Per anni la gestione dei crawler si è ridotta a una scelta binaria: indicizzare o non indicizzare, index o noindex. Quel modello oggi è insufficiente. Il tuo sito viene visitato da una dozzina di crawler AI distinti: alcuni addestrano i foundation model, altri recuperano pagine in tempo reale per rispondere a un utente, altri ancora costruiscono l’indice che alimenta le citazioni dentro ChatGPT, Perplexity o le AI Overviews di Google. Trattarli tutti allo stesso modo è un errore costoso in entrambe le direzioni: se li blocchi in massa rinunci alla visibilità nell’economia delle citazioni; se li lasci passare senza criterio cedi i tuoi contenuti al training senza alcun ritorno.
I numeri spiegano la posta in gioco. Nel 2026 oltre il 58% delle ricerche Google si chiude senza un click e le AI Overviews compaiono su circa metà delle query informative; in AI Mode la quota di sessioni zero-click sfiora il 93%. Eppure le pagine citate dentro una risposta AI registrano in media un +35% di click rispetto alla stessa posizione organica priva di citazione. La leva non è più solo il ranking: è il diritto di essere letti e citati dai sistemi generativi.
Questa guida è un riferimento operativo. Trovi la tassonomia dei crawler AI con la tabella aggiornata degli user-agent, un framework per decidere cosa concedere a chi, il controllo selettivo via robots.txt, l’enforcement lato server per i bot che lo ignorano e il monitoraggio via log. Do per scontato che tu padroneggi robots.txt, meta robots, gli status code HTTP e l’analisi dei log.
Lo scenario 2026: perché non basta più decidere se indicizzare
Il punto di rottura è che l’accesso al tuo sito non equivale più a un singolo comportamento. Lo stesso URL può essere richiesto da un bot che lo userà per addestrare un modello che non ti citerà mai, e da un altro bot che lo recupererà per rispondere a un utente citando e linkando la tua pagina. Bloccare l’uno o l’altro produce conseguenze opposte sul tuo traffico futuro. La domanda corretta non è più «voglio essere indicizzato?», ma «a quale tipo di accesso AI concedo il mio contenuto, e cosa ottengo in cambio?».
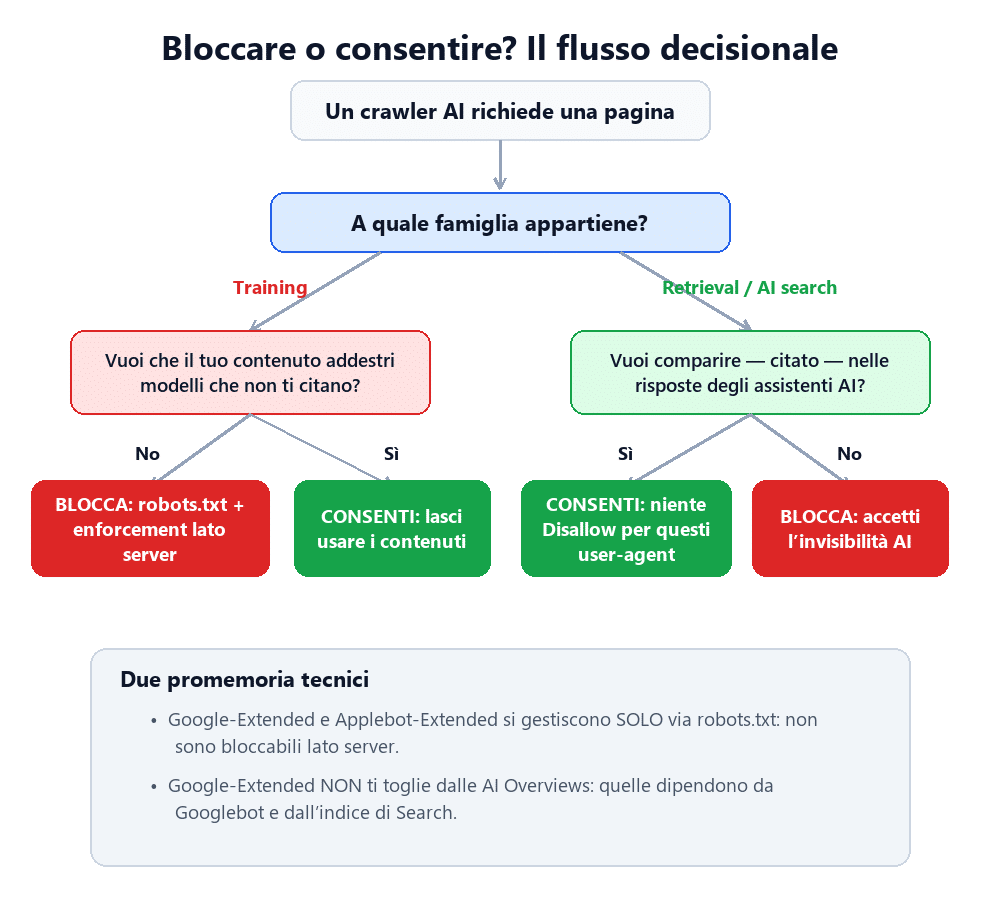
C’è poi un equivoco tecnico diffuso che vale la pena sciogliere subito, perché orienta tutte le decisioni a valle: le AI Overviews e AI Mode di Google sono alimentate dall’indice di Google Search, quindi da Googlebot, non da Google-Extended. Disabilitare Google-Extended nel robots.txt impedisce l’uso dei tuoi contenuti per il training e il grounding di Gemini e Vertex AI, ma non ti rimuove dalle AI Overviews. Per uscire dalle AI Overviews dovresti uscire da Google Search, il che nella quasi totalità dei casi è autolesionistico. Tenere distinti questi due piani — training del modello vs. ranking e citazione in SERP — è il primo passo per non prendere decisioni controproducenti.
Le tre famiglie di crawler AI
Ogni crawler AI ricade in una di tre famiglie funzionali. La famiglia — non il brand — determina cosa perdi o guadagni bloccandolo.
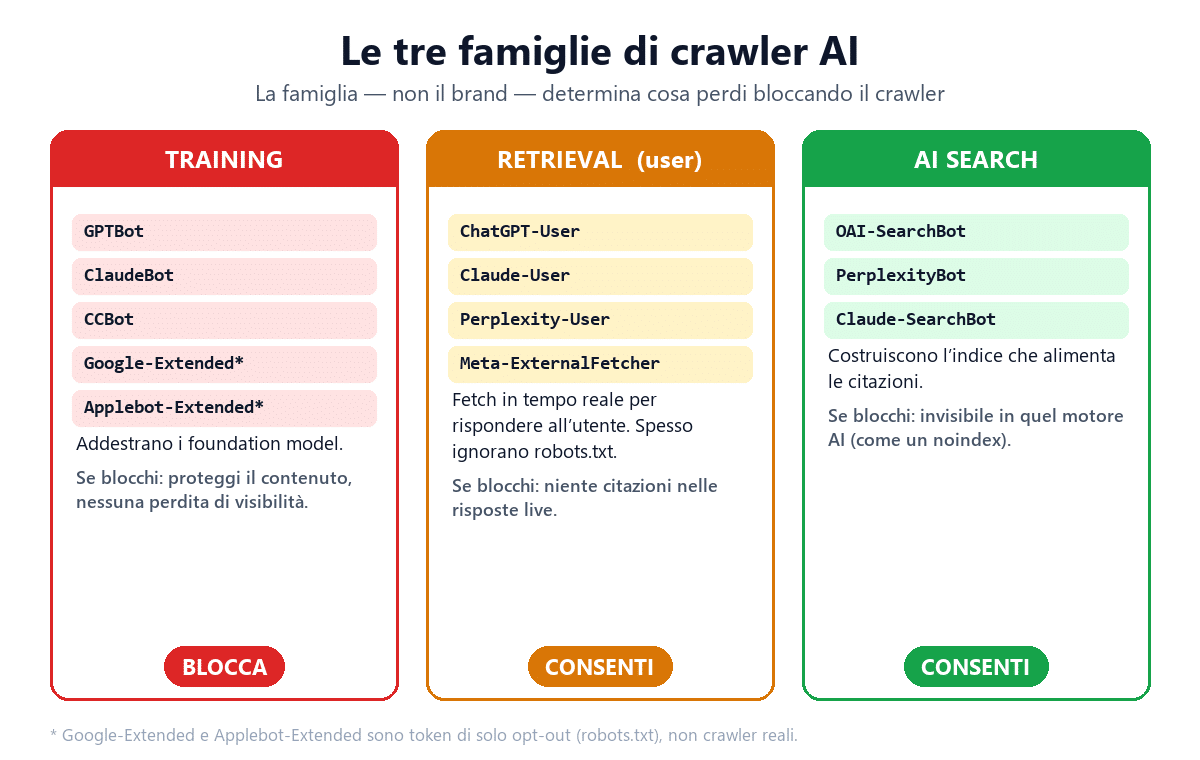
- Training crawler. Scaricano contenuti per costruire o aggiornare i dataset di addestramento dei foundation model. Il contenuto entra nei pesi del modello, ma non c’è alcun link o citazione di ritorno. Bloccarli protegge il contenuto dal training senza intaccare la tua visibilità nelle risposte live. Esempi:
GPTBot,ClaudeBot,CCBot,Google-ExtendedeApplebot-Extended(come token di opt-out),Meta-ExternalAgent,Bytespider. - Retrieval / live-fetch (user-triggered). Recuperano una pagina in tempo reale quando un utente pone una domanda all’assistente, per costruire la risposta. Tendono a citare e linkare la fonte, e poiché agiscono per conto di un utente spesso ignorano il robots.txt. Bloccarli significa non poter comparire in quelle risposte. Esempi:
ChatGPT-User,Claude-User,Perplexity-User,Meta-ExternalFetcher. - AI search indexing. Costruiscono l’indice persistente che alimenta la funzione di ricerca dell’assistente e le sue citazioni. È la famiglia da cui dipende la tua presenza nei risultati citati di ChatGPT Search o Perplexity. Bloccarli equivale a un
noindexper quel motore AI. Esempi:OAI-SearchBot,PerplexityBot,Claude-SearchBot.
La regola operativa che ne deriva è netta: se vuoi visibilità nelle risposte AI mantenendo il controllo sul training, blocca la famiglia 1 e lascia accedere le famiglie 2 e 3. È esattamente la configurazione che la maggior parte degli editori e dei siti aziendali dovrebbe adottare come default, e che vedremo come implementare.
User-agent dei crawler AI: la tabella di riferimento 2026
Token verificati sulle documentazioni ufficiali degli operatori (OpenAI, Anthropic, Google, Perplexity, Apple, Meta). La colonna «Rispetta robots.txt» riporta il comportamento dichiarato dall’operatore: i fetcher user-triggered, per definizione, spesso non lo onorano.
| User-agent | Operatore | Famiglia | Cosa fa | robots.txt |
|---|---|---|---|---|
GPTBot | OpenAI | Training | Addestra i foundation model GPT | Sì |
OAI-SearchBot | OpenAI | AI search | Indicizza i siti per la ricerca in ChatGPT (citazioni) | Sì |
ChatGPT-User | OpenAI | Retrieval (user) | Fetch in tempo reale su azione dell’utente / GPT Actions | No |
ClaudeBot | Anthropic | Training | Raccoglie contenuti per addestrare i modelli Claude | Sì |
Claude-SearchBot | Anthropic | AI search | Migliora la qualità dei risultati di ricerca | Sì |
Claude-User | Anthropic | Retrieval (user) | Accede ai siti quando l’utente interroga Claude | Sì |
Google-Extended | Training (token) | Opt-out dall’uso per training e grounding di Gemini/Vertex AI. Non è un crawler e non incide su Search | Sì | |
Google-CloudVertexBot | Retrieval/agent | Crawla i siti per i Vertex AI Agents su richiesta del proprietario | Sì | |
PerplexityBot | Perplexity | AI search | Indicizza e linka i siti nei risultati Perplexity; non usato per il training | Sì |
Perplexity-User | Perplexity | Retrieval (user) | Fetch su richiesta dell’utente | No (di norma) |
Applebot-Extended | Apple | Training (token) | Opt-out dall’uso per il training dei modelli Apple. Non crawla: governa l’uso dei dati già raccolti da Applebot | Sì |
Meta-ExternalAgent | Meta | Training/index | Training dei modelli e indicizzazione diretta dei contenuti | Sì |
Meta-ExternalFetcher | Meta | Retrieval (user) | Recupera singoli link su richiesta dell’utente | No (può ignorarlo) |
CCBot | Common Crawl | Training (dataset) | Costruisce il dataset pubblico usato da molti LLM come fonte di training | Sì |
Amazonbot | Amazon | Training/AI | Alimenta Alexa e i servizi AI di Amazon | Sì |
Bytespider | ByteDance | Training | Raccoglie dati per i modelli di ByteDance/TikTok | Segnalato per violazioni |
Nota. Esistono token aggiuntivi e legacy che puoi ancora trovare nei log: OAI-AdsBot (validazione delle landing page pubblicitarie in ChatGPT), gli storici anthropic-ai e Claude-Web di Anthropic, oltre a MistralAI-User, cohere-ai, DuckAssistBot, Diffbot e ImagesiftBot. Verifica periodicamente le pagine ufficiali degli operatori, perché versioni dei token e comportamenti cambiano più volte l’anno: la tabella sopra è una fotografia, non un dato immutabile.
Quali crawler bloccare: un framework decisionale
Non esiste una configurazione universale: la scelta dipende dal modello di business e dal valore marginale del singolo contenuto. Il criterio guida è sempre lo stesso: separa ciò che ti porta visibilità (retrieval e AI search) da ciò che consuma il tuo contenuto senza ritorno (training), e calibra in base a quanto è strategico per te essere citato nelle risposte AI. Sul dilemma di fondo — se convenga aprire o meno il sito ai chatbot — il punto di partenza nel 2026 è che la visibilità nelle risposte AI vale di norma più della chiusura difensiva.
- Publisher / editori e blog informativi. La citazione è ossigeno: la visibilità nelle risposte AI è oggi un canale di acquisizione, non un nemico. Configurazione consigliata: bloccare i training crawler, lasciare aperti retrieval e AI search. È il default ragionevole per la maggior parte dei siti a contenuto.
- E-commerce. Schede prodotto, disponibilità e prezzi hanno valore quando vengono mostrati e linkati: tenere aperti retrieval e AI search è quasi sempre vantaggioso. Il training è ininfluente sulle conversioni, quindi bloccarlo non costa nulla in termini di vendite.
- Siti con contenuti premium o proprietari (ricerca, dati, paywall). Qui ha senso un approccio più restrittivo: blocca il training su tutto e valuta caso per caso il retrieval, eventualmente esponendo agli assistenti solo le sezioni gratuite e proteggendo lato server l’area riservata.
- Siti aziendali e brand. Essere la fonte citata quando un utente chiede informazioni sul tuo settore è puro brand-building. Tieni aperte le famiglie 2 e 3; blocca il training solo se hai una posizione esplicita sul tema copyright.
Qualunque sia la scelta, vale un principio di metodo: decidi a livello di famiglia e di sezione, non di singolo bot. Mantenere regole per-bot scollegate dalla logica funzionale rende il robots.txt ingestibile e introduce errori a ogni nuovo token che compare.
Controllo via robots.txt: sintassi selettiva
Il robots.txt è il primo livello di controllo e l’unico canale disponibile per i token di solo opt-out come Google-Extended e Applebot-Extended, che non emettono richieste bloccabili altrove. La configurazione default consigliata — blocco del training, apertura di retrieval e AI search — si scrive così:
# --- Famiglia 1: TRAINING → bloccati ---
User-agent: GPTBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: meta-externalagent
Disallow: /
User-agent: Bytespider
Disallow: /
# --- Famiglie 2 e 3: RETRIEVAL e AI SEARCH → consentiti ---
User-agent: OAI-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: Claude-SearchBot
Allow: /Due aspetti tecnici da non sbagliare, perché sono la causa più frequente di robots.txt che «non funzionano»:
- Matching del gruppo più specifico, non cumulativo. Ogni crawler obbedisce solo al gruppo
User-agentche corrisponde in modo più specifico al proprio token, ignorando tutti gli altri, incluso il catch-allUser-agent: *. Se definisci un gruppo perGPTBot, quel bot leggerà esclusivamente quelle righe: eventualiDisallowgenerici nel gruppo*non si applicheranno. Per questo i bot AI vanno gestiti con gruppi dedicati e completi. - I gruppi consentiti sono ridondanti ma espliciti. Un bot non menzionato è implicitamente autorizzato; le righe
Allow: /per OAI-SearchBot e simili non sono tecnicamente necessarie, ma documentano l’intenzione e proteggono da un eventuale catch-all restrittivo introdotto in seguito.
Il limite strutturale del robots.txt è che non è vincolante. È un’istruzione che i bot conformi onorano per convenzione, non un meccanismo di enforcement. I fetcher user-triggered lo ignorano per progettazione e i crawler malevoli o aggressivi — Bytespider è il caso di scuola — possono ignorarlo o mascherare lo user-agent. Per tutto ciò che vuoi bloccare davvero, il robots.txt va affiancato da un controllo lato server.
Enforcement lato server per i bot che ignorano robots.txt
Il blocco lato server agisce sulla richiesta HTTP a prescindere dalla buona volontà del bot. Una precisazione che evita lavoro inutile: non puoi bloccare lato server i token di solo opt-out (Google-Extended, Applebot-Extended), perché non sono crawler e non inviano mai una richiesta con quello user-agent — per loro l’unico canale resta il robots.txt. Lato server agisci sui bot che effettivamente emettono richieste: GPTBot, CCBot, ClaudeBot, Bytespider, meta-externalagent, Amazonbot e così via.
Nginx
Una direttiva map nel contesto http centralizza la lista degli user-agent da rifiutare e li mappa su una variabile, usata poi nel server per restituire un 403. È più pulito e performante di una catena di if:
# /etc/nginx/conf.d/ai-bots.conf — contesto http
map $http_user_agent $ai_bot_block {
default 0;
"~*\bGPTBot\b" 1;
"~*\bCCBot\b" 1;
"~*\bClaudeBot\b" 1;
"~*\bBytespider\b" 1;
"~*\bmeta-externalagent\b" 1;
"~*\bAmazonbot\b" 1;
}
server {
# ...
# return dentro if è uno degli usi sicuri di "if" in nginx
if ($ai_bot_block) {
return 403;
}
}Apache (.htaccess)
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} (GPTBot|CCBot|ClaudeBot|Bytespider|meta-externalagent|Amazonbot) [NC]
RewriteRule ^ - [F,L]Il flag [F] restituisce un 403 Forbidden, [NC] rende il match case-insensitive e [L] ferma l’elaborazione delle regole. Su siti ad alto traffico, valuta di spostare questo controllo a livello di virtual host invece che in .htaccess, che viene riletto a ogni richiesta.
fail2ban per i bot aggressivi e camuffati
Il blocco per user-agent non basta contro i bot che falsificano l’header o saturano il server. fail2ban intercetta i pattern sospetti nei log e banna l’IP a livello di firewall. Un filtro che bersaglia gli user-agent dichiarati:
# /etc/fail2ban/filter.d/ai-bots.conf
[Definition]
failregex = ^<HOST> .*"(GET|POST).*HTTP.*"(GPTBot|CCBot|Bytespider|meta-externalagent)
ignoreregex =# /etc/fail2ban/jail.local
[ai-bots]
enabled = true
port = http,https
filter = ai-bots
logpath = /var/log/nginx/access.log
maxretry = 2
findtime = 300
bantime = 86400Per i bot che non falsificano l’identità e pubblicano i propri range IP — OpenAI espone i suoi su openai.com/gptbot.json e openai.com/searchbot.json — il blocco più robusto è per IP o per ASN, perché non è aggirabile cambiando lo user-agent.
Verificare e monitorare gli accessi dei crawler
Una policy di gestione dei crawler senza misurazione è cieca: non sai chi ti visita, se le tue regole sono rispettate, né cosa ti costa in visibilità. Tre attività di controllo, dalla più semplice alla più strategica.
- Censire chi scansiona. Un’aggregazione degli user-agent AI sui log di accesso ti dice subito volumi e frequenza di ogni bot:
awk -F'"' '{print $6}' access.log \
| grep -iE 'GPTBot|OAI-SearchBot|ChatGPT-User|ClaudeBot|Claude|CCBot|PerplexityBot|Perplexity-User|Bytespider|meta-external|Amazonbot' \
| sort | uniq -c | sort -rn- Verificare l’identità dei bot legittimi. Prima di fidarti di uno user-agent, conferma che provenga davvero dall’operatore: reverse DNS più forward-confirm per i bot che lo supportano, oppure verifica dell’IP contro i range ufficiali pubblicati. La metodologia è la stessa che applichi a Googlebot e che ho descritto nella guida su come verificare Googlebot e gli spider dei motori di ricerca. Per l’analisi forense dei log e l’isolamento del traffico anomalo, vale l’approccio Python + Regex della guida su analisi log e negative SEO.
- Misurare il ritorno. Il blocco o l’apertura vanno valutati sull’impatto reale: quantifica il traffico referral che arriva dagli assistenti AI e incrocialo con le tue scelte di accesso. La metodologia di tracciamento, con il filtro regex da applicare in GA4, è nella guida su come visualizzare il traffico referral dalle piattaforme AI. È questo dato — non un principio astratto — a dirti se stai lasciando soldi sul tavolo.
Tieni d’occhio anche il crawl budget: i bot AI più aggressivi possono generare volumi di richieste paragonabili a quelli dei motori tradizionali, con un impatto concreto su carico server e costi di banda che, da solo, può giustificare un blocco selettivo.
Manipolare le risposte AI è spam: la policy Google 2026
Gestire l’accesso dei crawler è metà del lavoro; l’altra metà è non superare il confine tra ottimizzazione e manipolazione. Nel maggio 2026 Google ha aggiornato le proprie spam policy nominando per la prima volta in modo esplicito la manipolazione delle risposte generative: tentare di alterare artificiosamente ciò che le funzioni AI di Search restituiscono è spam, soggetto ad azioni manuali e demotion algoritmica, esattamente come lo è la manipolazione del ranking organico.
Le implicazioni pratiche per chi lavora sulla visibilità AI:
- Niente acquisto di citazioni. Comprare o ingegnerizzare artificialmente menzioni e citazioni nelle risposte AI rientra nelle pratiche manipolative sanzionabili.
- Niente contenuto-esca per gli assistenti. Testo nascosto, prompt injection nei contenuti o pagine costruite per pilotare le risposte degli LLM sono manipolazione, non SEO.
- La leva legittima resta l’Information Gain. I core update del 2026 premiano i contenuti che aggiungono conoscenza realmente nuova: dati proprietari, test in prima persona, case study con risultati misurabili. È lo stesso requisito di Experience ed Expertise che governa il ranking organico, ed è il modo sostenibile per essere citati dagli assistenti.
In altri termini: apri l’accesso ai bot giusti e poi meriti la citazione con contenuto originale, non la forzi. La scorciatoia manipolativa oggi è esplicitamente vietata e tracciata.
Checklist operativa per gestire i crawler AI
- Classifica ogni crawler AI per famiglia (training / retrieval / AI search), non per brand.
- Definisci il default in base al modello di business: per la maggior parte dei siti, blocco del training, apertura di retrieval e AI search.
- Implementa il robots.txt con gruppi dedicati e completi per ogni bot AI, ricordando il matching non cumulativo.
- Gestisci
Google-ExtendedeApplebot-Extendedsolo via robots.txt: non sono bloccabili lato server. - Ricorda che
Google-Extendednon ti rimuove dalle AI Overviews: quelle dipendono da Googlebot. - Affianca al robots.txt un enforcement lato server (nginx/Apache) per i bot che lo ignorano, e fail2ban per quelli aggressivi o camuffati.
- Verifica l’identità dei bot legittimi via reverse DNS o range IP ufficiali prima di consentire o bloccare per user-agent.
- Monitora volumi nei log e misura il referral AI per validare le tue scelte sui dati, non sulle ipotesi.
- Guadagna le citazioni con Information Gain: niente manipolazione, vietata dalle spam policy 2026.
- Rivedi la configurazione ogni trimestre: i token e i comportamenti dei crawler AI cambiano di continuo.
La gestione dei crawler AI non è più una riga di robots.txt copiata da un forum: è una decisione strategica che bilancia protezione del contenuto e visibilità nell’ecosistema generativo. Imposta il default corretto per il tuo sito, verificalo lato server, misuralo nei log e aggiornalo con la stessa disciplina con cui gestisci l’indicizzazione su Google.
Articoli correlati
Autore

Mi chiamo Giovanni Sacheli e dal 2009 aiuto le aziende a farsi trovare online. Sono specializzato in SEO tecnica e PPC, competenze che applico quotidianamente nella mia agenzia, Searcus Swiss Sagl. Mi piace sviluppare strumenti a supporto del mio lavoro, ho creato SEOdata.app e cluster.army e co-scritto il libro SEO Audit Avanzato. Curo maniacalmente questo blog per colleghi e appassionati, dove mi "appunto" quello che imparo. Sono un NERD anni '80, motociclista e orgoglioso papà di due bambini.
Link:
Giovanni Sacheli
SEO Audit Avanzato
Searcus Swiss Sagl
SEOdata.app
cluster.army