La duplicazione dei contenuti
Nel caso avessi una singola pagina accessibile da più URL o da pagine diverse con contenuti simili (ad esempio una pagina con una versione sia mobile che desktop), Google li vede come versioni duplicate della stessa pagina. Google sceglierà un URL come versione canonica e lo sottoporrà a scansione, e tutti gli altri URL saranno considerati URL duplicati e scansionati meno spesso.
Se non comunichi esplicitamente a Google quale URL è canonico, Google farà la scelta per te o potrebbe considerarli entrambi di uguale peso, il che potrebbe portare a comportamenti indesiderati.
Il compito di un motore di ricerca è mostrare risultati pertinenti in risposta ad una ricerca utente. Per fare un buon lavoro Google deve avere nel suo indice il maggior numero possibile dei documenti presenti in internet tra cui poter scegliere, indicizzarli tutti non è possibile al momento.
Alla data in cui scrivo, si stima che l’indice di Google contenga un numero di URL minore al 5% di tutte le pagine presenti in Internet, dark web compreso. Alcuni riferimenti con cifre più precise:
- https://search.googleblog.com/2013/03/billions-of-times-day-in-blink-of-eye.html
- https://www.seeker.com/how-much-of-the-internet-is-hidden-1792697912.html
- https://eu.tennessean.com/story/money/tech/2014/05/02/jj-rosen-popular-search-engines-skim-surface/8636081/
- https://www.quora.com/If-Google-has-only-indexed-5-of-the-Internet-and-the-deep-web-only-consists-of-a-couple-thousand-sites-where-is-everything-else
Google non può indicizzare tutti gli URL per svariate ragioni, il più importante è che sono tantissimi. Inoltre, il dark web non segue le logiche di scansione di Googlebot, poi ci sono pagine in aree private di siti web, documenti noindex e così via. Il web è molto vasto.
Per risolvere questo problema Google ha cercato diversi modi per filtrare le pagine che non è necessario indicizzare, vuoi perché sono duplicate oppure perché hanno contenuti poco rilevanti o troppo corti. Giustamente deve dedicare lo spazio di archiviazione, che è tanto ma pur sempre limitato, alle pagine che ha senso indicizzare, quelle che portano valore aggiunto al suo indice.
Le pagine che Google considera duplicate non ottengono visibilità nei risultati di ricerca. Un sito con tante pagine duplicate potrebbe subire una penalizzazione di Google Panda, o comunque non è ben visto dai motori di ricerca.
Un consulente SEO che ottimizza un sito web deve individuare e gestire i contenuti duplicati in modo che Google li canonicizzi verso la pagina che il SEO vuole posizionare. “Canonicalizzare” vuol dire consolidare i valori di indicizzazione ed autorevolezza con un’altra pagina. Quando hai diverse scelte per l’URL di un prodotto, la canonicalizzazione è il processo di sceglierne uno.
Un esempio aiuta. Fai finta di navigare nel sito dove acquisti pneumatici, sei nella pagina con le gomme con le misure che ti servono:
https://sitogomme.it/205-55-15/Ora applichi un filtro per ordinarle per prezzo, nella maggior parte dei CMS viene applicato un parametro URL. L’URL diventerebbe qualcosa tipo:
https://sitogomme.it/205-55-15/?ordinamento=prezzoSe il filtro è un link nel codice HTML della pagina, anche Googlebot lo troverebbe e lo potrebbe scansionare, indicizzerebbe entrambi gli URL, quello con e senza parametro. Sarebbe corretto? No, non è corretto far indicizzare due pagine uguali ad un motore di ricerca (cambia l’ordinamento dei prodotti ma alla fine il listato è sempre quello).
Le pagine duplicate abbassano la qualità globale del sito, cannibalizzano altre pagine e potrebbero rankare al posto di quelle che vorresti. I contenuti duplicati sono un problema da gestire e si gestiscono con il tag rel canonical.
Cos’è un URL canonico?
Un URL canonico è l’URL della pagina che Google ritiene più rappresentativa da un insieme di pagine duplicate sul tuo sito. Ad esempio, se il tuo sito web genera più di un solo URL per la stessa pagina (esempio.it?scarpa=1234 ed esempio.it/scarpa/1234), nel caso tu non comunicassi un URL canonico, Google ne sceglie uno in autonomia.
Nota che le pagine non devono necessariamente essere identiche; piccole modifiche nell’ordinamento o nel filtraggio delle pagine di elenco non rendono la pagina univoca (ad esempio, ordinamento per prezzo o filtro per colore dell’elemento).
L’URL canonico indicato in pagina può puntare anche ad un dominio diverso, utile quando si vuole riportare un contenuto preso al 100% da un altro sito.
Quando Googlebot indicizza un sito, prova a determinare il contenuto principale di ogni pagina. Se Googlebot trova più pagine sullo stesso sito che sembrano uguali, sceglie la pagina che ritiene più completa e utile e la contrassegna come canonica.
La pagina canonica verrà sottoposta a scansione più regolarmente; i duplicati vengono sottoposti a scansione meno frequentemente al fine di ridurre il carico di scansione di Google sul tuo sito.
Google sceglie la pagina canonica in base a una serie di fattori (o segnali), ad esempio se la pagina viene pubblicata tramite http o https; il dominio preferito dichiarato dell’utente; qualità della pagina; presenza dell’URL in una Sitemap; e ogni etichetta “rel = canonica”. Puoi indicare la tua preferenza a Google utilizzando queste tecniche, ma Google può scegliere una pagina diversa come canonica di te, per vari motivi.
Le diverse versioni linguistiche di una singola pagina sono considerate duplicate solo se il contenuto principale è nella stessa lingua (cioè se solo l’intestazione, il piè di pagina e altro testo non critico sono tradotti, ma il corpo rimane lo stesso, quindi le pagine sono considerati duplicati).
Google utilizza le pagine canoniche come fonti principali per valutare contenuti e qualità. Il risultato della Ricerca Google di solito punta alla pagina canonica, a meno che uno dei duplicati sia esplicitamente più adatto per un utente: ad esempio, il risultato della ricerca probabilmente punta alla pagina mobile se l’utente è su un dispositivo mobile, anche se la pagina desktop è contrassegnato come canonico.
Cosa significa “canonicalizzare”
Canonicalizzare una risorsa è un processo eseguito dai motori di ricerca in fase di indicizzazione. Praticamente significa trasmettere alla sua versione canonica tutta l’autorevolezza, associazioni di parole chiave e posizionamenti.
Esempio: la pagina esempio.it/scarpe?ordinamento=prezzo ha canonical verso esempio.it/scarpe.
Questo significa che la pagina con parametro non viene indicizzata e tutti i suoi fattori di posizionamento, backlink compresi, vengono trasmetti alla sua versione canonica senza parametro. Easy peasy!
La funzione del tag rel canonical

Il tag rel canonical serve ad aiutare Google a capire quali pagine indicizzare e quali invece considerare duplicate. Questo tag si inserisce nella sezione <head> della pagina HTML.
<link rel="canonical" href="https://sitogomme.it/205-55-15/" />Una questine molto dibattuta tra i SEO è se inserire il tag rel canonical che punta alla stessa pagina? In teoria andrebbe inserita solo nella pagine da canonicalizzare ma praticamente tutti i CMS inseriscono il tag rel canonical in tutte le pagine, anche quelle che si auto-referenziano nel canonical. Io consiglio di inserire sempre questo tag, in tutte le pagine.
Il problema dei contenuti duplicati è un problema che affligge qualsiasi sito web, dagli editoriali agli eCommerce, WordPress compreso.
Esistono diversi motivi per cui conviene scegliere espressamente una pagina canonica in un insieme di pagine duplicate o simili:
- Specificare l’URL da mostrare nei risultati di ricerca. Gli utenti che arrivano dai motori di ricerca dovrebbero atterrare qui https://sitogomme.it/205-55-15/ e non qui https://sitogomme.it/205-55-15/?ordinamento=prezzo. Una pagina di listing potrebbe generare decine, centinaia o anche migliaia di varianti URL con gli stessi prodotti. Questa situazione per Googlebot è un inferno se non viene gestita correttamente con canonical e “Gestione parametri” in Google Search Console.
- Consolidare i segnali associati ai link per pagine simili o duplicate. Consente ai motori di ricerca di consolidare le informazioni in loro possesso in merito ai singoli URL (ad esempio, link che rimandano a tali URL) in un unico URL preferito. Ciò significa che i link presenti in altri siti che rimandano a http://sitogomme.it/205-55-15/?ordinamento=prezzo vengono consolidati con i link che rimandano a https://sitogomme.it/205-55-15/. I backlink già sono rari, se poi vengono diluiti in altre pagine senza valore si farebbe un danno SEO molto grave.
- Semplificare il monitoraggio delle metriche relative a un singolo URL. La presenza di URL multipli (normali e parametrizzati) nei report di Google Analytics o Google Search Console rende più complicato ricevere metriche consolidate per un contenuto specifico.
- Gestire i contenuti duplicati distribuiti ad altri siti web. Se distribuisci in syndication i contenuti per pubblicarli (o farli pubblicare) su altri domini, ti conviene consolidare il ranking delle pagine con il tuo URL preferito per evitare che le pagine clone vengano indicizzate e posizionate prima delle tue.
- Aiutare Googlebot a non scansionare pagine duplicate. Per ottimizzare la scansione del sito ed il crawl budget, è preferibile che Googlebot sottoponga a scansione pagine nuove (o aggiornate), anziché le versioni filtrate e duplicate di una stessa pagina. Ricordati che il tempo che Googlebot assegna alla scansione del tuo sito non è infinita.
Ora che sei finalmente convinto sull’importanza di questo tag, vediamo alcuni metodi per implementarlo.
La corretta implementazione del tag Rel Canonical
Esistono diverse alternative per specificare la pagina canonica in un insieme di pagine duplicate. A detta di Google l’effetto è lo stesso per tutte le alternative, varia il modo e la difficoltà dell’implementazione tecnica.
Specificare un dominio preferito
Utilizza Search Console per specificare come canonici gli URL su un dominio rispetto alle rispettive controparti su un altro dominio. Ad esempio, sitogomme.it al posto di www.sitogomme.it. Utilizza questo metodo solo quando sono presenti due siti simili che differiscono solo in base al sottodominio. Non utilizzarlo per siti con due protocolli HTTP/HTTPS. Utilizza Search Console per segnalare a Google la versione dell’URL del sito da definire come canonica per il dominio:
https://www.sitogomme.it
https://sitogomme.itSe imposti come dominio preferito https://sitogomme.it, Google tratterà URL o pagine simili su www.sitogomme.it come duplicati di pagine su sitogomme.it.
- Molto facile da implementare, gestire e modificare.
- Utile se disponi di siti identici su domini diversi.
- Funziona solo a livello granulare del dominio e le pagine devono avere percorsi e nomi identici per essere considerate duplicate.
- Consente solo un’unica mappatura da pagina a pagina per pagine con lo stesso percorso.
Tag <link> rel=canonical
Aggiungi nel codice per tutte le pagine duplicate un tag <link> che indirizza gli spider dei motori di ricerca alla pagina canonica. Puoi utilizzare un tag <link> nell’intestazione HTTP della pagina per segnalare quando una pagina è un duplicato di un’altra.
Ipotizza di voler impostare https://sitogomme.it/205-55-15/ come URL canonico, anche se questi contenuti sono accessibili da diversi URL. Definisci questo URL come canonico con i seguenti passaggi:
Contrassegna tutte le pagine duplicate con un elemento link rel=”canonical”. Aggiungi un elemento <link> con l’attributo rel=”canonical” alla sezione <head> delle pagine duplicate, indirizzando a una pagina canonica come la seguente:
<link rel="canonical" href=”https://sitogomme.it/205-55-15/" />Se la pagina canonica è associata a una variante per dispositivi mobili, aggiungi un link rel=”alternate”, indirizzando alla versione per dispositivi mobili della pagina:
Aggiungi eventuali tag hreflang o altri reindirizzamenti appropriati per la pagina.
Utilizza link assoluti
Utilizza percorsi assoluti, anziché percorsi relativi con l’elemento link rel=”canonical”.
Utilizza questa struttura: https://sitogomme.it/205-55-15/
Non questa struttura: /205-55-15/
- Può mappare un numero infinito di pagine duplicate.
- Può aumentare la dimensione della pagina.
- Può complicare la gestione della mappatura su siti di grandi dimensioni o siti in cui gli URL subiscono frequenti modifiche.
- Funziona solo per le pagine HTML, non per i file (ad es., i PDF). In tali circostanze, puoi utilizzare l’intestazione HTTP rel=canonical.
Intestazione HTTP rel=canonical
Invia un’intestazione rel=canonical nella pagina di risposta.
Se puoi configurare il tuo server, puoi utilizzare le intestazioni HTTP rel=”canonical” (al posto dei tag HTML) per definire l’URL canonico per i documenti non HTML, come i file PDF.
Ad esempio, se mostri un file PDF attraverso più URL, puoi restituire un’intestazione HTTP rel=”canonical” come la seguente per gli URL duplicati per indicare a Googlebot quale sia l’URL canonico per il file PDF:
Link: <http://www.example.com/downloads/white-paper.pdf>; rel="canonical"Al momento, Google supporta questo metodo solo per i risultati di Ricerca Google.
Utilizza percorsi assoluti, anziché percorsi relativi con l’elemento link rel=”canonical”. Vale a dire:
Utilizza questa struttura: http://sitogomme.it/downloads/white-paper.pdf
Non questa struttura: /downloads/white-paper.pdf
- Non aumenta la dimensione della pagina.
- Può mappare un numero infinito di pagine duplicate.
- Può complicare la gestione della mappatura su siti di grandi dimensioni o siti in cui gli URL subiscono frequenti modifiche.
Sitemap
Definisci le pagine canoniche in una Sitemap.xml. Scegli un URL canonico per ognuna delle tue pagine e inviali in una Sitemap. Tutte le pagine elencate in una Sitemap vengono suggerite come canoniche, ma sarà Googlebot a decidere quali in base alla somiglianza dei contenuti.
Google non garantisce che considererà gli URL della Sitemap come canonici, ma è comunque un metodo semplice per definire URL canonici per siti di grandi dimensioni. Inoltre, le Sitemap sono utili per segnalare a Google quali pagine reputi più importanti sul tuo sito.
Non includere pagine non canoniche in una Sitemap. Se utilizzi una Sitemap, inserisci solo URL canonici.
- Facile da implementare e gestire, soprattutto su siti di grandi dimensioni.
- Googlebot deve sempre comunque identificare le pagine duplicate per tutte le pagine canoniche dichiarate nella Sitemap.
- Segnalazione meno efficace per Googlebot rispetto alla tecnica di mappatura con rel=canonical.
Reindirizzamento 301
Utilizza i reindirizzamenti 301 per indicare a Googlebot che un URL reindirizzato è una versione migliore dell’URL prestabilito. Adotta questo metodo solo quando rendi obsoleta una pagina duplicata. Un redirect è più veloce ed efficace del tag rel canonical, il problema è che in certi casi non sarebbe corretto redirezionare l’utente.
Utilizza questo metodo se vuoi eliminare pagine duplicate esistenti, ma devi garantire una transizione graduale prima dell’effettivo ritiro di URL obsoleti.
Supponiamo che sia possibile accedere alla tua pagina in diversi modi:
https :// sitogomme.it/home
https :// home.sitogomme.it
https :// www.sitogomme.itScegli uno di questi URL come URL canonico e utilizza i reindirizzamenti 301 per inviare il traffico dagli altri URL all’URL preferito. Un reindirizzamento 301 lato server è il modo migliore per assicurarsi che utenti e motori di ricerca siano indirizzati alla pagina corretta. Il codice di stato 301 indica che una pagina è stata spostata definitivamente in una nuova posizione.
Se utilizzi un servizio di hosting di siti web, cerca la relativa documentazione sulla configurazione dei reindirizzamenti 301.
Chiaramente questo metodo non è applicabile ad URL parametrizzati quindi risolverebbe solo alcuni problemi, non tutti.
Variante AMP
Se una delle varianti è una pagina AMP, è necessario seguire le linee guida delle pagine AMP per segnalare agli spider la pagina canonica e la variante AMP.
Linee guida generali
Quando implementi il tag rel canonical oppure vuoi ottenere gli stessi effetti, stai attento a:
- Non utilizzare il file robots.txt per la canonicalizzazione.
- Non utilizzare lo strumento per la rimozione di URL in Google Search Console per la canonicalizzazione, perché rimuove tutte le versioni di un URL dalla ricerca.
- Non specificare URL diversi come canonici per una stessa pagina (ad esempio, un URL in una Sitemap e un altro URL per la stessa pagina utilizzando link rel=”canonical”).
- Non utilizzare noindex per impedire la selezione di una pagina canonica. Questa istruzione ha lo scopo di escludere la pagina dall’indice, non di gestire la scelta di una pagina canonica.
- Non specificare una pagina canonica utilizzando i tag hreflang. Specifica una pagina canonica in una stessa lingua o nella migliore lingua sostitutiva, qualora non esista una pagina canonica per la stessa lingua.
Dai preferenza al protocollo HTTPS per gli URL canonici
Per le pagine canoniche, Google preferisce le pagine HTTPS alle pagine HTTP equivalenti, ad eccezione dei casi in cui esistano problemi o segnali contrastanti come i seguenti:
- Il certificato SSL della pagina HTTPS non è valido.
- La pagina HTTPS contiene dipendenze non protette (oltre alle immagini).
- La pagina HTTPS reindirizza gli utenti a o tramite una pagina HTTP.
- La pagina HTTPS contiene un link rel=”canonical” alla pagina HTTP.
Anche se Google preferisce per impostazione predefinita le pagine HTTPS alle pagine HTTP, puoi assicurarti che venga applicata tale preferenza implementando redirect e canonical:
- Aggiungi reindirizzamenti dalla pagina HTTP alla pagina HTTPS.
- Aggiungi un link rel=”canonical” che rimanda dalla pagina HTTP alla pagina HTTPS.
Implementa HSTS
Per evitare che Google imposti erroneamente come canonica la pagina HTTP, ti conviene evitare:
- I certificati SSL non validi e i reindirizzamenti da HTTPS a HTTP portano Google a preferire la versione del sito in HTTP. L’implementazione di HSTS non può vincere contro questi due segnali negativi dato che sono molto forti.
- L’inserimento nella Sitemap o in voci hreflang della pagina HTTP anziché della versione HTTPS.
- L’implementazione del certificato SSL/TLS per la variante host sbagliata: ad esempio, sitogomme.it che fornisce il certificato per www.sitogomme.it. Il certificato deve corrispondere all’URL del sito completo oppure essere un certificato con caratteri jolly che sia possibile utilizzare per diversi sottodomini di un dominio.
Rel=canonical e social network
Facebook e Twitter rispettano il tag rel=canonical, questo potrebbe portare a situazioni particolarie. Se condividi un URL su Facebook con un’indicazione canonica altrove, Facebook condividerà i dettagli dall’URL canonico. Infatti, se aggiungi un pulsante “Mi piace” su una pagina che ha un riferimento canonico altrove, mostrerà il conteggio simile per l’URL canonico, non per l’URL corrente. Twitter funziona allo stesso modo.
Chiedi a Google di ignorare i parametri dinamici
Utilizza Gestione parametri per segnalare a Googlebot eventuali parametri da ignorare durante la scansione. Se ignori alcuni parametri puoi ridurre i contenuti duplicati nell’indice di Google e semplificare la scansione del sito. Ad esempio, se indichi di ignorare il parametro sessionid, Googlebot considererà i seguenti due URL duplicati e li canonicalizzerà:
- https://sitogomme.it/205-55-15/?sessionid=273749
- https://sitogomme.it/205-55-15/
Come verificare il tag rel canonical
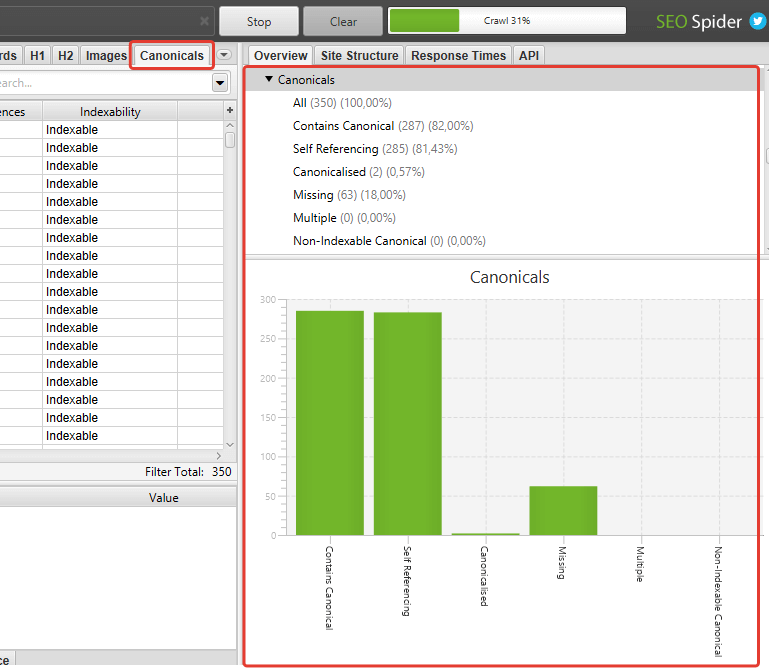
Questo paragrafo non ti serve se hai già letto la guida a Screaming frog, in caso contrario vediamo come verificare la correttezza i tag rel canonical di un sito web.
- Esegui una scansione dei link interni
- Naviga la scheda Canonical
- Analizza con i filtri le possibilità di errore: presenti, mancanti, canonicalizzati
Canonical tag presenti (contains canonical)
Conteggio di tutte le pagine trovate da Screaming Frog che contengono un tag rel canonical. Questo valore è dato dalla somma delle pagine canoniche e delle pagine canonicalizzate.
Canonical tag mancanti (missing)
Conteggio delle pagine che non presentano il tag rel canonical. In teoria non è un errore non avere il tag se l’URL è canonico di se è stesso, come dicevo i CMS tendono ad inserirla comunque. Sarebbe invece un problema avere una pagina duplicata/parametrizzata senza tag rel canonical.
Canonical tag canonicalizzati (canonicalised)
Le pagine canonicalizzate sono pagine che contengono canonical che punta ad altre pagine. I motori di ricerca non dovrebbero indicizzare pagine canonicalizzate. Verifica che tutti gli URL con parametri che non vuoi far indicizzare abbiano canonical con il corretto puntamento.
Spero che questa guida ti sia stata utile. Se vuoi ricevere un avviso quando pubblicherò il prossimo articolo, iscriviti alla newsletter (trovi il link sotto al menu Contatti).
Articoli correlati
Autore

Mi chiamo Giovanni Sacheli e dal 2009 aiuto le aziende a farsi trovare online. Sono specializzato in SEO tecnica e PPC, competenze che applico quotidianamente nella mia agenzia, Searcus Swiss Sagl. Mi piace sviluppare strumenti a supporto del mio lavoro, ho creato SEOdata.app e cluster.army e co-scritto il libro SEO Audit Avanzato. Curo maniacalmente questo blog per colleghi e appassionati, dove mi "appunto" quello che imparo. Sono un NERD anni '80, motociclista e orgoglioso papà di due bambini.
Link:
Giovanni Sacheli
SEO Audit Avanzato
Searcus Swiss Sagl
SEOdata.app
cluster.army
Commenti |18
Lascia un commentoCiao Giovanni, grazie per l’articolo, ho un grosso dubbio però :
Per un sito multilingua , dove ci sono più nazioni con le stesse lingue ; oltre ad impostare il tag hreflang , dovrei impostare il rel canonical
Ad esempio ho questi 2 paesi con la stessa lingua , contenuti identici al 100% :
miosito com/france/femme/
miosito com/belgium/femme/
1) Il rel canonical è uguale per entrambe le pagine :
su miosito com/france/femme/
su miosito com/belgium/femme/
Oppure
2) Andrebbe messo il canonical verso la Francia , essendo la nazione Principale dove voglio dare maggiore visibilità e la lingua è quella ufficiale , del tipo :
su entrambe le pagine ?
Nel caso 1) Google come fa a capire e a indicizzare correttamente ?
Grazie mille
Ciao Marco grazie del commento.
Opzione 1.
Il tag rel canonical è corretto che punti a ciascuna delle due pagine, in quanto hanno finalità differenti (il targeting geografico). Sarà il tag hreflang a far capire a Google che non sono due pagine duplicate ma destinatarie di pubblico differente. In questa guida c’è un link alla guida del tag hreflang se ti interessa approfondire.
PS: una cosa che mi fa storcere il naso sono le cartelle /france/ e /belgium/. È buona norma usare le sigle ISO 639-1: two-letter codes: /fr/ e /be/ dato che vengono comprese senza fraintendimenti dai motori di ricerca, sono appunto un segnale ‘standard’ – https://en.wikipedia.org/wiki/List_of_ISO_639-1_codes. Potrebbe interessarti questa guida – https://www.evemilano.com/gestire-lingue/.
Buongiorno qui c’è un errore. Il metatag hreflang non corregge i contenuti duplicati.
Ciao “Roger”, grazie per il tuo commento. Non direi che è un errore quanto indicato nella guida, la funzione di tutela sulle duplicazioni è contestualizzato su contenuti identici con target differenti, ed in tal senso l’hreflang aiuta.
Se hai lo stesso contenuto in inglese su URL diversi rivolti a Regno Unito, Stati Uniti e Australia, la differenza su queste pagine potrebbe essere piccola come una variazione di prezzi e valuta. Senza hreflang, Google potrebbe non capire cosa stai cercando di fare e potrebbe vedere qulle pagine come contenuto duplicato. Con hreflang, chiarisci al motore di ricerca che è (quasi) lo stesso contenuto, ottimizzato per persone diverse.
Per maggiori info ti rimando alla guida di Google – https://support.google.com/webmasters/answer/189077?hl=it
Chiaro che l’hreflang non risolve i problemi generici di un contenuto duplicato, in questa guida parlo di siti che hanno come target paesi differenti con una lingua in comune.
Ogni cosa che si legge online va contestualizzata ;)
Saluti.
Buongiorno,
sto effettuando un controllo con screaming frog di un sito. Sono state scansionate sia le url in www che senza www. Tuttavia le pagine senza www hanno il reindirizzamenti 301 a quelle con www e queste ultime hanno il canonical.
Se faccio site:www.nomesito.com risulta indicizzata solo la versione www.
Come mai? Cosa occorre fare in questi casi?
Grazie
E complimenti per le sue guide!
Ciao Marialaura, la situazione che mi descrivi è corretta.
L’unico errore da correggere sono i link interni che puntano alla versione senza www. In questo modo il crawler troverà solo URL con www.
Il fatto che il sito senza www redirezioni a quella con www comporta che solo la versione www venga, giustamente, indicizzata.
Il tag rel canonical poi conferma ai motori di ricerca che la pagina canonica è con www.
Cosa non ti torna?
Buongiorno Giovanni,
complimenti per questa guida (e per tutte le altre!).
Vorrei farti una domanda in merito alle pagine non canoniche.
Come vengono trattate da Google? Vengono scansionate ma non indicizzate? Vengono mostrate in Serp per la query corrispondente?
Mi spiego meglio con un esempio.
Nel caso in cui in un ecommerce con tante t-shirt modello xyz venga impostato il tag rel canonical sulla t-shirt gialla modello xyz, cosa succede quando un utente cerca t-shirt verde modello xyz?
Google mostra comunque la pagina canonica o quella che soddisfa meglio la query?
Ti ringrazio in anticipo per l’eventuale risposta.
Ciao Giorgio grazie per il commento.
Le pagine canonicalizzate vengono scansionate ma NON vengono indicizzate e quindi NON appaiono in SERP. I segnali delle pagine canonicalizzate, come ad esempio i backlink, vengono trasferiti alla pagina canonica.
Nel tuo esempio quindi vengono associati alla pagina della tshirt gialla i segnali di autorevolezza e non appariranno nei risultati di Google.
Spero di averti chiarito i dubbi.
A presto!
Grazie mille!
Sei stato chiarissimo e gentilissimo.
Ciao Giovanni,
grazie per questa guida.
Avrei una domanda: per gestire ad esempio i filtri di un ecommerce si possono inserire sia il canonical che il noindex nella stessa pagina? E’ sbagliato? Cioè è solo una ripetizione oppure ci sono controinicazioni e quindi è preferibile inserire solo il canonical?
Grazie in anticipo
Ciao Francesco e grazie per la domanda. Noindex e canonical danno due segnali contrapposti ai motori di ricerca, quindi non andrebbero usati assieme.
Se la pagina filtrata mira parole chiave utili, ha contenuti unici e meta dati specifici per il filtro, allora potrebbe avere senso renderla canonica e farla indicizzare.
Altrimenti dovrà canonicalizzare alla pagina senza filtri.
Buongiorno Giovanni, grazie mille per la risposta. Potrebbe spiegare meglio in che senso il noindex e il canonical danno 2 segnali contrapposti? Questo aspetto francamente non mi è chiarissimo. Grazie di nuovo!
Ciao Francesco, in realtà il concetto è molto semplice.
Il tag rel canonical inserito in una pagina dice a Google: “tutti i segnali di autorevolezza e la stessa indicizzazione di questo URL, devono essere assegnati 1) all’URL stesso se il canonical è self referencing, oppure 2) ad un altro URL se il canonical punta un altra pagina (è quindi una risorsa canonicalizzata).”
Il NOINDEX dice a Google: non indicizzare questo contenuto. Il NOINDEX non “migra” i segnali di ranking verso altri URL, un URL NOINDEX viene totalmente escluso dall’indicizzazione.
Quindi canonical dice INCLUDIMI e NOINDEX dice ESCLUDIMI. Non possono andare assieme.
Ciao Giovanni,
grazie mille, chiarissimo e gentilissimo. Adesso ho capito.
Quindi per i filtri utilizzerò solo il canonical, mentre per altre pagine che non hanno segnali di ranking, come ad esempio il carrello o la pagina di login, userò solo il noindex. E poi quando saranno deindicizzate, le bloccherò direttamente dal robots.
Grazie ancora!
Ottima strategia Francesco, tranne a mio parere l’ultima parte: non usare il disallow altrimenti Googlebot poi non vede più il noindex.
Il disallow del robots.txt non serve a gestire l’indicizzazione.
Ciao Giovanni,
Si, certo, grazie mille per la precisazione. A quel punto prima toglierei il noindex e subito dopo bloccherei le pagine da robots.txt. Grazie del tuo supporto, sei stato chiarissimo e velocissimo nelle risposte. E grazie mille per tutte le tue guide, che sono semplicemente fantastiche.
Buongiorno Giovanni, c’è una cosa che non ho capito.
Devo comunque settare i parametri SEO come keywords, meta title e meta description per una pagina che scelgo comunque di canonicalizzare?
Esempio: ho un sito che sarà pubblicato in due versioni: istituzionale e commerciale, con due domini diversi. Pagine come la storia dell’azienda saranno identiche per entrambi, quindi io rimanderei al sito istituzionale.
Da quel che leggo sembrerebbe di no, alla fine prende quelli della pagina diciamo “principale”. Oppure è sempre meglio settarle?
Ti ringrazio in anticipo per la risposta (che sarebbe un pochino urgente perché ci sto lavorando ora ora…XD)
Ciao Jessica, grazie per la domanda. Tag title e description sono tag che si curano sulle le pagine indicizzabili. Se una pagina è noindex o viene canonicalizzata, non ha utilità lavorare su quei meta. A presto!