Il tool isitagentready.com, pubblicato da Cloudflare, esegue un audit automatizzato di una URL contro 18 standard tecnici emergenti che definiscono quanto un sito sia accessibile e utilizzabile da agenti AI: dalla discovery di base (robots.txt, sitemap, Link headers) alla content negotiation in Markdown, dal bot management crittografico (Web Bot Auth) ai protocolli di scoperta MCP, fino ai pattern di pagamento agent-native (x402, MPP, ACP). Lo scanner verifica well-known endpoint, header HTTP e direttive in robots.txt, e restituisce un punteggio progressivo per categoria. Questa guida è un walkthrough completo dei controlli eseguiti dal tool, con la spec di riferimento, il path well-known, un payload minimo di esempio e lo stato di adozione di ogni standard.
Cos’è isitagentready.com e cosa misura il tool Cloudflare
isitagentready.com è uno scanner client-side che testa una URL contro un insieme di endpoint /.well-known/, header HTTP e direttive in robots.txt rilevanti per l’accesso da parte di agenti AI. Il tool nasce all’interno dell’ecosistema Cloudflare Agents e rappresenta uno dei primi tentativi di consolidare in un’unica rubrica i protocolli che stanno definendo il cosiddetto agentic web: un web in cui il client non è più necessariamente un browser umano ma un agente AI che cerca, legge, autentica e — sempre più spesso — paga risorse in autonomia.
Il tool raggruppa i controlli in cinque categorie:
- Discoverability: robots.txt, sitemap XML, Link HTTP headers.
- Content Accessibility: Markdown content negotiation via
Accept: text/markdown. - Bot Access Control: regole per user-agent AI in robots.txt, Content Signals, Web Bot Auth.
- API, Auth, MCP & Skill Discovery: API Catalog, OAuth/OIDC discovery, OAuth Protected Resource, MCP Server Card, A2A Agent Card, Agent Skills index, WebMCP.
- Commerce: x402, MPP, UCP, ACP.
Lo scoring è incrementale per categoria. Il primo gradino è Level 1 — Basic Web Presence, che corrisponde al rispetto degli standard storici del web (robots.txt, sitemap, Link headers). Il secondo è Level 2 — Bot-Aware, raggiunto quando il sito implementa anche il controllo granulare sul traffico AI (regole specifiche per user-agent AI in robots.txt e Content Signals). I gradini successivi richiedono progressivamente l’implementazione degli standard di nuova generazione: content negotiation, signed bot identity, well-known discovery di API e MCP server, fino ai protocolli di pagamento agentico. È importante chiarire che molti dei protocolli verificati sono draft, proprietari o in early adoption: il punteggio non è una metrica SEO classica e non ha un peso noto sul ranking dei motori di ricerca. È una rubrica di future-readiness.
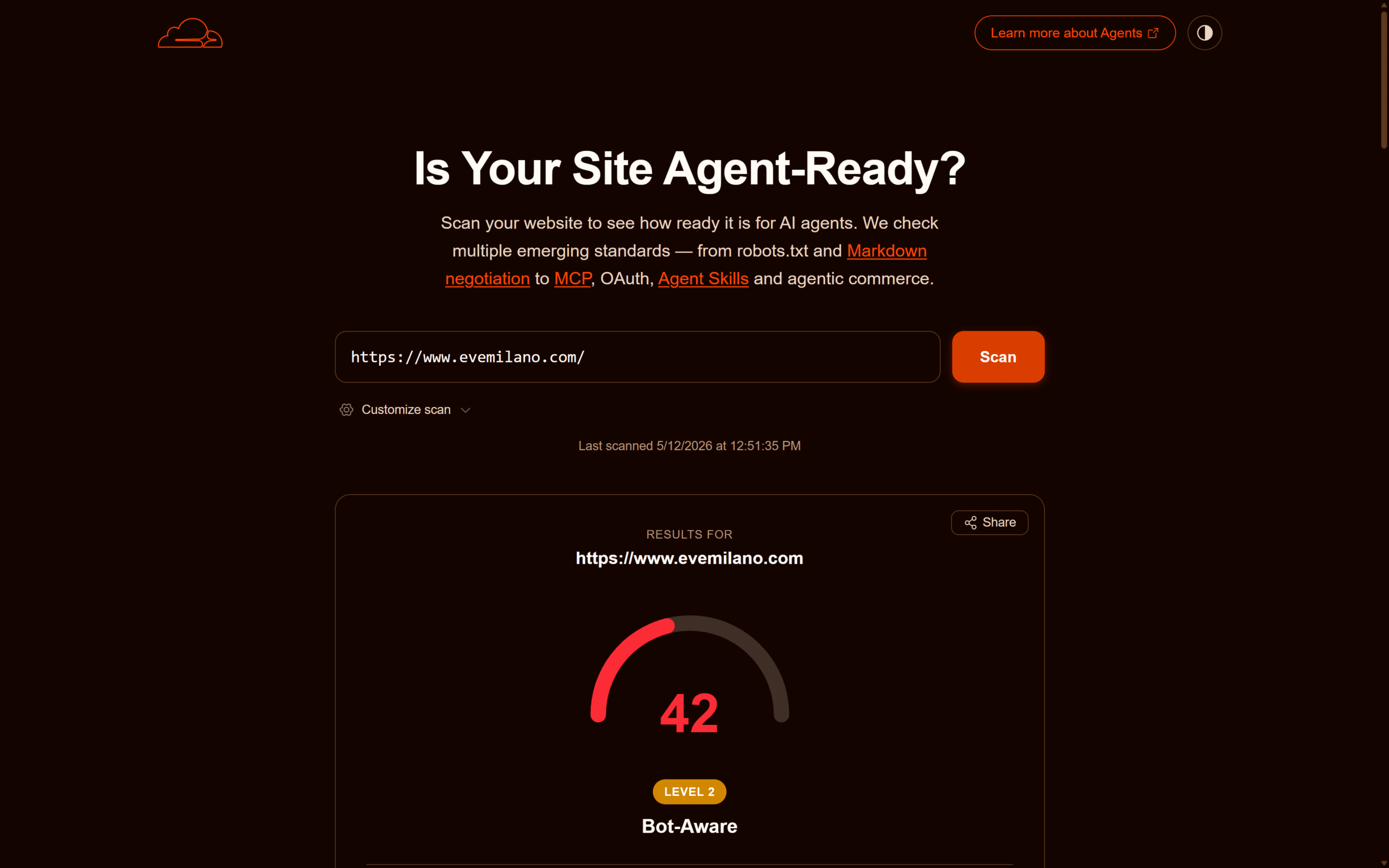
Case study: il punteggio di evemilano.com (da 33 a 42 dopo l’intervento sul robots.txt)
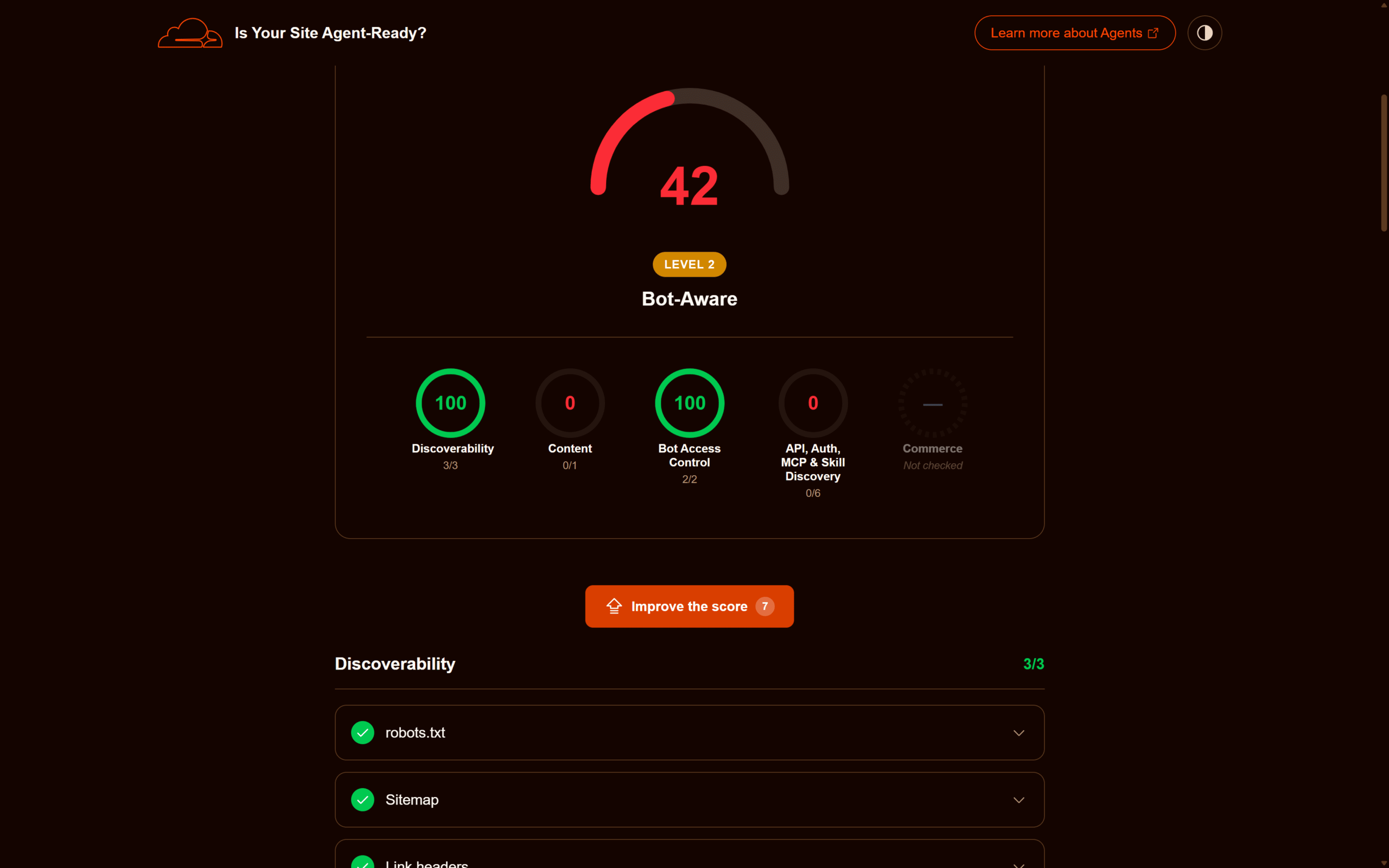
Per ancorare la guida a dati concreti, riporto i risultati di due scansioni successive di evemilano.com (WordPress + Cloudflare) eseguite il 12 maggio 2026. La prima, prima di toccare il robots.txt, ha restituito 33/100, Level 1 Basic Web Presence: il profilo tipico di un blog content-first dietro Cloudflare ma non ancora ottimizzato per i protocolli agentic. La seconda, dopo l’aggiunta delle direttive Content Signals al robots.txt, ha portato il punteggio a 42/100, Level 2 Bot-Aware, con il check Content Signals che passa da Fail a Pass e la categoria Bot Access Control che chiude a 2/2.
| Categoria | Prima (Level 1) | Dopo (Level 2) | Check superati (dopo) |
|---|---|---|---|
| Discoverability | 100 (3/3) | 100 (3/3) | robots.txt, sitemap, Link headers |
| Content Accessibility | 0 (0/1) | 0 (0/1) | no Markdown negotiation |
| Bot Access Control | 50 (1/2) | 100 (2/2) | Content Signals presenti, AI bot rules OK |
| API / Auth / MCP / Skill | 0 (0/6) | 0 (0/6) | nessun well-known agentic |
| Commerce | — | — | opzionale (non e-commerce) |
Il salto da 33 a 42 — e il passaggio da Level 1 a Level 2 — è arrivato con una modifica chirurgica al robots.txt (poche righe; il dettaglio è nella sezione Content Signals più avanti). L’osservazione operativa è doppia: la prima, che gli interventi a basso costo sui protocolli emergenti spostano davvero il punteggio del tool; la seconda, che la differenza tra Level 2 e i livelli successivi richiede investimenti di altra natura (Markdown negotiation lato edge, well-known agentici, eventualmente MCP server card o Agent Skills index) e raramente è giustificata per un blog content-first.
Discoverability: i tre pilastri storici del web crawlable
La prima categoria del tool è la più consolidata: i tre standard sono RFC pubblicati o convenzioni de facto con oltre vent’anni di adozione. Per un sito amministrato correttamente, questa categoria dovrebbe essere a 3/3 senza interventi.
robots.txt — RFC 9309
Il Robots Exclusion Protocol è stato finalmente standardizzato come RFC 9309 nel settembre 2022, dopo decenni di convenzione informale. Il file deve risiedere alla radice del dominio (/robots.txt), essere servito con Content-Type: text/plain in UTF-8, e contenere almeno una direttiva User-agent valida. Le direttive supportate dallo standard sono user-agent, allow, disallow e sitemap, con wildcard * e end-anchor $. La cache è di 24 ore; una risposta 5xx ripetuta equivale a un disallow totale.
Il tool verifica tre cose: status code 200, content-type corretto, presenza di almeno una direttiva User-agent valida. Non analizza la logica delle direttive (il sito non viene penalizzato se ha un disallow totale, e nemmeno premiato se distingue tra crawler diversi).
Sitemap XML
Lo standard sitemap è una convenzione de facto pubblicata su sitemaps.org (non è un RFC). Il path è libero, ma deve essere dichiarato in robots.txt tramite una direttiva Sitemap:. I limiti sono 50.000 URL e 50 MB uncompressed per singolo file; oltre quei limiti serve un sitemap index. WordPress genera automaticamente un sitemap index (/wp-sitemap.xml in versioni recenti, /sitemap_index.xml con Yoast o Rank Math), quindi questo check è in genere superato senza intervento.
Il tool estrae le direttive Sitemap: da robots.txt, fa una GET su ogni URL dichiarato e verifica che il payload sia XML valido. Non valida la struttura nel dettaglio (<loc>, <lastmod>) né controlla che gli URL elencati siano effettivamente raggiungibili.
Link headers — RFC 8288
L’header HTTP Link, definito da RFC 8288 (Web Linking), permette di dichiarare relazioni tra risorse senza aggiungere markup nel body. La sintassi è Link: <URI>; rel="relname"; param=value, con relazioni multiple separate da virgola. Per gli agenti AI, le relazioni più rilevanti sono alternate (versione alternativa della risorsa, tipicamente JSON per le pagine WordPress via WP REST API), describedby, service-desc (descrizione OpenAPI), api-catalog (puntatore al catalog dell’API) e canonical.
WordPress emette nativamente un header Link sulla homepage che include rel="https://api.w.org/" (puntatore al REST endpoint) e rel="alternate" con type="application/json" per ogni post/page renderizzata. Per il tool è sufficiente.
Link: <https://www.example.com/wp-json/>; rel="https://api.w.org/",
<https://www.example.com/wp-json/wp/v2/pages/123>; rel="alternate"; title="JSON"; type="application/json",
<https://www.example.com/>; rel="shortlink"Content Accessibility: Markdown content negotiation
Il check di Content Accessibility verifica un pattern emergente: servire la stessa URL come HTML al browser e come Markdown a un agente AI che richiede esplicitamente Accept: text/markdown. Il razionale è semplice: l’HTML di una pagina moderna contiene rumore (script, nav, sidebar, footer, banner cookie) che un LLM deve filtrare a runtime, sprecando token e introducendo errori di estrazione. Servire una versione Markdown già pulita riduce il costo di processing e migliora la qualità dell’estrazione del contenuto principale.
Non esiste un RFC dedicato a questo pattern: si appoggia alla content negotiation standard di RFC 9110 (HTTP Semantics). Cloudflare promuove l’implementazione lato edge con una feature dedicata che intercetta la richiesta, controlla l’header Accept, e — se vale text/markdown — converte al volo l’HTML in Markdown rispondendo con Content-Type: text/markdown. Quando disponibile, la risposta include anche un header x-markdown-tokens che dichiara il numero di token Markdown nella risposta.
GET / HTTP/1.1
Host: www.example.com
Accept: text/markdown
HTTP/1.1 200 OK
Content-Type: text/markdown; charset=utf-8
x-markdown-tokens: 1842
# Titolo della pagina
Lead paragraph in markdown pulito, senza nav, sidebar, script.
## Sezione
Contenuto principale...Il tool fa una GET alla homepage con Accept: text/markdown e verifica che il Content-Type di risposta sia text/markdown (e non il fallback text/html). Sui siti dietro Cloudflare l’implementazione è una toggle nel dashboard; per stack auto-ospitati va costruita a livello applicativo o di reverse proxy. Su WordPress non esiste oggi un plugin core che fornisca questa funzionalità: l’opzione pragmatica è un middleware (Cloudflare Workers, Nginx + sub_filter, Varnish VCL) che converta l’HTML renderizzato in Markdown via una libreria server-side (turndown in JavaScript, html2text in Python).
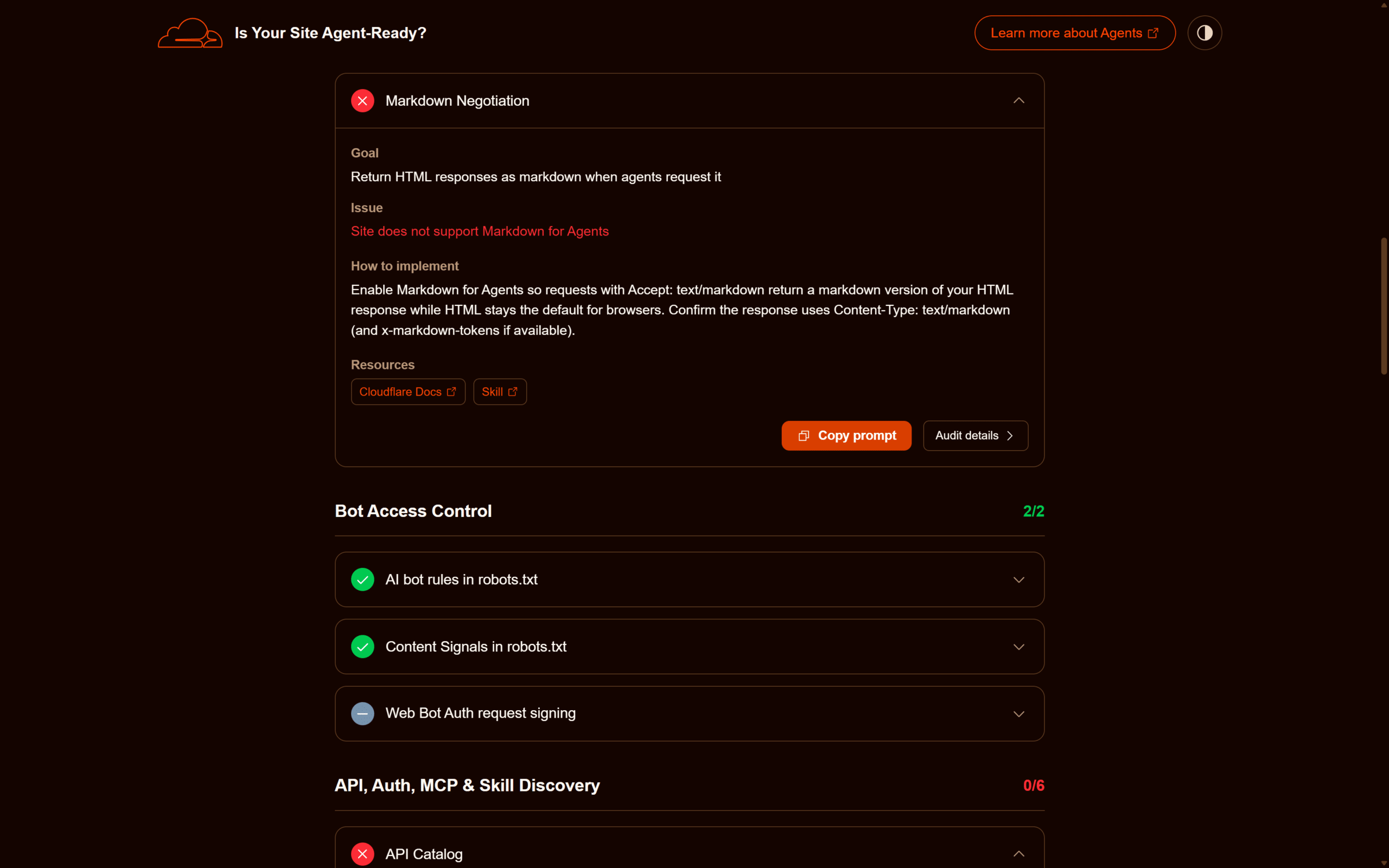
Il pattern non va confuso con altri esperimenti recenti orientati a fornire una versione testuale dei contenuti agli LLM, alcuni dei quali partono da assunti diversi (file statico vs negotiation runtime) e hanno avuto un’adozione molto disomogenea. La content negotiation HTTP, al contrario, è ortodossa rispetto allo stack web standard e non richiede convenzioni nuove al di fuori del response header.
Bot Access Control: tre livelli di controllo sul traffico AI
La categoria Bot Access Control raccoglie tre meccanismi complementari: regole dichiarative per user-agent in robots.txt, segnali di intent granulari sull’uso del contenuto (Content Signals) e identità crittografica verificabile dei bot (Web Bot Auth). I tre livelli rispondono a problemi distinti e dovrebbero coesistere, non sostituirsi.
AI bot rules in robots.txt
Il check è soddisfatto quando robots.txt contiene direttive User-agent specifiche per i bot AI, distinte dalle regole wildcard (User-agent: *). La scelta tra Allow e Disallow è policy editoriale; il tool non giudica la decisione, ma verifica che la decisione esista. Una regola wildcard applicata a tutti i crawler è considerata insufficiente perché impedisce di differenziare il trattamento tra search bot (es. Googlebot) e training bot (es. GPTBot).
I principali user-agent AI da considerare in robots.txt, raccolti dalla documentazione ufficiale dei singoli vendor:
| Vendor | User-agent | Uso dichiarato |
|---|---|---|
| OpenAI | GPTBot | Training dei modelli GPT |
| OpenAI | OAI-SearchBot | Indicizzazione per ChatGPT Search |
| OpenAI | ChatGPT-User | Fetch on-demand quando l’utente chiede |
| Anthropic | ClaudeBot | Training Claude |
| Anthropic | anthropic-ai, Claude-Web | Crawler legacy / on-demand |
| Google-Extended | Training Gemini, Vertex (separato da Googlebot) | |
| Perplexity | PerplexityBot | Indexing per Perplexity |
| Perplexity | Perplexity-User | Fetch on-demand |
| Common Crawl | CCBot | Dataset pubblico (training upstream) |
| ByteDance | Bytespider | Training Doubao / Coze |
| Apple | Applebot-Extended | Training Apple Intelligence |
| Meta | Meta-ExternalAgent | Training Llama / fetch |
Esempio di policy granulare che blocca il training ma consente l’indicizzazione per search agentica:
# Blocco training
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: Applebot-Extended
Disallow: /
# Consentito on-demand fetch e search agentica
User-agent: OAI-SearchBot
Allow: /
User-agent: ChatGPT-User
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: Perplexity-User
Allow: /
# Default
User-agent: *
Allow: /
Sitemap: https://www.example.com/sitemap_index.xmlLa compliance dei vendor è volontaria: l’efficacia del blocco dipende dal rispetto della direttiva da parte del bot. Per un enforcement reale serve un layer aggiuntivo (firewall per user-agent o reverse-DNS verification), su cui Web Bot Auth interviene in modo strutturale.
Content Signals: search, ai-input, ai-train
Content Signals è un’estensione di robots.txt promossa da Cloudflare a settembre 2025 per separare in tre intent distinti l’uso del contenuto: search (indicizzazione tradizionale e search agentica), ai-input (uso come grounding/RAG in risposta in tempo reale), ai-train (uso per addestramento dei modelli). Ogni intent può essere settato a yes o no. La direttiva è leggibile dai crawler che la onorano e, separatamente, è invocabile in sede legale come dichiarazione esplicita di policy editoriale (Cloudflare include un disclaimer giuridico nel testo iniettato di default).
La sintassi si innesta dentro un blocco User-agent di robots.txt:
User-Agent: *
Content-Signal: search=yes, ai-train=no, ai-input=no
Allow: /Il vocabolario è oggetto di una proposta IETF parallela nel working group aipref: i draft draft-ietf-aipref-vocab e draft-ietf-aipref-attach stanno cercando di consolidare il vocabolo (con etichette analoghe come train-ai, search) e i meccanismi di attachment. Allo stato attuale, Content Signals è un signal dichiarativo: nessun bot AI ha annunciato pubblicamente di onorarlo in produzione, ma la sua presenza nel sito serve come prova di policy esplicita e — sui siti dietro Cloudflare — viene auto-iniettato di default. Per dichiararlo manualmente su WordPress è sufficiente modificare il robots.txt fisico (o sovrascriverlo tramite filtro robots_txt di WordPress). Come anticipato nel case study, l’aggiunta della direttiva al robots.txt di evemilano.com è stato l’intervento che ha fatto passare il check Content Signals da Fail a Pass e portato il punteggio del sito da 33 a 42.
L’intent ai-input merita attenzione: comunicare ai sistemi RAG che il contenuto non deve essere usato come grounding influenza la visibilità della risorsa nei retrieval pipeline degli LLM. Chi punta a essere citato da ChatGPT, Perplexity e Gemini ha interesse opposto a chi vuole proteggere proprietà intellettuale, quindi la scelta delle tre direttive richiede una decisione editoriale prima ancora che tecnica. Per un’analisi del retrieval lato LLM si veda RAG SEO: reverse engineering del Retrieval-Augmented Generation.
Web Bot Auth: identità crittografica dei bot
Web Bot Auth è lo standard più ambizioso della categoria. L’idea è semplice: invece di affidarsi a reverse-DNS lookup o liste di range IP per verificare l’identità di un bot, ogni bot firma le proprie richieste HTTP con una chiave Ed25519, pubblica la chiave pubblica in una directory ben definita sul proprio dominio, e il server destinatario verifica la firma in tempo reale. Il sito che vuole consumare l’identità del bot deve pubblicare a sua volta una directory analoga se ha un ruolo nello scambio (es. emette token o counter-firmate).
La spec si appoggia a RFC 9421 (HTTP Message Signatures) per la crittografia, e a due draft IETF in lavorazione: draft-meunier-web-bot-auth-architecture (directory di chiavi) e draft-meunier-http-message-signatures-bots (uso nel contesto bot). Cloudflare ha pubblicato l’implementazione di riferimento e l’approccio operativo nel proprio bot management.
Il path well-known per la directory è /.well-known/http-message-signatures-directory, servito con Content-Type: application/http-message-signatures-directory+json. Payload minimo:
{
"keys": [
{
"kty": "OKP",
"crv": "Ed25519",
"x": "11qYAYKxCrfVS_7TyWQHOg7hcvPapiMlrwIaaPcHURo",
"kid": "key-2026-01"
}
]
}La risposta stessa va firmata, con header Signature e Signature-Input che includano i parametri tag="http-message-signatures-directory", keyid (JWK thumbprint), created, expires e i componenti coperti (almeno @authority). Il tool isitagentready esegue una GET sul path e verifica che la risposta sia 200; non valida i campi crittografici nel dettaglio.
Per un sito content-only la pubblicazione di una propria directory ha senso solo se si vuole emettere identità per agenti propri (es. un bot di scraping interno che si autentica verso le proprie API). Per un blog WordPress il check resta in genere irrilevante: l’attivazione di Web Bot Auth lato consumer (verificare i bot in ingresso) è invece feature di Cloudflare Bot Management, e non passa dal codice del sito.
API, Auth, MCP & Skill Discovery: sette well-known per l’agentic web
La quarta categoria raccoglie sette check su altrettanti meccanismi di discovery: dall’enumerazione di API pubbliche all’esposizione di tool MCP, dall’autenticazione OAuth a protocolli di pacchettizzazione di skill riusabili. Per un sito content-only la maggior parte di questi check è inapplicabile e il punteggio resta basso. Per SaaS, API platform e siti che espongono funzionalità programmabili è qui che si concentra il valore del tool. Dal lato client, conoscere dove i server MCP vengono registrati aiuta a debuggare problemi di discovery: ho documentato il filesystem di un client MCP popolare (Claude Code) come reference.
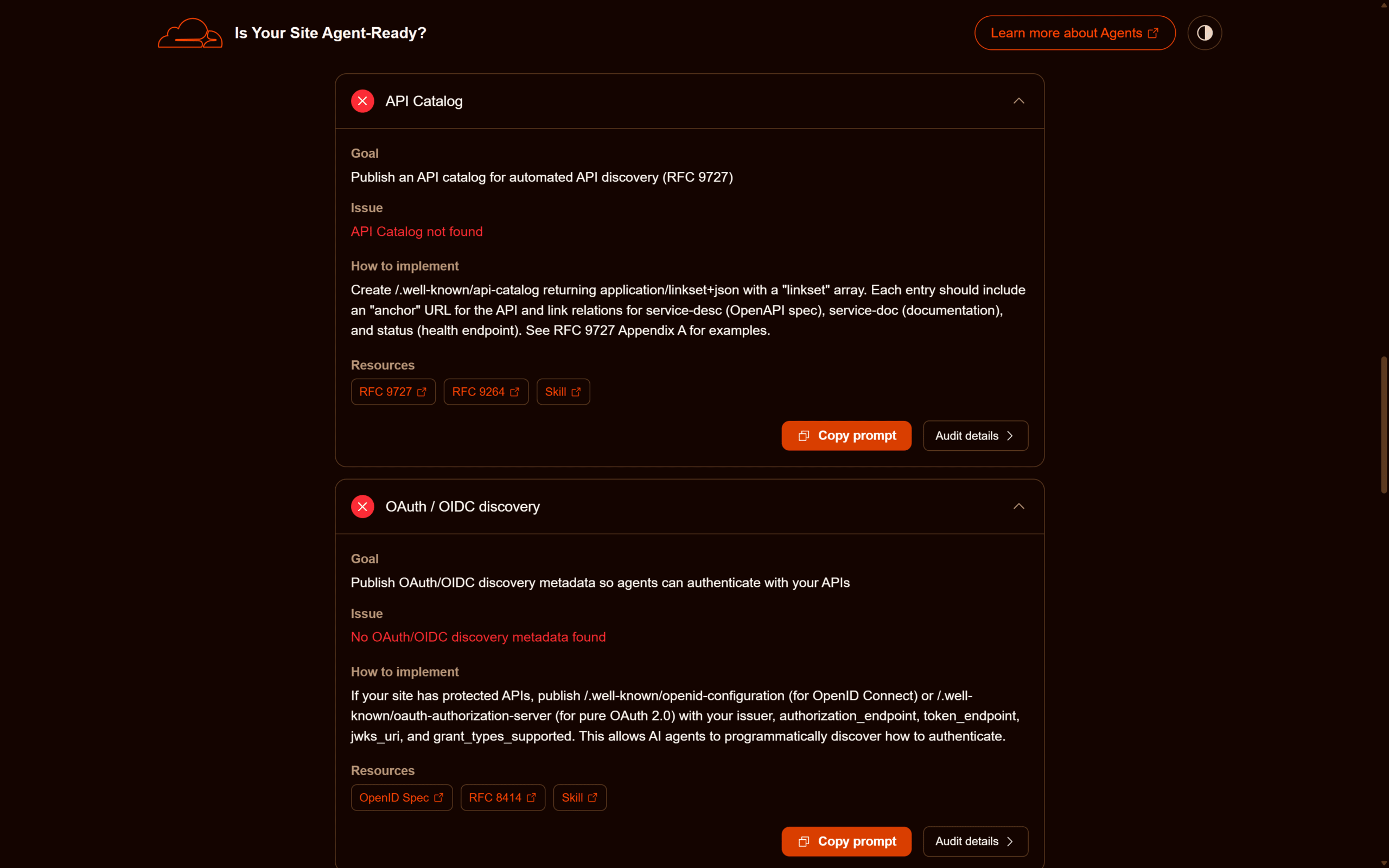
API Catalog — RFC 9727
RFC 9727 definisce un meccanismo di discovery per i cataloghi di API esposti da un dominio. Il documento è servito da /.well-known/api-catalog con Content-Type: application/linkset+json, secondo il formato Linkset di RFC 9264. Ogni voce del linkset include un anchor (URI base dell’API) e un set di link relation: service-desc (specifica OpenAPI/AsyncAPI), service-doc (documentazione human-readable), status (endpoint di health).
{
"linkset": [
{
"anchor": "https://api.example.com/v1",
"service-desc": [
{ "href": "https://api.example.com/v1/openapi.json", "type": "application/openapi+json" }
],
"service-doc": [
{ "href": "https://developer.example.com/v1", "type": "text/html" }
],
"status": [
{ "href": "https://api.example.com/v1/health" }
]
}
]
}L’adozione è bassa: l’RFC è del 2024 e nessun agente major lo richiede oggi come precondizione, ma è il candidato più solido per la discovery autonoma di API da parte di agenti AI nel medio periodo.
OAuth / OIDC discovery
Il check verifica la presenza di metadati di discovery per OAuth 2.0 e OpenID Connect. Due path possibili:
/.well-known/oauth-authorization-server— RFC 8414, OAuth 2.0 Authorization Server Metadata./.well-known/openid-configuration— OpenID Connect Discovery 1.0, path legacy ma ancora ampiamente usato.
Il documento descrive gli endpoint dell’authorization server in JSON: issuer, authorization_endpoint, token_endpoint, jwks_uri, scopes_supported, response_types_supported, grant_types_supported, token_endpoint_auth_methods_supported. Per un agente AI che vuole autenticarsi a un’API protetta del sito, questo è il primo punto di partenza: legge il documento, identifica gli endpoint, esegue il flow OAuth appropriato.
{
"issuer": "https://auth.example.com",
"authorization_endpoint": "https://auth.example.com/oauth/authorize",
"token_endpoint": "https://auth.example.com/oauth/token",
"jwks_uri": "https://auth.example.com/.well-known/jwks.json",
"response_types_supported": ["code"],
"grant_types_supported": ["authorization_code", "refresh_token", "client_credentials"],
"scopes_supported": ["openid", "profile", "read", "write"],
"token_endpoint_auth_methods_supported": ["client_secret_basic", "client_secret_post"]
}Per un sito content-only senza API protette, questo check è strutturalmente inapplicabile. È rilevante per SaaS, identity provider e qualsiasi piattaforma che voglia consentire ad agenti AI di operare per conto degli utenti.
OAuth Protected Resource — RFC 9728
RFC 9728, pubblicato ad aprile 2025, complementa RFC 8414: mentre quest’ultimo descrive un authorization server, RFC 9728 descrive una protected resource, cioè un’API che richiede bearer token. La resource pubblica i metadati su /.well-known/oauth-protected-resource (o un path resource-specific), dichiarando quali authorization server possono emettere token validi e quali scope sono supportati.
{
"resource": "https://api.example.com",
"authorization_servers": ["https://auth.example.com"],
"bearer_methods_supported": ["header"],
"scopes_supported": ["read", "write", "admin"],
"resource_documentation": "https://developer.example.com/api"
}Il pattern è alla base del nuovo flow MCP-over-OAuth: un agente che si connette a un MCP server protetto legge da qui quale authorization server consultare, esegue il flow OAuth lì, riceve il token, e lo presenta al server MCP. Anche qui, applicabilità limitata ai siti che espongono API protette.
MCP Server Card — SEP-2127
Il Model Context Protocol (MCP) è lo standard rilasciato da Anthropic per esporre tool, risorse e prompt agli agenti AI tramite un transport JSON-RPC. Fino al 2025 mancava un meccanismo di discovery pre-connessione: per scoprire le capability di un server MCP era necessario completare l’handshake. La SEP-2127 (in stato di pull request aperta sul repository ufficiale al momento della scrittura) introduce il concetto di Server Card: un documento statico, ospitato su /.well-known/mcp/server-card.json, che dichiara identità, versione, trasporti supportati, capability e — ove rilevante — il requisito di OAuth Protected Resource per autenticarsi.
{
"$schema": "https://modelcontextprotocol.io/schemas/server-card-1.0.json",
"name": "example-mcp-server",
"title": "Example MCP Server",
"description": "Esempio di server MCP per query su un dataset interno.",
"version": "1.2.0",
"supportedProtocolVersions": ["2025-06-18"],
"remotes": [
{
"transport": "streamable-http",
"endpoint": "https://mcp.example.com/v1",
"auth": {
"type": "oauth2",
"metadata": "https://api.example.com/.well-known/oauth-protected-resource"
}
}
],
"capabilities": {
"tools": true,
"resources": true,
"prompts": false
}
}Lo stato della spec è in evoluzione attiva: chi implementa la Server Card oggi dovrebbe seguire la PR sul repository modelcontextprotocol/modelcontextprotocol per evitare drift rispetto alla versione che verrà merge nello standard. Per un approfondimento sull’architettura MCP si veda MCP Server: l’architettura silente del Web intelligente.
A2A Agent Card
Il protocollo Agent-to-Agent (A2A) è promosso da Google con una governance multi-stakeholder. Definisce un transport e un formato di discovery per consentire a un agente di scoprire, contattare e collaborare con un altro agente. L’analogo della Server Card MCP qui è la Agent Card, un documento JSON che descrive l’agente, le sue capability e gli endpoint di interazione.
Il path tipico è /.well-known/agent.json (le revisioni successive della spec hanno proposto anche agent-card.json per coerenza con MCP). La specifica è gestita sul repository google-a2a/A2A ed è in stato di draft attivo. L’adozione attuale è confinata all’ecosistema Google e ad alcuni partner; per un sito generalista questo check rimane oggi puramente prospettico.
Agent Skills discovery index
Il formato Skills, introdotto da Anthropic, definisce pacchetti riusabili di istruzioni e risorse (un file SKILL.md con frontmatter e contenuto, opzionalmente accompagnato da asset) che un agente AI carica al bisogno per acquisire capability puntuali. Il meccanismo di discovery è normato dal cloudflare/agent-skills-discovery-rfc v0.2.0: l’index è ospitato su /.well-known/agent-skills/index.json e referenzia uno schema su schemas.agentskills.io.
{
"$schema": "https://schemas.agentskills.io/discovery/0.2.0/schema.json",
"skills": [
{
"name": "seo-audit-checklist",
"type": "skill-md",
"description": "Checklist di audit SEO tecnico per siti enterprise.",
"url": "/.well-known/agent-skills/seo-audit-checklist/SKILL.md",
"digest": "sha256:9f86d081884c7d659a2feaa0c55ad015a3bf4f1b2b0b822cd15d6c15b0f00a08"
},
{
"name": "schema-org-validator",
"type": "archive",
"description": "Tool per validare dati strutturati JSON-LD.",
"url": "/.well-known/agent-skills/schema-org-validator.tar.gz",
"digest": "sha256:e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855"
}
]
}Sono previsti due tipi: skill-md (singolo file Markdown) e archive (bundle tar.gz/zip). Il digest SHA-256 protegge l’integrità del download lato agente. Il formato Skills è già onorato da numerosi client (Claude, Claude Code, Cursor, GitHub Copilot, Gemini CLI, OpenCode); la discovery via well-known è invece adoption-early. Per un sito che pubblica metodologie tecniche replicabili, esporre l’indice di skill è un investimento interessante: trasforma documentazione passiva in unità funzionali consumabili da agenti.
WebMCP: tool MCP direttamente dal browser
WebMCP è una proposta del W3C Web Machine Learning Community Group (draft pubblicato) che porta il modello MCP direttamente dentro il runtime JavaScript della pagina web. Invece di registrare i tool su un server MCP separato, lo script della pagina chiama navigator.modelContext.provideContext() e dichiara tool eseguibili lato client (con name, description, inputSchema e callback execute). Un browser-agent capace di leggere l’API può scoprire i tool a runtime senza alcuna integrazione lato server.
navigator.modelContext.provideContext({
tools: [
{
name: "addToCart",
description: "Aggiunge un prodotto al carrello del sito.",
inputSchema: {
type: "object",
properties: {
sku: { type: "string" },
quantity: { type: "integer", minimum: 1 }
},
required: ["sku", "quantity"]
},
execute: async ({ sku, quantity }) => {
const res = await fetch("/cart/add", {
method: "POST",
body: JSON.stringify({ sku, quantity })
});
return res.json();
}
}
]
});Lo stato della spec è Community Group Draft: non è una Recommendation W3C e nessun browser stable ha ancora shippato l’API. È rilevante per anticipare l’adozione futura, non per la produzione 2026. Il check del tool fa il page load e verifica la presenza di navigator.modelContext con tool registrati: in assenza dell’implementazione browser, il check fallisce strutturalmente su qualsiasi sito.
Commerce: quattro protocolli di pagamento agentico
La categoria Commerce raggruppa quattro standard concorrenti per consentire ad agenti AI di pagare risorse o effettuare acquisti senza intervento umano. Il tool dichiara la categoria opzionale per i siti non e-commerce e non penalizza il punteggio in assenza di implementazione. Per piattaforme commerciali e API a consumo, è qui che si gioca la partita di lungo periodo.
x402: pagamenti HTTP nativi
x402 è un open standard sponsorizzato da Coinbase che riusa lo status HTTP 402 Payment Required (riservato da decenni nello standard HTTP e mai utilizzato) come trigger per un flow di pagamento. Il flow è:
- Client GET
/risorsa. - Server risponde
402con un payload che dichiara importo, valuta accettata, indirizzo destinazione (tipicamente on-chain, USDC stablecoin). - Client esegue la transazione (firma una tx on-chain o usa un payment channel).
- Client ripete la richiesta con un header che prova il pagamento.
- Server verifica la prova e serve la risorsa con
200.
Il protocollo è network-agnostic ma la documentazione di riferimento privilegia stablecoin su EVM. Lo use case naturale è il consumo a micropagamento di API agentiche (per fetch, per inference, per dataset). Il tool di discovery del tool isitagentready è /platform/v2/x402/discovery/resources, un endpoint bazaar gestito centralmente che enumera risorse a pagamento di provider partecipanti.
MPP — Machine Payments Protocol
MPP affronta lo stesso problema di x402 con un’angolazione enterprise/fiat. Sviluppato congiuntamente da Tempo e Stripe, è in processo di standardizzazione presso IETF. La discovery non passa da un well-known dedicato ma da un’estensione del documento OpenAPI dell’API: ogni operation che richiede pagamento dichiara nel proprio descriptor un’extension x-payment-info con intent (charge o session), method (tempo, stripe, lightning, card), amount e currency.
Il tool isitagentready verifica MPP cercando un documento OpenAPI su /openapi.json e parsando eventuali estensioni di pagamento. Per piattaforme che già espongono OpenAPI, l’integrazione è una modifica chirurgica al descriptor; il payment handling è poi gestito da SDK ufficiali (mppx per TypeScript, pympp per Python) e middleware framework-specific (Hono, Express, Next.js, Elysia).
UCP — Universal Commerce Protocol
Il check UCP testa la presenza di /.well-known/ucp. Allo stato della scrittura, la spec primaria di UCP non è pubblicamente verificabile: il tool isitagentready elenca il check ma il repository di riferimento non è facilmente reperibile e la documentazione pubblica appare scarsa. È plausibile che si tratti di una proposta Cloudflare in early stage o non ancora resa pubblica nella versione completa. Chi vuole implementarlo dovrebbe attendere il rilascio della spec ufficiale o cercare comunicazione diretta con il team Cloudflare Agents. Riporto il dettaglio per completezza del walkthrough, ma sconsiglio di investire in UCP fino a quando non sarà disponibile una specifica con un percorso di governance chiaro.
ACP — Agentic Commerce Protocol
ACP è il protocollo dietro la feature “Buy it in ChatGPT” lanciata nel settembre 2025, sviluppato congiuntamente da OpenAI e Stripe. Definisce il flow agente-merchant-utente per consentire l’acquisto di un prodotto direttamente da una conversazione con un agente, senza dover passare dal sito del merchant. Il merchant pubblica un documento di discovery su /.well-known/acp.json che dichiara endpoint di catalog, checkout, conferma ordine e webhook di stato.
Lo stato della spec è in shaping pubblico: il sito agentcommerceprotocol.com è online ma la documentazione canonica si è spostata di recente e alcuni asset (schema JSON, repository GitHub) non sono sempre accessibili. Prima di implementare ACP è prudente recuperare l’ultima versione del materiale dal sito ufficiale e dai canali OpenAI/Stripe. Per un e-commerce italiano l’esposizione su ChatGPT shopping è oggi limitata a partnership selezionate, ma il pattern ACP è il candidato di riferimento per la prossima generazione di commerce agentico.
Mappa di priorità per tipo di sito
Non tutti gli standard hanno senso su qualunque sito. La tabella che segue mappa i 18 check in tre profili tipici: content site (blog, magazine, sito corporate), SaaS/API platform, e-commerce. La priorità alta significa che il check è applicabile e ha un ritorno concreto; media significa che è applicabile ma il valore è prospettico (draft/early adoption); bassa significa strutturalmente inapplicabile o non rilevante.
| Standard | Content site | SaaS / API | E-commerce |
|---|---|---|---|
| robots.txt | Alta | Alta | Alta |
| Sitemap XML | Alta | Media | Alta |
| Link headers | Alta | Alta | Alta |
| Markdown negotiation | Alta | Media | Alta |
| AI bot rules | Alta | Media | Alta |
| Content Signals | Alta | Bassa | Media |
| Web Bot Auth | Bassa | Media | Media |
| API Catalog | Bassa | Alta | Media |
| OAuth / OIDC discovery | Bassa | Alta | Media |
| OAuth Protected Resource | Bassa | Alta | Media |
| MCP Server Card | Bassa | Alta | Media |
| A2A Agent Card | Bassa | Media | Bassa |
| Agent Skills index | Media | Alta | Media |
| WebMCP | Bassa | Media | Media |
| x402 | Bassa | Media | Media |
| MPP | Bassa | Media | Media |
| UCP | Bassa | Bassa | Bassa |
| ACP | Bassa | Bassa | Alta |
L’osservazione operativa è che un content site WordPress oggi può puntare a un punteggio sostenibile concentrandosi su sette standard: i tre della Discoverability (già coperti out-of-the-box), Markdown negotiation (richiede edge o middleware), AI bot rules (modifica al robots.txt), Content Signals (modifica al robots.txt) e — opzionalmente — Agent Skills se il sito pubblica metodologie operative. Web Bot Auth come emettitore non porta valore al content site lato pubblicazione; vale invece come consumer lato firewall, ma quella feature è disponibile tramite Cloudflare Bot Management senza intervento sul codice.
Cosa non misura il tool
Un punteggio alto su isitagentready certifica che gli endpoint well-known esistono e sono ben formati, non che il sito sia effettivamente leggibile da un agente AI. Le aree non coperte dal tool sono spesso quelle dove si gioca la visibilità reale nei sistemi LLM:
- Rendering JavaScript lato bot AI. Il tool fa una GET alla homepage e legge gli header, non valuta come ChatGPT, Claude o Gemini eseguono il rendering del DOM. Molti siti SPA in React/Next.js senza SSR funzionano in browser ma sono opachi per i fetcher AI. Per un’analisi pratica si veda Test SEO: ChatGPT, Gemini e Claude riescono a leggere siti JavaScript?.
- Dati strutturati Schema.org. Nessuno dei check verifica JSON-LD nel body, le tipologie schema usate (Article, Product, FAQPage, HowTo, Organization), la consistenza dell’entity graph del sito. Eppure lo schema è uno dei segnali più forti per la disambiguazione semantica degli LLM.
- Qualità del contenuto per il retrieval. Densità informativa, struttura semantica delle heading, chunking compatibile con i RAG pipeline degli LLM: tutto fuori dal perimetro del tool.
- Accessibilità classica WCAG. Pur essendo un fattore che molti LLM-fetcher rispettano (attributi alt, struttura heading, ruoli ARIA), nessun check di isitagentready la valuta.
- Performance e budget di crawl AI. Time-to-first-byte, dimensione della risposta, stabilità del server sotto carico bot — non misurati.
- Verifica reale del rispetto delle direttive. Il tool valida che robots.txt esista e contenga AI bot rules, ma non testa se i bot dichiarati onorano effettivamente le direttive. Quella verifica richiede log analysis lato server.
In altri termini: isitagentready è una checklist di conformità protocollare, non un audit di accessibilità AI a tutto tondo. Le due metriche correlano debolmente. Un sito può avere punteggio 100 e restare di fatto opaco agli LLM (es. SPA non renderizzabile lato bot); un sito può avere punteggio basso e essere comunque ben citato da ChatGPT e Perplexity (es. blog statico con HTML pulito e schema completo).
Conclusioni: agent-readiness come vettore SEO 2026
Il valore di isitagentready non sta nel punteggio assoluto ma nella mappa di standard che consolida. Per chi presidia SEO tecnico, conoscere i 18 check significa conoscere la roadmap dei protocolli che stanno definendo l’accesso autonomo al web da parte degli agenti AI: da quali RFC seguire (9421, 9727, 9728, draft aipref WG) a quali well-known anticipare (Web Bot Auth, MCP Server Card, Agent Skills). La maggioranza degli standard è ancora in early adoption e l’effetto sul ranking dei motori di ricerca tradizionali è nullo. Ma l’inerzia favorisce chi si muove prima: implementare oggi Markdown negotiation, Content Signals e AI bot rules costa poco e qualifica il sito come early mover su un asse che diventerà rilevante in 12-24 mesi.
Per i siti più complessi — JavaScript-heavy, multilingua, e-commerce con catalogo grande, portali editoriali con archivi profondi — il tool restituisce una foto incompleta: non testa il rendering, non valida lo schema, non misura la qualità semantica del contenuto per il retrieval LLM. Se vuoi un audit completo della reale accessibilità del tuo sito a motori di ricerca, agenti e LLM — che integra l’analisi dei protocolli emergenti con l’analisi di rendering, entity graph, dati strutturati e crawlability lato bot AI — il servizio Analisi Accessibilità Web per Motori di Ricerca e AI copre l’intero perimetro.
Articoli correlati
Autore

Mi chiamo Giovanni Sacheli e dal 2009 aiuto le aziende a farsi trovare online. Sono specializzato in SEO tecnica e PPC, competenze che applico quotidianamente nella mia agenzia, Searcus Swiss Sagl. Mi piace sviluppare strumenti a supporto del mio lavoro, ho creato SEOdata.app e cluster.army e co-scritto il libro SEO Audit Avanzato. Curo maniacalmente questo blog per colleghi e appassionati, dove mi "appunto" quello che imparo. Sono un NERD anni '80, motociclista e orgoglioso papà di due bambini.
Link:
Giovanni Sacheli
SEO Audit Avanzato
Searcus Swiss Sagl
SEOdata.app
cluster.army