Dopo aver creato una sitemap.xml la cosa migliore da fare è verificarla. La sitemap.xml di un sito web è un elemento molto importante da tenere curato, verificarne la correttezza sintattica e la completezza è un’attività necessaria quando si svolge un SEO Audit.
TL;TR
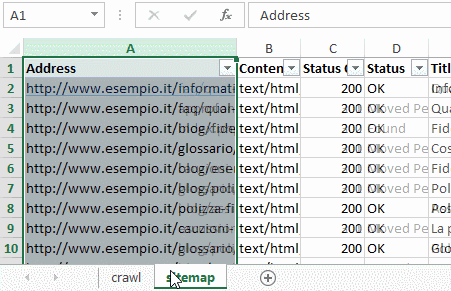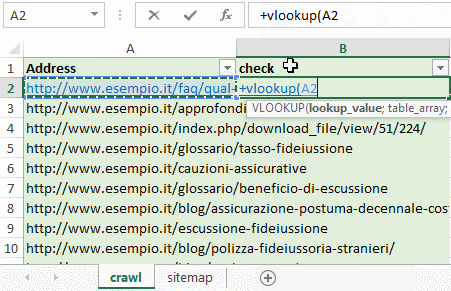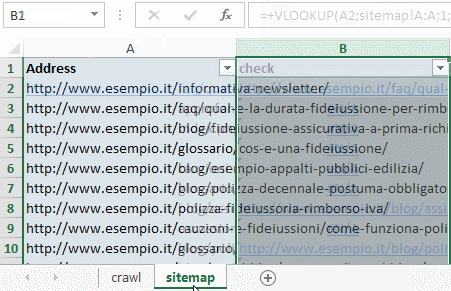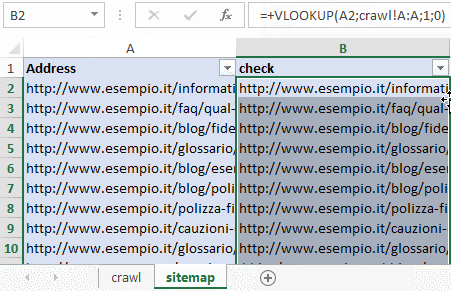
Per verificare la correttezza di una sitemap.xml la prima cosa che faccio e scansionare il sito web per contare il numero di URL canonici, unici, che vengono dati in pasto a Google per essere indicizzati. Trovo il conteggio totale delle pagine indicizzabili nel sito web mi segno questo valore.
Poi scarico la sitemap.xml e la passo in Screaming Frog. Verifico quante pagine sono inserite con status code 200 e canonical unico, quindi le pagine realmente indicizzabili dai motori di ricerca. Confronto il conteggio con il valore della scansione, eventuali differenze sono da approfondire per capire se esiste un problema o no.
Successivamente, in un file Excel creo due fogli: nel primo foglio metto i dati esportati dalla scansione del sito e nel secondo foglio metto i dati di scansione della sitemap.xml. Con la funzione cerca verticale – Vertical lookup usata su entrambi i fogli, confronto i dati.
Parto dai dati di scansione e con la vertical lookup verifico se ci sono URL indicizzabili non inseriti in sitemap.xml.
Poi analizzo i dati della sitemap.xml per verificare se ci sono URL che non ho trovato durante la scansione.
L’ultimo controllo è per verificare eventuali 404 in sitemap.xml da rimuovere o correggere.
Per quanto riguarda il formato e la sintassi corretta della sitemap.xml ti rimando a questa guida, oggi invece ti mostrerò come controllare con Excel e Screaming Frog la completezza della Sitemap.xml, ovvero se la sitemap contiene tutti gli URL che ci si aspetterebbe, il tutto in due semplice passaggi:
- Verificare che tutti gli URL in Sitemap.xml siano raggiungibili
- Verificare che tutte le pagine navigabili siano inserite in sitemap.xml
Prepara i dati per l’analisi
Inizia facendo crawling delle sole pagine HTML del sito web, escludi quindi le immagini, CSS e JavaScript. Io uso Screaming Frog ma puoi usare qualsiasi crawler.
A processo terminato estrai i dati in Excel e tieni solo la lista di URL ed eventualmente lo Status Code. Ho chiamato il foglio Excel “crawl”.
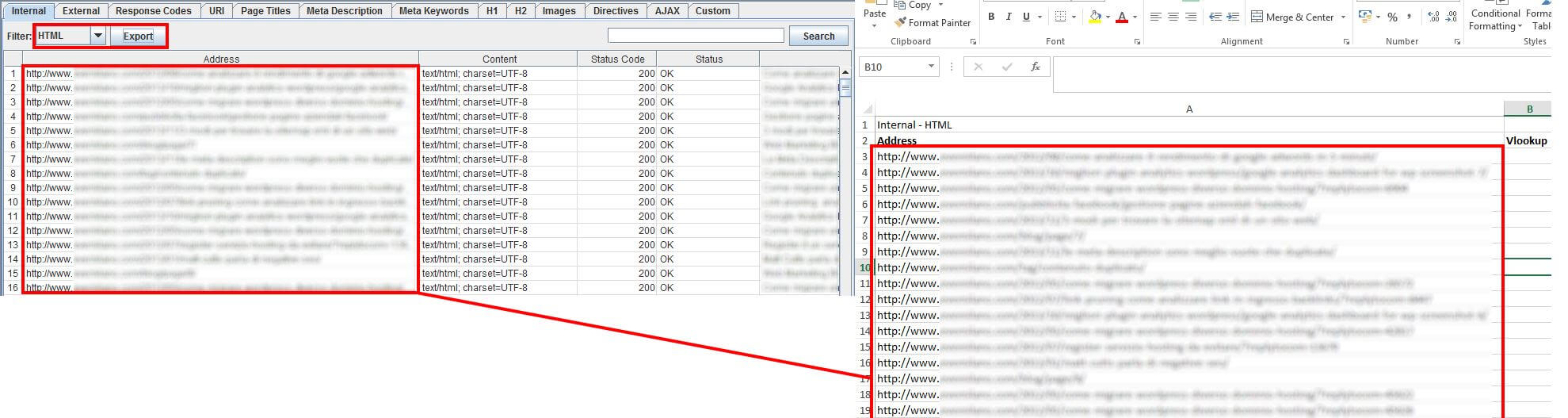
Ora naviga sul sito in esame e salva in locale il file sitemap.xml. Verifica ora il file con Screaming Frog in modalità List. Una volta che il processo di crawling sarà terminato esporta in un altro foglio Excel le colonne URL e Status Code. Ho chiamato il foglio Excel “sitemap”.
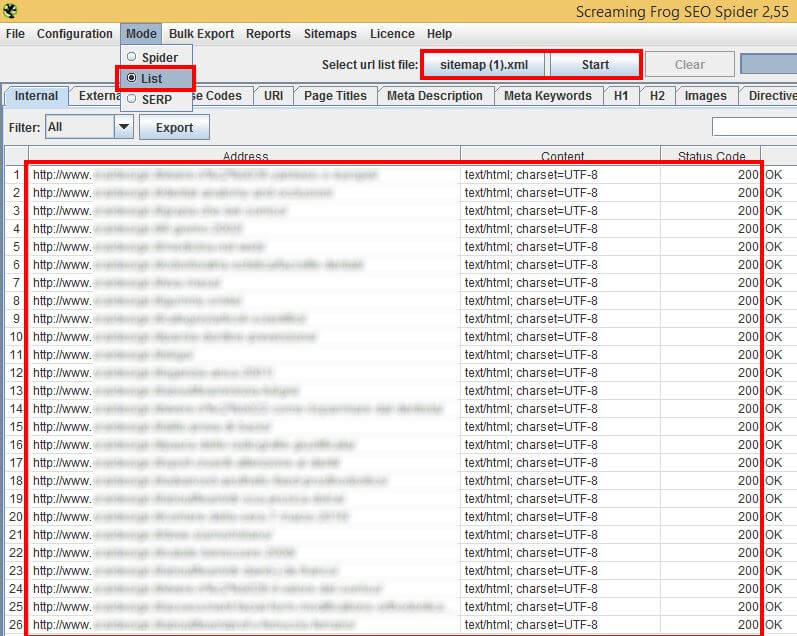
A questo punto dovresti avere due fogli Excel, Crawl con i risultati di Crawling del sito e Sitemap che contiene la verifica della Sitemap.xml. Passa a verificare che tutto sia al posto giusto!
Verifica che la Sitemap.xml contenga tutti gli URL corretti
Andiamo sul foglio Excel sitemap e nella cella a destra di ogni URL inseriamo la funzione VLOOKUP impostando la ricerca sul foglio crawl.
Questa funzione controlla che tutti gli URL elencati in Sitemap siano anche elencati nel file di crawling. In caso affermativo Excel mostrerà l’URL, in caso negativo riceverai l’errore #N/A.
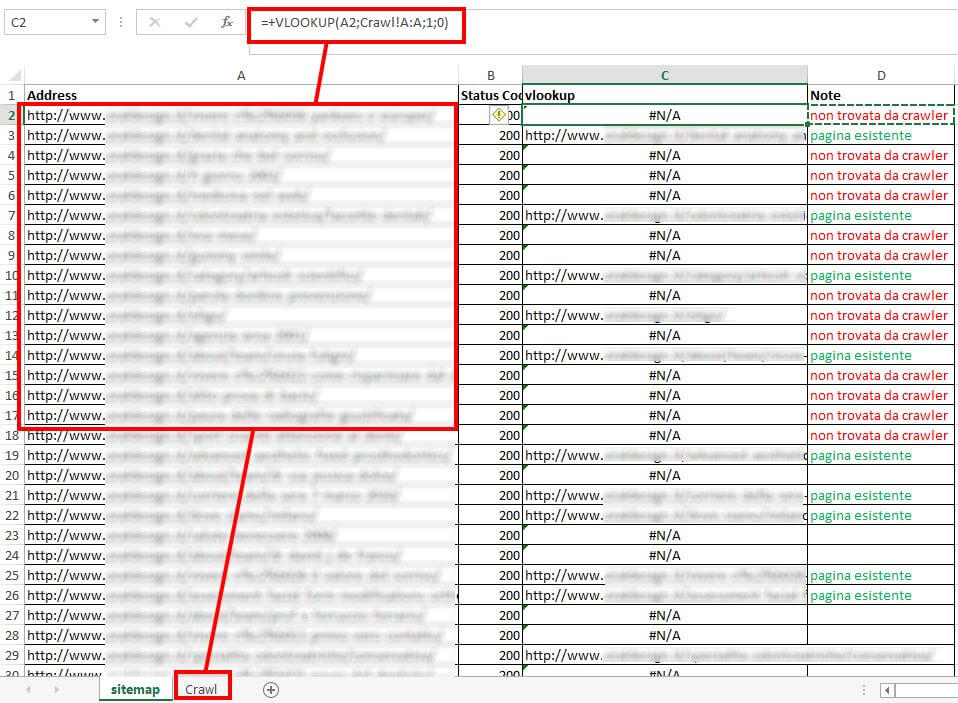
Possibili problemi e risoluzioni:
- in Sitemap.xml sono elencati URL non esistenti con status code 4xx o 5xx. Aggiornare la sitemap rimuovendo o correggendo gli URL errati.
- in Sitemap.xml sono presenti URL con status code 200 ma che il crawler non ha rilevato. Verificare il percorso di navigazione del sito web, il menu e link interni. Tutte le pagine elencate in sitemap devono essere raggiungibili dall’utente finale navigando il sito.
Verifica che tutte le pagine navigabili siano contenute in Sitemap
Andiamo sul foglio Excel crawl e ripetiamo il processo appena svolto ma riferiamoci al foglio sitemap con la funzione VLOOKUP.
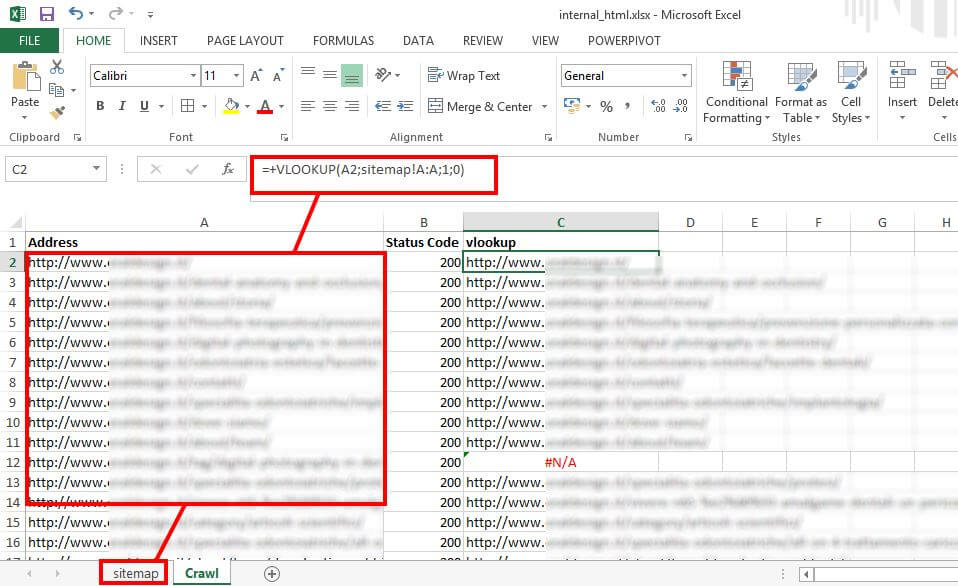
Se la funzione VLOOKUP trova una referenza allora vuol dire che l’URL navigabile è anche in sitemap, se la funzione restituisce un errore #N/A significa che quell’URL non è contemplato in sitemap.xml
Possibili problemi e risoluzioni:
- nel foglio di crawling sono presenti URL con status code 4xx o 5xx. Verificare e correggere i link interni
- nel foglio di crawling sono presenti URL con status code 200 ma non presenti in sitemap. Perchè non sono inseriti? Necessità o dimenticanza? Sono pagine Noindex oppure dovrebbero essere indicizzate? Correggi la sitemap all’occorrenza.
Tu come verifichi la Sitemap.xml? Hai consigli, critiche o aggiunte da proporre? Lascia un messaggio, al resto ci penso io ;)
Autore

Mi chiamo Giovanni Sacheli e dal 2009 aiuto le aziende a farsi trovare online. Sono specializzato in SEO tecnica e PPC, competenze che applico quotidianamente nella mia agenzia, Searcus Swiss Sagl. Mi piace sviluppare strumenti a supporto del mio lavoro, ho creato SEOdata.app e cluster.army e co-scritto il libro SEO Audit Avanzato. Curo maniacalmente questo blog per colleghi e appassionati, dove mi "appunto" quello che imparo. Sono un NERD anni '80, motociclista e orgoglioso papà di due bambini.
Link:
Giovanni Sacheli
SEO Audit Avanzato
Searcus Swiss Sagl
SEOdata.app
cluster.army
Commenti |8
Lascia un commentoBuongiorno Giovanni,
lei ha scritto in questo post che “Tutte le pagine elencate in sitemap devono essere raggiungibili dall’utente finale navigando il sito.”
Vorrei capirne il motivo.
Mi è capitato di lavorare su alcuni siti web in cui alcune pagine (o post) erano presenti in sitemap.xml, ma non erano raggiungibili lato front-end (le pagine erano state effettivamente pubblicate, ma non inserite nel menù).
La sua affermazione immagino riguardi il modo in cui Google potrebbe interpretare un’azione di questo tipo (contenuti creati per i motori di ricerca, non per l’utente finale). Sbaglio?
Grazie mille.
Buongiorno Elena, grazie per aver lasciato il tuo commento :)
In genere tutte le pagine del sito devono poter essere raggiungibili, se una pagina non è raggiungibile dall’utente finale navigando il sito vuol dire che quella pagina non ha link interni.
Una pagina senza link interni è praticamente nascosta ad utenti e bot, vive solo di segnali esterni come backlink, condivisioni, annunci PPC, preferiti del browser, …
Ha senso non linkare pagine usate appunto come landing page PPC (che di solito non brillano per contenuti e tendo a non indicizzare), ma secondo me non avrebbe senso farlo per altre pagine di valore del sito.
Grazie mille per la risposta.
Ciao Giovanni,
approfitto nuovamente della tua disponibilità.
Ricordando un tuo intervendo all’Advanced SEO Tool 2016 (“Discussione su E-commerce e SEO: 20 controlli avanzati con Screaming Frog”) ho controllato un portale che gestisco.
Il sito è composto da alcune pagine statiche e da migliaia di beni in vendita raggiungibili dall’homepage mediante una maschera di ricerca in cui è obbligatorio inserire almeno un filtro.
Scansionando l’intero sito con Screaming Frog trovo solamente 351 pagine HTML (0 noindex). Nella sitemap XML inviata alla GSC, invece, ci sono 54.395 pagine web (di cui 50.937 indicizzate). Il problema è che lo stato di indicizzazione è pari a 336.635 (959%) e il Crawl Budget a 15.314 (44%)!!!
Mi sono agganciata a questo tuo post perché qui scrivevi che “tutte le pagine elencate in sitemap devono essere raggiungibili dall’utente finale navigando il sito”. Le pagine in sitemap, in questo caso, sono tutte “raggiungibili” dal sito. Dico “raggiungibili” tra virgolette perchè, tolte le pagine statiche, tutte le altre pagine inserite in sitemap sono raggiungibili inserendo almeno un filtro nella maschera di ricerca, ma non hanno alcun link interno.
Non so se sono riuscita a farti comprendere la situazione.
In sostanza, vorrei sapere se, secondo te, la percentuale dello stato di indicizzazione è così alta per via delle poche pagine statiche che (giustamente) trovo con Screaming Frog o se, oltre a quello, potrebbero esserci altre problematiche, tipo contenuti duplicati? Se il problema fossero tutte quelle pagine inserite in sitemap prive di link interni, forse potrei risolvere inserendo una mappa HTML del sito all’interno del portale stesso…
Cosa ne pensi?
Grazie mille ancora.
Ciao Elena, grazie per aver lasciato questo commento interessante, credo possa tornare utile anche ad altre persone.
In quanto mi descrivi vedo due macro problematiche: la navigazione e la canonicalizzazione delle risorse (che parolone).
Navigazione: come regola generale per una corretta struttura tutte le pagine del sito web (quindi anche della sitemap.xml) devono poter essere raggiunte dalla homepage cliccando link (tag a), possibilmente non più di 4 volte. Nel tuo caso Screaming Frog trova poche pagine perché probabilmente la maggior parte dei prodotti e/o categorie si raggiungono solo via filtro, oppure usi la navigazione in AJAX/JS e non hai abilitato il render su Screaming Frog. Ricorda che Googlebot non compila form e non esegue azioni che non siano seguire link. Sicuramente rivedrei i link interni in modo da aprire la strada a bot e utenti e magari verificare i livelli di navigazione.
Canonicalizzazione: con questo termine si intende fare pulizia nel database di Google da tutti quegli URL che non hanno contenuto unico (o desiderato). Ad esempio in un sito eCommerce le pagine di listing filtrate con URL parametrizzati generano duplicazioni. L’URL sitoweb.it/scarpe?ordina=prezzo ha una parte del contenuto della pagina sitoweb.it/scarpe, non è una pagina “originale”. Nel tuo caso mi sembra di capire che Google indicizzi più pagine di quelle che dovrebbe, quindi la prima domanda che ti faccio è: il tag rel canonical è implementato? E’ corretto? La seconda domanda è: i parametri sono gestiti in Google Search Console? Potresti escludere dalla scansione in GSC gli URL con filtri di ordinamento o selezione, lascia ovviamente quelli di traduzione e paginazione.
Fammi sapere :) buon lavoro!
Ciao Giovanni,
grazie ancora per la tua disponibilità e per la tua preziosissima risposta.
Avevo segnalato le pagine canoniche tramite rel canonical, ma non ho gestito i parametri nella GSC!!! Provvederò quanto prima. Comunque credo che sia opportuno che ricontrolli di nuovo il tutto.
Grazie di nuovo!
Ci vediamo al WMF! ;-)
Ti consiglio di controllare che il tag rel canonical sia presente nelle pagine con parametri. Nel caso il tag rel canonical non bastasse potresti anche provare a bloccare la scansione di alcuni parametri con un disallow nel robots.txt, oppure alla peggio potresti richiederne la rimozione dalle SERP con un noindex.
Ci vediamo a Rimini!
Grazie ancora! :-)