Trascrizione del video
Ciao a tutti amici e colleghi SEO. Questo video è collegato ad un post che ho condiviso su Linkedin un paio di settimane fa, dove raccontavo che tramite Python e le API di Google Search Console ero riuscito a scaricare dal report performance una grossa mole di dati, superando di gran lunga i limiti di mille righe che l’interfaccia ci permette di scaricare.
Per i siti più grandi, questo script è stato in grado di ottenere anche un milione di righe da Google Search Console. Questo mi ha permesso di fare considerazioni e valutazioni più dettagliate, rispetto ai dati limitati che l’interfaccia ci offre.
Nel video che ho incluso, potete vedere come ho utilizzato Python e alcune librerie per connettermi alle API di Google Search Console e scaricare questi dati. Inoltre, per rendere il processo ancora più interessante, ho aggiunto anche un tocco di intelligenza artificiale, utilizzando GPT.
Spero che questo video vi sia utile e vi invito a provare anche voi a utilizzare Python e le API di Google Search Console per ottenere dati più dettagliati!
Partiamo!
Per prima cosa, se volete utilizzare lo script sul Colab, avrete bisogno di un file di credenziali. Potete ottenerlo collegandovi a Google Cloud Console e creando un nuovo progetto. Successivamente, attivate le API di Google Search Console.
Una volta fatto ciò, andate nella sezione Credenziali e create delle credenziali OAuth 2.0. Scegliete “Applicazione desktop” come tipologia di applicazione, perché sarà più semplice collegarla allo script.
Dopo aver creato le credenziali, tornate alla sezione Credenziali e scaricate il file “Scarica client OAuth”. Rinominate il file, rimuovendo la parte numerica. Ad esempio, potete chiamarlo “client_secret_.json”.
Riassumendo:
- Accedi alla console di Google API. Se non hai un account Google, dovrai crearne uno e accedere alla console.
- Crea un nuovo progetto. Seleziona il progetto in alto a sinistra e fai clic su “Nuovo progetto” per crearne uno nuovo.
- Abilita l’API di Search Console. Fai clic sul pulsante “Abilita le API e i servizi” in alto nella console. Cerca “Google Search Console API” e abilitala.
- Crea un’identità OAuth. Ora che hai abilitato l’API di Search Console, devi creare un’identità OAuth per l’app desktop. Per farlo, fai clic su “Crea identità OAuth” nella finestra pop-up che appare dopo aver abilitato l’API.
- Configura l’identità OAuth. Seleziona “Desktop app” e inserisci un nome per l’identità OAuth.
- Scarica il file delle credenziali. Dopo aver creato l’identità OAuth, fai clic sul pulsante “Scarica” per scaricare il file delle credenziali. Il file dovrebbe essere in formato JSON.
- Salva il file delle credenziali. Salva il file delle credenziali in una posizione sicura sul tuo computer.
- Rinominate il file togliendo la parte numerica:
- quindi cambiate da qualcosa del genere: client_secret_615567305903-ieefueojceq5624v7e9otk5clcneulpm.apps.googleusercontent.com.json
- a così client_secret_.json
Lo script richiama il file in questo modo quindi vi basta rinominarlo. Ora hai creato un’identità OAuth e recuperato il file delle credenziali per un’app desktop. Assicurati di non condividere queste credenziali con nessuno e di non includerle nel tuo codice sorgente.
Ora potremmo passare allo script e vedere come funziona. Però partiamo dal contrario vediamo l’output in Excel e dopo vediamo come funzionsa lo script.
Raw data
Il primo foglio nel file Excel si chiama Raw data.
Questi dati sono relativi alle prestazioni del sito web nei risultati di Google. Ogni riga corrisponde a una parola chiave di ricerca (“query”) utilizzata dagli utenti su Google, e contiene informazioni come il numero di volte in cui la pagina del sito web è stata visualizzata (“impressions”), il numero di volte in cui gli utenti hanno cliccato sulla pagina (“clicks”), il tasso di click-through (“ctr”), la posizione media in cui la pagina del sito web è stata visualizzata nei risultati di ricerca (“position”), e se la parola chiave è correlata al marchio (“Branded”) o meno (“Non-branded”).
In breve, questi dati forniscono informazioni utili sull’efficacia del posizionamento del sito web nei risultati di ricerca per una determinata parola chiave, nonché sull’efficacia delle tecniche di ottimizzazione dei motori di ricerca utilizzate per migliorare il posizionamento del sito web.
Quindi questo è il file Excel di Export:
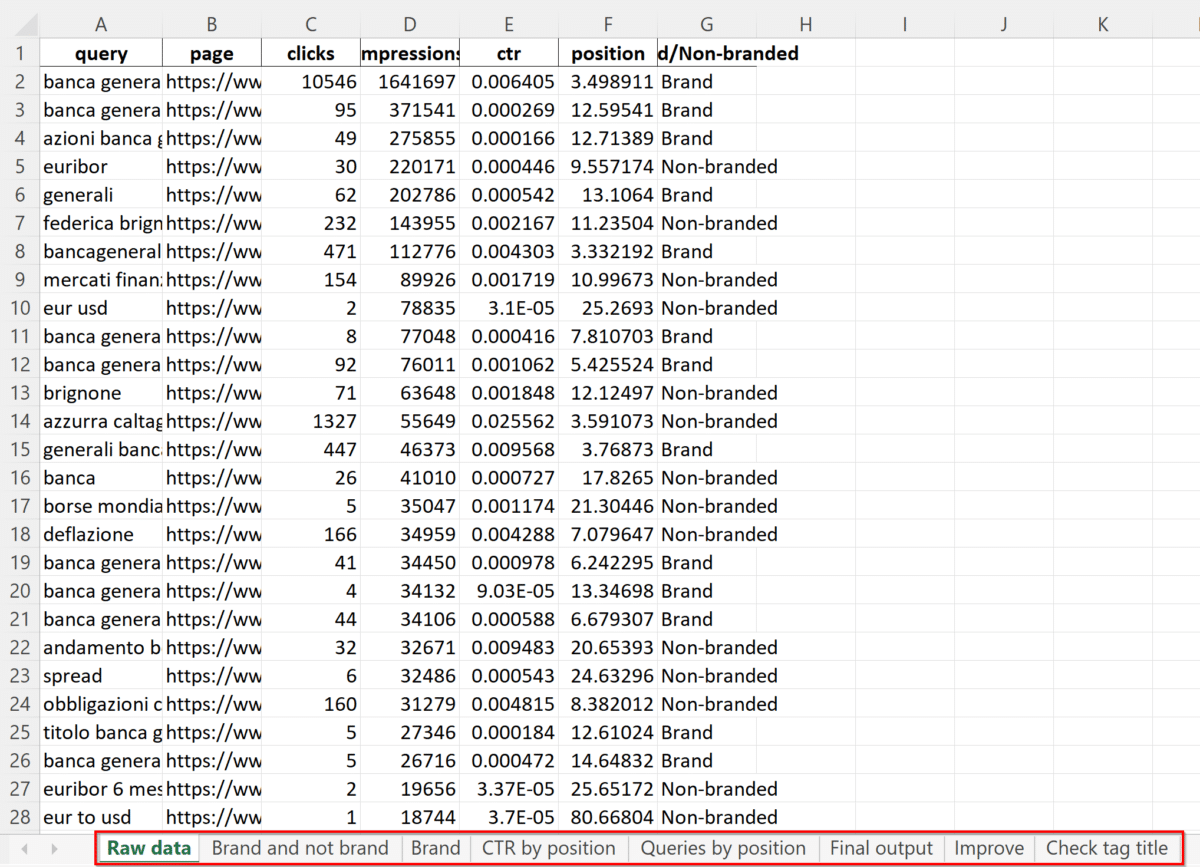
Come vedete ci sono più fogli in questo file Excel, e ogni foglio in pratica rappresenta uno step del processo di rielaborazione dei dati nativi di GSC.
Nel foglio Raw data usato nell’esempio abbiamo circa 750 mila righe con la combinazione query-URL ed i KPI di GSC: click, impressioni, CTR, posizione e poi un tag Brand non Brand.
Questi sono dati di 365 giorni di traffico. Ho scelto un anno perché volevo farvi vedere quanti dati è possibile ottenere. Tuttavia, finalità di questo file è fornire indicazioni pratiche per ottimizzare i metadati e capire quali contenuti aggiornare. Quindi è più sensato analizzare un periodo più breve, possibilmente un mese se il sito genera dati sufficienti per fare un’analisi. Un periodo breve è probabilmente la scelta migliore per analisi di questo tipo. Finalità del video era mostrare le potenzialità delle API.
Brand and not brand
Nello script si impostano le chiavi di brand, in questo modo lo script crea una colonna per taggare le parole chiave Brand e Not Brand.
Dopodiché genera una piccola tabella che posso usare ad esempio per inserire un grafico e vedere la percentuale di chiavi brand e chiavi non Brand:
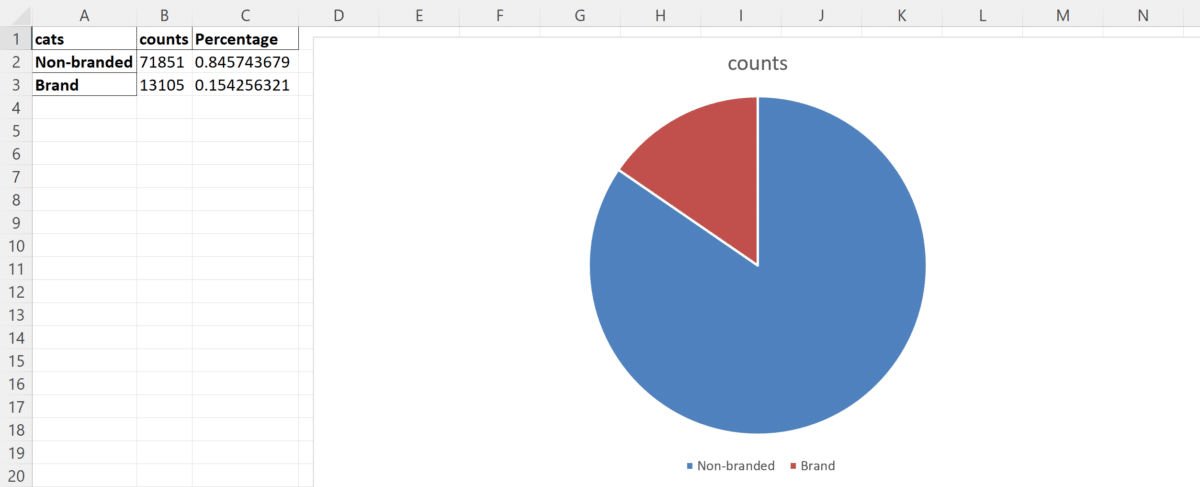
Questi dati sono relativi alla suddivisione delle parole chiave di ricerca utilizzate dagli utenti su Google per un determinato sito web in “branded” e “non-branded”.
La colonna “cats” indica se una parola chiave è correlata al marchio (“Brand”) o meno (“Non-branded”), mentre la colonna “counts” indica il numero totale di volte che ciascuna parola chiave è stata utilizzata dagli utenti. Infine, la colonna “Percentage” indica la percentuale di volte in cui ciascuna parola chiave è stata utilizzata rispetto al totale.
In questo caso, sembra che la maggior parte delle parole chiave utilizzate dagli utenti non siano correlate al marchio del sito web (“Non-branded”), rappresentando il 84.57% del totale, mentre solo lo 15.42% delle parole chiave sono correlate al marchio (“Brand”). Ciò suggerisce che la maggior parte del traffico di ricerca organica per il sito web in questione provenga da parole chiave non correlate al marchio.
Nel foglio a destra troviamo poi la lista di tutte le chiavi di brand. Può capitare ci sia la stessa parole chiave ripetuta in più righe perché abbiamo più URL che si posizionano per le query brand.
Con una tabella pivot possiamo raggruppare le query uniche e sommare impressioni e click:
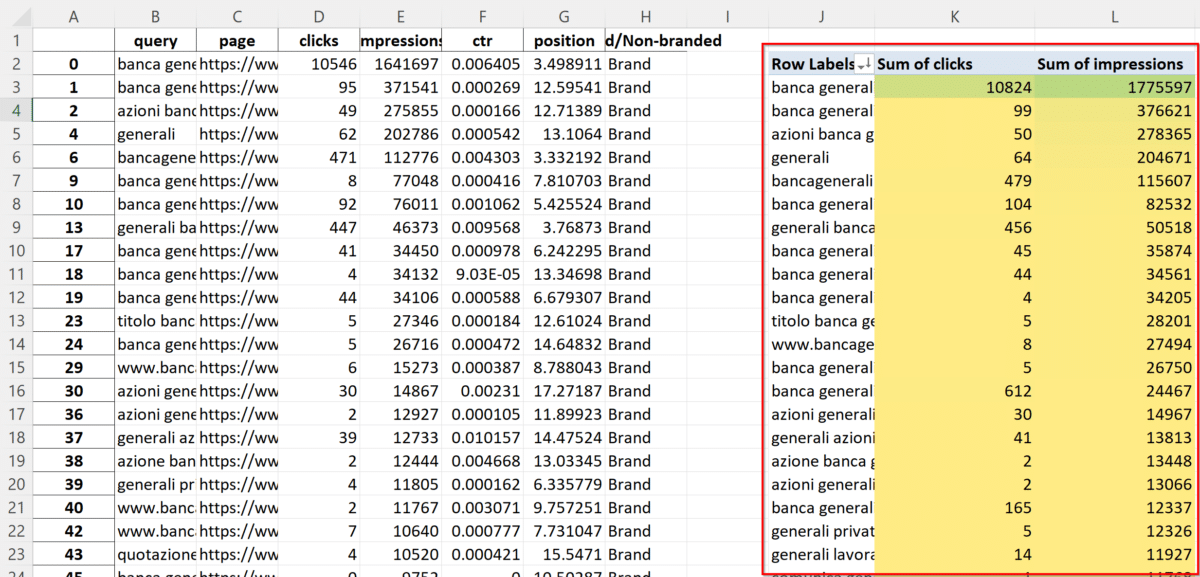
Quali sono le query di brand che fanno più click o che fanno più impressioni? Da questi dati possiamo capire quali sono le caratteristiche del brand che interessano maggiormente all’utente che ricerca online.
CTR by position
La scheda successiva calcola il tasso di click-through (CTR) medio del sito web per ciascuna posizione nei risultati di ricerca. Questo dato è di particolare interesse in quanto uno degli obiettivi di questa analisi è migliorare i metadati del sito, in particolare il tag title. Per valutare l’efficacia di un tag title, si utilizza spesso il CTR in relazione alla posizione nei risultati di ricerca.
Tuttavia, utilizzare i valori standard del CTR medio per posizione delle pagine dei risultati dei motori di ricerca online potrebbe non essere accurato. I valori del CTR possono variare da pagina a pagina dei risultati di ricerca. Ci sono pagine senza annunci, pagine con annunci, pagine con Local Pack, pagine con Caroselli e altri elementi che possono influire sui valori del CTR delle prime dieci posizioni gratuite.
Pertanto, per valutare se un CTR del 6% per il nostro sito nella posizione 3 è buono o cattivo, potrebbe essere più utile confrontare il CTR di una combinazione di query-URL con il CTR medio dello stesso sito nella stessa posizione. Questo perché il sito appare spesso in pagine di risultati di ricerca simili per contenuto, quindi ha senso confrontare il CTR medio di una determinata combinazione di query e URL con il CTR medio dello stesso sito nella stessa posizione.
Naturalmente, è importante escludere le parole chiave correlate al marchio, in quanto potrebbero distorcere notevolmente i dati. Il database utilizzato per l’analisi distingue le parole chiave correlate al marchio da quelle non correlate, e le esclude nei passaggi successivi.
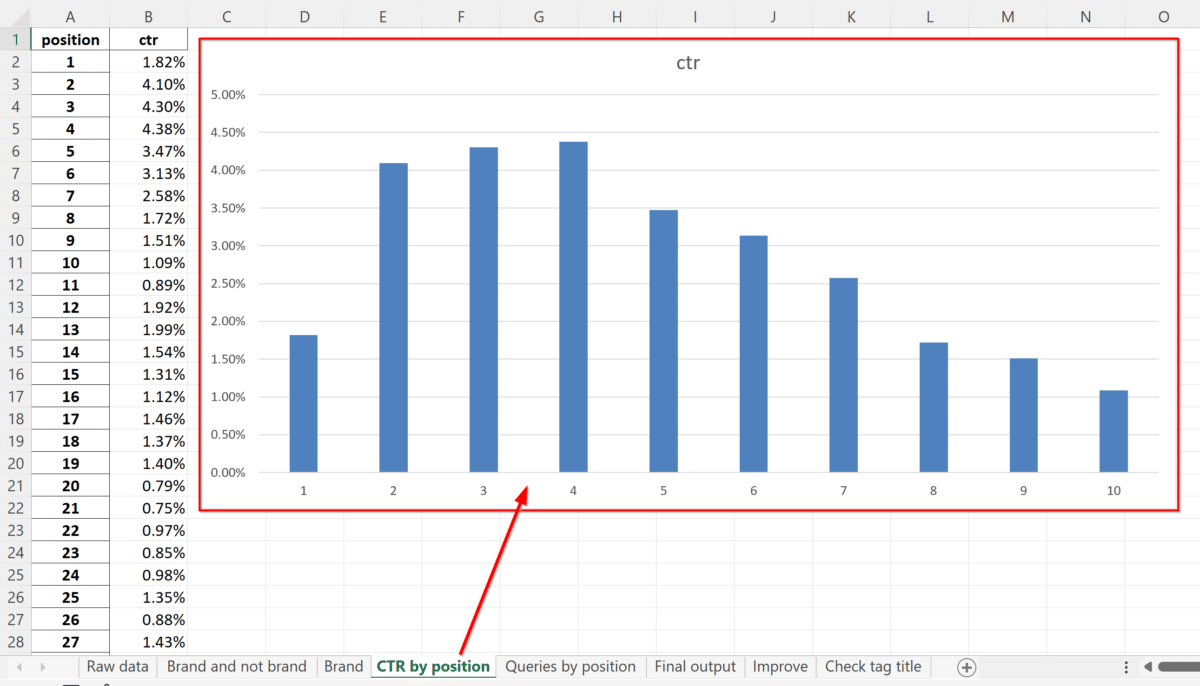
Con i dati raccolti, è possibile creare un grafico del CTR medio per ciascuna posizione nella pagina dei risultati di ricerca (SERP). Questo grafico può essere utile per valutare il CTR di varie combinazioni di query-URL presenti nei fogli successivi.
È importante notare che, in alcuni casi, la prima posizione non ha un CTR maggiore rispetto alla seconda. Ciò può accadere per diversi motivi, tra cui il fatto che Google potrebbe posizionare il sito in prima posizione per termini di ricerca troppo generici, rendendo il risultato troppo ampio e quindi meno pertinente per gli utenti. Inoltre, l’URL del sito potrebbe apparire in prima posizione nella SERP come sitelink e non come URL principale dello snippet, facendo così molte impressioni in prima posizione ma pochi click effettivi.
Questi fattori possono influire sulla performance del CTR del sito e devono essere tenuti in considerazione durante l’analisi dei dati.
Query by position
Nel foglio che segue abbiamo i dati della distribuzione delle query per ciascuna posizione in SERP.
I dati indicano il conteggio del numero di volte che il sito è apparso in ciascuna posizione della SERP. Il sito usato nell’esempio è apparso più volte in seconda posizione (4.719 volte) rispetto alle altre posizioni, il che suggerisce che il sito è ben ottimizzato per le parole chiave target e ha una buona autorevolezza nel settore. Tuttavia, ci sono margini di miglioramento dato che le query in prima posizione non sono poi così tante.
Inoltre, è importante tenere presente che l’aumento del traffico verso il sito non dipende solo dalla posizione nella SERP, ma anche dal CTR. Un buon tag title in posizione 5 potrebbe ottenere più click di un risultato con un cattivo tag title in posizione 4.
Gli specialisti SEO dovrebbero considerare questi fattori quando cercano di migliorare le posizioni del sito nei risultati di ricerca.
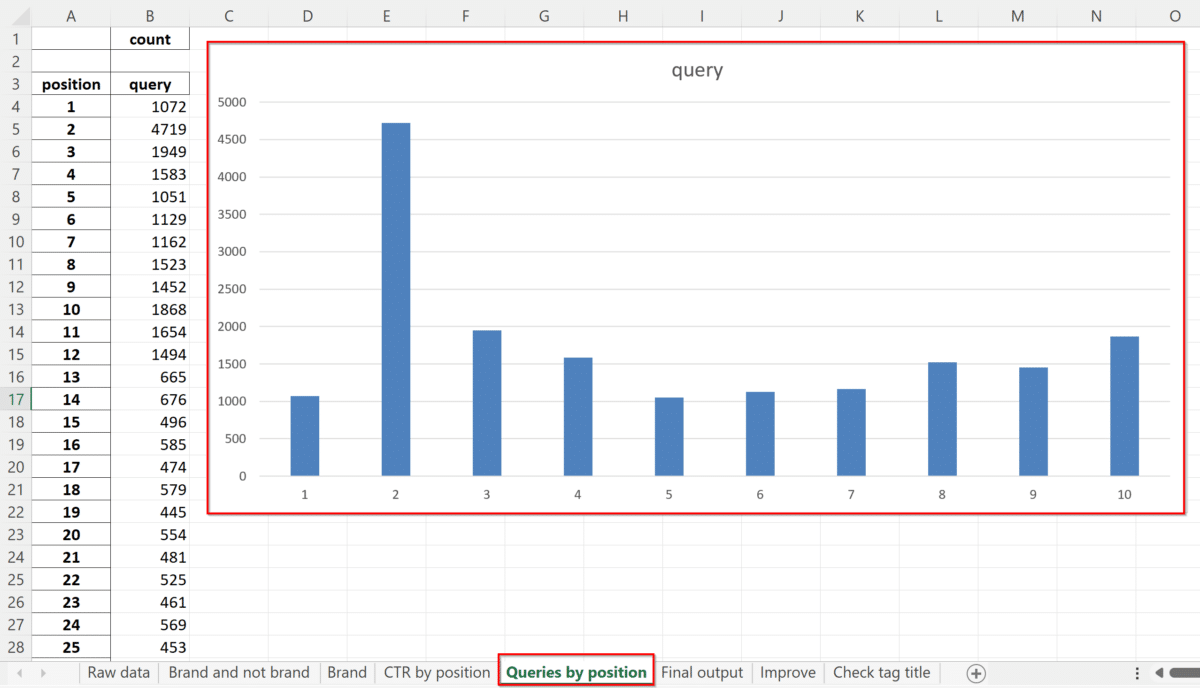
Come posiziona il sito web le sue query? Il grafico mostra come sono distribuite le nostre parole chiave in top 100 o in top 10
Final output
Il foglio successivo è il database finale “final output”. Le query in questo foglio sono filtrate da un valore minimo di impressioni e posizione. Questi valori sono impostabili nello script.
La tabella mostra una lista di query di ricerca, le pagine del sito che hanno ricevuto il traffico di ricerca per quella query, il numero di clic che hanno ricevuto, il numero di impressioni che hanno avuto, la posizione media in cui è apparso il sito nella SERP, il CTR della query, il CTR medio per posizione, il confronto del CTR della query con il CTR medio per posizione, se la query è brand o non-brand, il termine più frequente all’interno della query, le prime 5 query che hanno generato traffico sul sito, la prima, la seconda e la terza livello di cartelle in cui si trova la pagina.
In ottica SEO, questa tabella può essere utile per identificare le parole chiave che portano traffico al sito e per analizzare le prestazioni delle pagine del sito nella SERP. Ad esempio, è possibile utilizzare i dati per confrontare il CTR medio della query con il CTR del sito per quella query e per quella posizione nella SERP. In questo modo, si può valutare la performance della pagina e determinare se è necessario migliorare la strategia SEO per quella specifica query. Inoltre, è possibile utilizzare i dati per identificare le query più frequenti e di maggior interesse per gli utenti e per focalizzare la strategia di contenuto del sito su tali argomenti.
Essenzialmente nel foglio ho mantenuto solo le query non Brand che hanno almeno 100 impression e che si posizionano in top 100.
In questo foglio possiamo valutare i tag title buoni o cattivi guardando la colonna Comparison. La colonna mostra il valore:
- lower se il CTR della combo è minore del CTR medio del sito nella medesima posizione.
- greater se il CTR della combo è maggiore del CTR medio del sito nella medesima posizione.
Improve
Il penultimo foglio mostra l’andamento di alcune query e relative pagine del sito web sui motori di ricerca. In particolare, il foglio chiamato “Improve” evidenzia le combo di query-URL che non sono posizionate tra i primi 5 risultati di Google, fornendo una lista di parole chiave (top_5_queries) utilizzate per raggiungere quelle pagine. Il valore 5 può essere impostato nello script.
Questa lista è utile per identificare le parole chiave più ricercate ma non ben posizionate, e quindi capire come migliorare il contenuto delle pagine per aumentare la loro rilevanza.
La tabella mostra anche alcune informazioni rilevanti, come il numero di click e le impression (visualizzazioni) ricevute dalle pagine per ogni query, la posizione in cui la pagina è stata mostrata sui motori di ricerca, e le directory (folder_lv1, folder_lv2, folder_lv3) presenti negli URL.
Check tag title
Nell’ultimo foglio del documento viene effettuata l’ottimizzazione dei tag title delle pagine web. Attraverso uno script di scraping dei primi 100 URL per impression, viene ottenuto il tag title attuale. Successivamente, viene creato un prompt per GPT utilizzando il tag title e le 5 query più forti dell’URL, e viene chiesto a GPT di generare un nuovo tag title migliore.
Le colonne del foglio includono:
- top_5_queries: le 5 query più forti come impressioni per l’URL in riga
- tag title: tag title attuale della pagina
- check: verifica se il tag titl econtiene le 5 parole chiave più forti
- new tag title: GPT riscrive il tag title usando come input il tag title attuale e le 5 parole chiave più forti
Di seguinto un esempio di come vengono utilizzate queste colonne per generare un nuovo tag title:
- Tag title attuale: cos’è l’euribor
- Top 5 queries: euribor, euribor 6 mesi, tasso euribor, tassi euribor, eurobor
- Check: Missing in tag title: euribor 6 mesi, tasso euribor, tassi euribor, eurobor
- Nuovo tag title: Scopri cos’è l’euribor e come influiscono i tassi sull’economia
Librerie usate nello script
Ecco una breve spiegazione di ciascuna libreria richiamata nello script:
- google-api-python-client: questa libreria fornisce un’API client per l’utilizzo delle API Google. Viene utilizzata in questo codice per interagire con l’API di Google Search Console.
- google-searchconsole: questa libreria è una wrapper Python per l’API di Google Search Console. Viene utilizzata per ottenere le statistiche di ricerca del sito web.
- fake_useragent: questa libreria fornisce un metodo per generare user agent falsi. Viene utilizzata per creare user agent falsi per le richieste di scraping.
- openai: questa libreria fornisce l’accesso all’API di OpenAI. Viene utilizzata per eseguire analisi di lingua naturale.
- langdetect: questa libreria fornisce un metodo per rilevare automaticamente la lingua di un testo. Viene utilizzata per rilevare la lingua delle pagine web.
- pandas, numpy e matplotlib.pyplot: queste librerie sono utilizzate per la manipolazione e la visualizzazione dei dati.
- searchconsole: questa libreria è una wrapper Python per l’API di Google Search Console. Viene utilizzata per ottenere le statistiche di ricerca del sito web.
- requests: questa libreria è utilizzata per effettuare richieste HTTP.
- math: questa libreria fornisce funzioni matematiche di base.
- re: questa libreria fornisce un modulo per eseguire espressioni regolari. Viene utilizzata per filtrare i risultati di ricerca.
- seaborn e collections.Counter: queste librerie sono utilizzate per la visualizzazione dei dati.
- nltk e stopwords: queste librerie forniscono metodi per l’elaborazione del linguaggio naturale. Viene utilizzata per il preprocessing dei testi.
- bs4.BeautifulSoup: questa libreria è utilizzata per il parsing di HTML.
- google.colab.files: questa libreria fornisce metodi per l’upload e il download di file in Google Colab.
- google.colab.data_table: questa libreria fornisce un metodo per la visualizzazione dei dataframe in una forma più leggibile.
Conclusione
Concludendo, grazie a questo script (che ho scritto con l’aiuto di GPT), senza dedicare molto tempo e senza perdere più di 2 minuti ogni mese, posso ottenere una lista di combo di query e URL che devo migliorare. Posso sfruttare rapidamente i dati in input pratici per i copy o i clienti. In più ho anche 100 titoli generati da GPT. Ovviamente, si possono anche scansionare 1.000 URL se lo si desidera. Il numero di URL che vengono scansionati può essere impostato nello script, quindi è personalizzabile in base alle proprie esigenze. GPT cerca nuovi tag title per quelli che abbiamo scansionato. In base a quanti ne abbiamo scansionati, GPT ci darà più o meno risultati.
È probabile che ti servano le API di GPT a pagamento, in agenzia le usiamo perché facciamo molte query. L’AI ci aiuta a risparmiare tempo, anche se la qualità al momento non è ottimale. Su 100 titoli generati, magari 30 sono buoni, 30 sono da sistemare e 30 sono sbagliati. Ma avere 30 titoli buoni è già un buon risultato su 100 titoli da fare. Quindi, in sostanza, è un aiuto che apprezzo molto.
Ora andate a vedere lo script e i vari passaggi. È una cosa un po’ più tecnica, ma non preoccupatevi se non siete esperti di Python. Io non lo sono, sono un novellino totale, quindi non aspettatevi cose complesse. Lo script è molto semplice, è solo abbastanza lungo perché è articolato. In sé, le funzioni sono molto semplici.
Ecco qui lo script su Colab, una piattaforma online che ci permette di eseguire script in Python 3 senza dover installare Python sul nostro computer. È molto comodo per testare gli script velocemente e condividerli facilmente.
Mi volete bene? Lasciate un commento!
Articoli correlati
Autore

Mi chiamo Giovanni Sacheli e dal 2009 aiuto le aziende a farsi trovare online. Sono specializzato in SEO tecnica e PPC, competenze che applico quotidianamente nella mia agenzia, Searcus Swiss Sagl. Mi piace sviluppare strumenti a supporto del mio lavoro, ho creato SEOdata.app e cluster.army e co-scritto il libro SEO Audit Avanzato. Curo maniacalmente questo blog per colleghi e appassionati, dove mi "appunto" quello che imparo. Sono un NERD anni '80, motociclista e orgoglioso papà di due bambini.
Link:
Giovanni Sacheli
SEO Audit Avanzato
Searcus Swiss Sagl
SEOdata.app
cluster.army
Commenti |6
Lascia un commentoBellissimo lavoro!
Grazie Marco per il supporto :D
Super interessante! Proverò. Intanto segnalo questa risorsa. Grazie.
Grazie Andrea, fammi sapere ;)
Ciao Giovanni e complimenti come sempre per essere avanti anni luce rispetto ad altri. Una sola domanda: lo script devo prima importarlo in Google Cloud in un mio progetto e poi scaricarlo da lì per attivarsi?
Grazie in anticipo
Ciao Lorenzo, grazie per il commento.
Per usare lo script devi seguire le istruzioni del video: creare una copia del file colab, creare un progetto in google cloud, prendere le tue credenziali e usarle nello script.
lo script poi si lancia direttamente da colab.
Se hai problemi pratici nel seguire le istruzioni scrivimi un commento che cerco di aiutarti!