Introduzione
Vogliamo tutti che Google visiti il nostro sito il più spesso possibile. In questo modo, Google indicizza i contenuti nuovi e può condividerli immediatamente con chiunque effettui ricerche online. Google utilizza un crawler chiamato “Googlebot” che esegue la scansione di milioni di pagine web contemporaneamente e indicizza il loro contenuto nei database di Google.
Più Googlebot visita il tuo sito, più velocemente gli aggiornamenti dei contenuti verranno visualizzati nei risultati di ricerca di Google. Di conseguenza, è della massima importanza consentire a Googlebot di eseguire la scansione del tuo sito web senza bloccarlo o disturbarlo. In effetti, spesso si tende a dare a Googlebot un trattamento da vero VIP.
Il problema? Gli hacker che si mascherano da Googlebot per causare danni. In un recente studio su 1000 siti web si è scoperto che il 16,3% dei siti subisce attacchi di tipo Googlebot Impersonation di qualche tipo, ovvero attacchi fatti con user-agent Googlebot ma non provenienti dal reale Googlebot. Questi attacchi tendono ad inserire spam nei commenti oppure fanno scraping dei contenuti
Per questa e diverse altre ragioni potresti voler identificare Googlebot, un altro esempio potrebbe essere per fornirgli una versione pre-renderizzata del tuo sito basato su JavaScript. Per farlo devi essere in grado di rilevare se una richiesta è fatta da un utente o un bot, e soprattutto devi sapere se il bot si sta presentando con il suo vero nome oppure se ti sta ingannando.
Cosa sono i crawler o spider o bot?
Se stai cercando un modo per rilevare e verificare i crawler, probabilmente sai già cosa sono. Per chi non lo sapesse, i crawler (detti talvolta spider o bot) sono programmi per computer che eseguono la scansione del web. In altre parole, visitano le pagine web, trovano collegamenti a ulteriori pagine e visitano anche loro. Spesso questi spider mappano ed indicizzano i contenuti che trovano per poterli usare successivamente, oppure in altri casi possono aiutare gli sviluppatori a diagnosticare problemi con i loro siti web, vedi ad esempio Screaming Frog.
Perché qualcuno vorrebbe verificare uno spider?
Se possiedi un sito web e desideri essere visibile nei risultati di ricerca di Google devi prima essere visitato dai suoi crawler. Googlebot deve essere in grado di eseguire la scansione del tuo sito e indicizzare i tuoi contenuti. Se pensi di avere criticità SEO sul tuo sito web, verifica i log del server e le pagine richieste da Googlebot, è utile per diagnosticare i problemi.
Ci sono anche scopi più specifici per identificare tutti i bot che passano dal tuo web server. Ad esempio, potresti essere legalmente costretto a limitare l’accesso al tuo sito per alcuni paesi. Durante il blocco degli utenti dovresti consentire l’accesso ai bot dei motori di ricerca da quel paese, specialmente se si tratta degli Stati Uniti (Googlebot scansione prevalentemente dagli Stati Uniti).
Ovviamente, per fare questo genere di esclusioni devi sapere con certezza se una richiesta è stata fatta da un utente reale o da un crawler.
Come rilevare uno spider?
Quando navighi sul web il tuo browser firma ogni richiesta che fai con il suo nome, chiamato User Agent. Ad esempio, questo è l’user-agent di Google Chrome alla data in cui scrivo:
“Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36”.
Google non usa soltanto Googlebot come spider, ne ha molti altri come ad esempio quelli dedicati alle funzioni di advertising. Qui trovi l’elenco degli user-agent usati da Google.
Ogni client – browser e bot, si presenta con il suo User-agent stampato nell’intestazione HTTP della richiesta. L’user-agent quindi è il primo metodo, il più semplice ma anche il più insicuro, per identificare uno spider.
I bot possono mentire?
Si, certamente. Il vero Googlebot si presenta sempre con il suo vero nome. Tuttavia, ci sono altri bot che si possono presentare con user-agent Googlebot e le loro intenzioni potrebbero non essere delle più benevole.
Modificare l’user-agent è semplice anche per i meno esperti: con la maggior parte dei browser è possibile modificare questo valore.
Anche i SEO visitano spesso le pagine o addirittura eseguono la scansione di interi siti presentandosi come Googlebot a scopi di diagnostica. In diversi casi un SEO deve emulare Goolebot per capire se il web server si comporta correttamente.
Quindi come abbiamo visto, se vuoi fare un’analisi del log filtrando solo Googlebot senza pretesa di escludere eventuali fake, ovvero dei falsi Googlebot, il metodo di rilevamento degli User Agent è il più semplice e veloce da implementare.
Metodo di verifica dell’user-agent
Nel caso invece fosse necessario validare correttamente l’origine di una richiesta, è necessario verificare l’indirizzo IP da cui è stata effettuata la richiesta.
Camuffare il proprio IP non è impossibile ma non è nemmeno semplicissimo. Si può usare un server proxy DNS e nascondere l’IP reale, ma questo metodo rivelerà l’IP del proxy, che può essere identificato.
In linea di massima, se sei in grado di identificare le richieste che provengono dall’intervallo IP del crawler, sei a cavallo. Alcuni crawler forniscono elenchi o intervalli IP da utilizzare, ma la maggior parte di essi, incluso Google, non lo fa, ci sono buone ragioni per non farlo. Tuttavia, Google fornisce un modo per convalidare l’IP della richiesta.
Prima di spiegarti come farlo, torniamo indietro ed esploriamo gli scenari in cui è necessario convalidare le richieste del crawler.
- Il primo scenario che esamineremo è l’ analisi dei log dei server. In questa attività dati di origine sbagliati possono portare a considerazioni totalmente fuori strada. Quando analizzo il log per capire il comportamento di Googlebot, devo essere certo che i dati che sto analizzando sono DAVVERO di Googlebot, e non di qualcuno che ha scansionato il sito a nome suo. Immagina che per qualche motivo parte del tuo sito non sia indicizzata perché è bloccata in robots.txt, ma nel tuo log potresti vedere scansioni di quelle pagine da parte di Googlebot. Come stabilirai se è stato il vero Googlebot ad ignorare le direttive del tuo robots.txt oppure se è stato un altro spider sotto falso nome? Considera che Googlebot tende a rispettare le direttive del robots.txt.
- Un’altra situazione che si vuole davvero evitare è quella di offrire agli scraper una versione pre-renderizzata del proprio sito. Questo è dannoso per due motivi. Primo: il pre-rendering costa tempo di elaborazione del server. Questo costo non è trascurabile e molte richieste possono danneggiare in modo significativo le prestazioni del web server. Il duro lavoro di rendering andrebbe fatto solo per i crawler dei motori di ricerca che ti interessano. Secondo: il rendering di JavaScript può essere complesso e richiede risorse, pochi spider riescono a farlo. Se quegli scraper fastidiosi non renderizzano JavaScript c’è una buona possibilità che non saranno in grado di rubare i tuoi contenuti, quindi devi riconoscerli e fornire un contenuto NON pre-renderizzato come invece faresti con Googlebot.
Intervalli IP
Come affermato in precedenza, alcuni dei più popolari crawler dei motori di ricerca forniscono elenchi o intervalli IP statici. Ne elencherò alcuni di seguito.
DuckDuckGo
- 72.94.249.34
- 72.94.249.35
- 72.94.249.36
- 72.94.249.37
- 72.94.249.38
Ask
- 65.214.45.143
- 65.214.45.148
- 66.235.124.192
- 66.235.124.7
- 66.235.124.101
- 66.235.124.193
- 66.235.124.73
- 66.235.124.196
- 66.235.124.74
- 63.123.238.8
- 202.143.148.61
Fonte: https://www.distilnetworks.com/bot-directory/bot/teoma/
Come verificare Googlebot con la Ricerca DNS
Google non pubblica un elenco di indirizzi IP che i webmaster possono aggiungere alla whitelist, Infatti, gli intervalli degli indirizzi IP possono cambiare, causando problemi ai webmaster che ne hanno eseguito l’hard-coding.
Per gli spider che non forniscono elenchi IP ufficiali dovrai eseguire ricerche DNS per verificarne l’origine. La ricerca DNS è un metodo per connettere un dominio a un indirizzo IP. Ad esempio, ti mostrerò come rilevare Googlebot, ma la procedura per altri crawler è identica.
La procedura che ti mostrerò è quella suggerita ufficialmente da Google per la verifica di Googlebot.
Il primo passaggio del processo è chiamato ricerca DNS inversa (reverse DNS lookup), in cui si chiederà al server di presentarsi con il nome del dominio. Se stai utilizzando il prompt dei comandi di Windows, puoi usare il comando nslookup. Su Linux il comando equivalente è host.
In questo esempio uso il comando tail per leggere il log ed il comando grep per filtrare solo le richieste di Googlebot in modo da trovare gli IP da verificare:
sudo tail -f -n 500 /var/log/log-del-sito.log | grep -i googlebot
{kind=link}
Ora digitiamo il comando nslookup seguito dall’IP per trovare il nome del dominio.
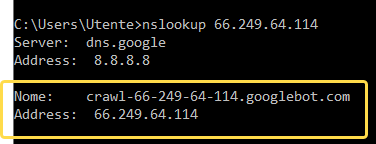
Il dominio corretto per Googlebot deve finire con “.googlebot.com”.
Non è sufficiente che Googlebot.com appaia nella stringa, deve proprio apparire alla fine. Ad esempio un dominio chiamato googlebot.com.imascam.se sicuramente non appartiene al vero Googlebot.
Come essere sicuri al 100%?
C’è un modo per ingannare questo metodo. È possibile impostare un reindirizzamento dal proprio server al server valido di Googlebot. In questo caso se chiedi al server il suo nome, otterrai il dominio Googlebot corretto! Per poter gestire questa possibilità devi chiedere il nome del dominio per il suo indirizzo IP. Puoi usare lo stesso comando appena visto, ma questa volta con il nome del dominio invece dell’indirizzo IP.
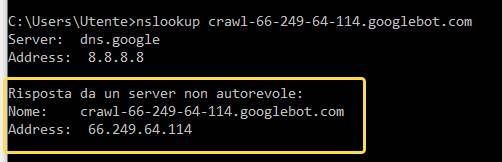
Se l’indirizzo IP della risposta corrisponde all’IP della richiesta, hai appena convalidato un vero Googlebot.
Ecco un elenco dei domini dei crawler più popolari:
- Baidu: *.crawl.baidu.com
- Baidu: *.crawl.baidu.jp
- Bing: *.search.msn.com
- Googlebot: *.google.com
- Googlebot: *.googlebot.com
- Yahoo: *.crawl.yahoo.net
- Yandex: *.yandex.ru
- Yandex: *.yandex.net
- Yandex: *.yandex.com
Un piccolo bonus: nel caso di Bing, puoi verificare l’IP direttamente su questa pagina ma non puoi automatizzare il processo di verifica, poiché è solo per uso umano.
Whitelist
A questo punto ti starai probabilmente chiedendo perché Google non ha pubblicato il loro elenco IP come fanno gli altri. La risposta è semplice: i loro intervalli IP potrebbero cambiare in futuro. Tale elenco sopravviverà sicuramente in alcune configurazioni server, rendendole vulnerabili.
Tuttavia, non dovresti usare una reverse DNS lookup per ogni richiesta, sarebbe troppo dispendioso. La cosa giusta da fare è creare una lista temporanea di IP, una whitelist.
L’idea di base è questa – quando ricevi una richiesta da user-agent Googlebot, per prima cosa controlla la tua lista bianca. Se è presente nell’elenco, sai che è un Googlebot valido. Nei casi in cui provenisse da un indirizzo IP non inserito nella whitelist è consigliabile eseguire una ricerca nslookup. Se l’indirizzo è verificato positivamente, inseriscilo nella lista.
Tieni presente che la whitelist è temporanea. Dovresti rimuovere periodicamente o ricontrollare tutti gli indirizzi IP con una cera frequenza e costanza. Se ricevi molte richieste false, dovresti pensare anche a una lista nera – blacklist per escludere tali richieste senza effettuare la ricerca DNS. Poco tempo fa scrissi una guida su questo argomento: come installare fail2ban, software che appunto può essere usato a bannare IP indesiderati.
Sommario
Prima di passare all’implementazione di queste soluzioni chiediti di cosa hai veramente bisogno. Se hai bisogno semplicemente di rilevare i bot e non ti preoccupano i falsi positivi, allora cerca il più semplice rilevamento degli User Agent.
Quando invece ti serve certezza e verifica dei dati, allora dovrai sviluppare la procedura di ricerca DNS. Mentre lo fai, tieni presente che questo processo può rallentare il TTFB, cioè tempo di risposta del tuo web server. Per questa ragione sarebbe opportuno implementare un metodo di memorizzazione nella cache dei risultati della ricerca DNS, ma non tenerli troppo a lungo poiché gli indirizzi IP dei motori dei motori di ricerca potrebbero cambiare.
Articoli correlati
Autore

Mi chiamo Giovanni Sacheli e dal 2009 aiuto le aziende a farsi trovare online. Sono specializzato in SEO tecnica e PPC, competenze che applico quotidianamente nella mia agenzia, Searcus Swiss Sagl. Mi piace sviluppare strumenti a supporto del mio lavoro, ho creato SEOdata.app e cluster.army e co-scritto il libro SEO Audit Avanzato. Curo maniacalmente questo blog per colleghi e appassionati, dove mi "appunto" quello che imparo. Sono un NERD anni '80, motociclista e orgoglioso papà di due bambini.
Link:
Giovanni Sacheli
SEO Audit Avanzato
Searcus Swiss Sagl
SEOdata.app
cluster.army