_match_type(r, q75, q50, converting_set), axis=1
)
cols = ["Campaign", "Ad group", "Keyword", "Match type",
"Status", "Max CPC", "Final URL"]
df_kw.rename(columns={"campaign": "Campaign", "cluster_name": "Ad group",
"keyword": "Keyword", "match_type": "Match type",
"max_cpc": "Max CPC", "final_url": "Final URL"}) \
.assign(Status="Paused")[cols] \
.to_csv("ads_editor_import.csv", index=False, encoding="utf-8-sig")
Checklist pre-attivazione
- Tutte le keyword caricate in stato Paused: attivazione progressiva per cluster, non massiva.
- Verifica che ciascun ad group abbia almeno 3 annunci responsive coerenti con il cluster semantico.
- Negative list dello Stage 6 già caricata prima di attivare le nuove campagne (importante: la negative deve precedere la live).
- Tracking di conversione testato end-to-end: senza Quality Score signal corretto dal day-1 lo Smart Bidding parte male e impiega settimane a recuperare.
- Per dettagli sull’ottimizzazione post-launch vedi come ottimizzare una campagna Google Ads.
Errori comuni e troubleshooting
Over-clustering: ad group troppo granulari
HDBSCAN con min_cluster_size troppo basso (es. 3-4) produce centinaia di micro-ad group con 5-10 keyword ciascuno. In Smart Bidding questa granularità diventa controproducente: ogni ad group ha pochi conversion event, il signal è rumoroso, l’algoritmo non riesce a ottimizzare. Regola empirica: nessun ad group sotto le 15 keyword se la campagna usa Smart Bidding. Soluzione: alzare min_cluster_size a 12-20, oppure fare un secondo step di merge cluster simili via cosine similarity sui centroidi (soglia 0.85).
Volume Planner overfit: il dato non coincide con il traffico reale
I volumi di Keyword Planner sono aggregati per varianti close-match: la stessa keyword in account diversi mostra spesso forchette larghe (es. 100-1K). In assenza di developer token con account a spesa alta, l’API restituisce range arrotondati. Per fare scoring affidabile su keyword vicine alla soglia di pruning, integrare i volumi DataForSEO o Google Trends come secondo segnale e prendere la mediana dei due. Per la corrispondenza ufficiale dei volumi degli account ad alta spesa, vedi la documentazione su generateKeywordHistoricalMetrics della Google Ads API Keyword Planning.
API rate limit e quota: pattern di retry e backoff
Google Ads API ha quote giornaliere e per-minute che variano con il tier dell’account (Basic vs Standard). Per pipeline che eseguono migliaia di chiamate, tre pattern obbligati:
- Batch size massimo: 10.000 keyword per
generateKeywordHistoricalMetrics, 20 seed pergenerateKeywordIdeas. Sopra queste soglie la chiamata fallisce silenziosamente. - Retry con exponential backoff sugli errori 429 (rate limit) e 503 (service unavailable): partire da 2 secondi e raddoppiare fino a 64 secondi, poi failure.
- Caching aggressivo dei risultati intermedi (parquet o sqlite) per non ri-chiamare le stesse keyword se la pipeline va in errore a metà strada.
Conclusioni e prossimi step
La pipeline descritta — dal seed GSC al CSV per Ads Editor — porta la keyword research da arte artigianale a processo ingegnerizzato e replicabile. Una volta consolidata, gira in un’ora su account di medie dimensioni e in 4-6 ore su account enterprise con catalogo multi-mercato. I benefici diretti misurabili nelle prime 4-8 settimane di campagna sono: copertura semantica più ampia del seed solo umano, ad group con coerenza interna superiore (Quality Score atteso più alto), e abbattimento del rumore Search Terms grazie alla negative list mining.
I prossimi step naturali sono due. Primo, automatizzare l’esecuzione settimanale dello Stage 6 (negative mining) per intercettare i nuovi search term che emergono man mano che le campagne maturano. Secondo, alimentare uno scoring di secondo livello con i dati di performance live (CTR, conversion rate, ROAS effettivi) per il feedback loop che ribilancia bid e match type ad ogni ciclo. Questa è la base per costruire un sistema di ottimizzazione continua delle campagne — argomento che merita una guida a sé.
Per supporto sulla progettazione o sull’audit di campagne Google Ads complesse vedi i nostri servizi di consulenza Google Ads.
Articoli correlati
Autore

Mi chiamo Giovanni Sacheli e dal 2009 aiuto le aziende a farsi trovare online. Sono specializzato in SEO tecnica e PPC, competenze che applico quotidianamente nella mia agenzia, Searcus Swiss Sagl. Mi piace sviluppare strumenti a supporto del mio lavoro, ho creato SEOdata.app e cluster.army e co-scritto il libro SEO Audit Avanzato. Curo maniacalmente questo blog per colleghi e appassionati, dove mi "appunto" quello che imparo. Sono un NERD anni '80, motociclista e orgoglioso papà di due bambini.
Link:
Giovanni Sacheli
SEO Audit Avanzato
Searcus Swiss Sagl
SEOdata.app
cluster.army
Commenti |2
Lascia un commentoProcesso pratico e utile, grazie Giovanni per la spiegazione. I tuoi articoli sono sempre interessanti!
Grazie Monica per il tuo feedback! Spero di trovarti presto in altri commenti :)