Analizzando le statistiche di scansione di Google Search Console oppure leggendo il log del web server ti sei accorto che Googlebot perde tempo scansionando link tecnici che non dovrebbe seguire?
A volte Googlebot scansiona URL che non è ben chiaro dove abbia trovato, URL non generati dal sito ma probabilmente trovati linkati nel web oppure generati a casaccio dallo spider (a volte capita che lo faccia!).
In altri casi è proprio il sito web a generare URL che non rappresentano pagine web da indicizzare, ma sono funzionali a qualcosa e non è necessario che Googlebot li scansioni.
Vediamo un esempio.
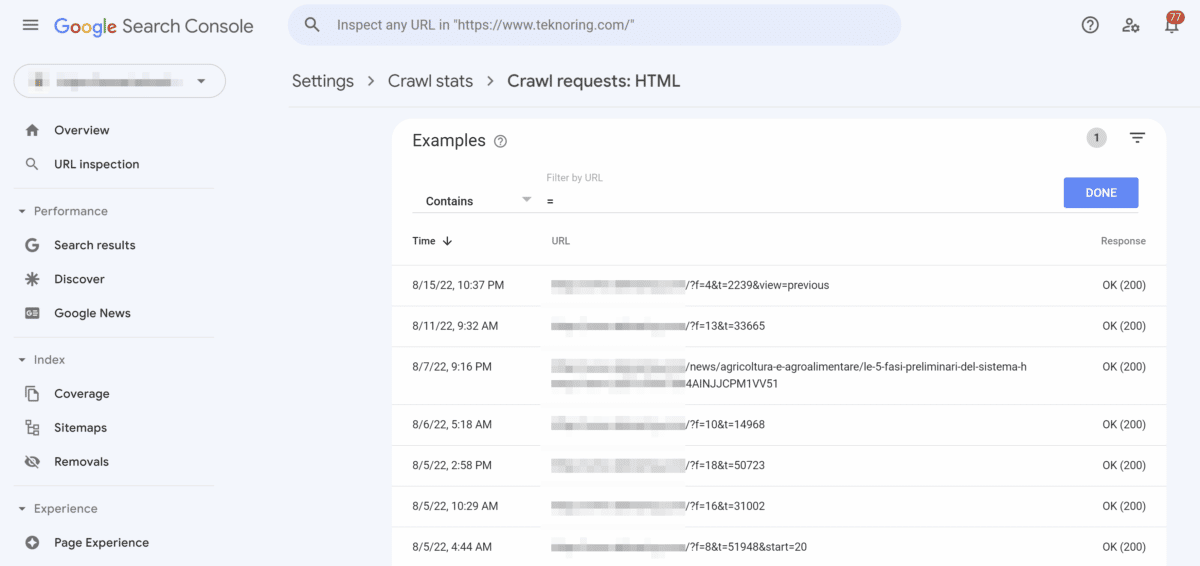
Di solito i parametri vengono canonicalizzati, appunto con il tag rel canonical. Di solito questo tag basta per non fa indicizzare URL con query string e lentamente Googlebot smette di scansionarli.
Tuttavia, può capitare che Googlebot continui a scansionare URL parametrizzati canonicalizzati, perdendo tempo e, per grandi siti web, anche parte del crawl budget. In questo caso, e in pochissimi altri, consiglio di usare la direttiva Disallow nel Robots.txt.
Cos’è il robots.txt
Robots.txt è un file di testo creato dai webmaster per istruire i bot web (in genere i bot dei motori di ricerca) su come eseguire la scansione delle pagine del loro sito web. Il file robots.txt fa parte del protocollo di esclusione robot (REP), un gruppo di standard web che regolano il modo in cui i robot eseguono la scansione del web, accedono e indicizzano il contenuto e lo forniscono agli utenti. Il REP include anche direttive come i meta robot, nonché istruzioni a livello di pagina, sottodirectory o sito su come i motori di ricerca dovrebbero trattare i collegamenti (come “follow” o “nofollow”).
A cosa serve la direttiva Disallow?
La Direttiva Disallow nel robots.txt viene usata per dire ai motori di ricerca di non accedere a determinati file, pagine o sezioni del tuo sito web. La direttiva Disallow è seguita dal percorso a cui non si dovrebbe accedere.
Attenzione a questo piccolo dettaglio, ho scritto “non accedere” e non “non indicizzare”! Puoi trovare approfondimenti sulla questione nella guida sul Robots.txt linkata sopra.
La direttiva Disallow non va usata per de-indicizzare contenuto o per prevenirle la sua indicizzazione, questo è compito del meta robots tag NOINDEX. In alternativa per evitare l’indicizzazione si può usare il tag rel Canonical che punta alla pagina corretta.
Ad esempio, se nel report Coverage e nelle statistiche di scansione di Google Search Console dovessi trovare molti URL parametrizzati e tecnici come print=pdf o altre funzionalità che non hanno impatto sul contenuto, allora potrebbe avere senso iniziare a gestire la situazione.
Come impedire la scansione di URL parametrizzati?
Per chiedere ai motori di ricerca di non scansionare una risorsa o un set di risorse si usa la direttiva Disallow nel Robots.txt. Per escludere tutti i parametri dalla scansione devi inserire queste righe:
User-Agent:*
Disallow: /*?*Tuttavia, questa regola potrebbe essere eccessiva dato che blocca la scansione di URL con qualsiasi parametro.
Quindi, come fare per selezionare solo i parametri da escludere con la direttiva Disallow? Molto semplice, con questa regola:
User-Agent:*
Disallow: *parametro_1=*
Disallow: *parametro_2=*Per aggiungere eccezioni devi inserirle prima dell’esclusione. Ad esempio lasciamo che i motori di ricerca possano scansionare URL con parametro “parametro_1” dentro la cartella /ciccio/:
User-Agent:*
Allow: /ciccio/*parametro_1=*
Disallow: *parametro_1=*
Disallow: *parametro_2=*Dubbi? Domande? Lascia un commento e aggiungerò nuovi casi!
Articoli correlati
Autore

Mi chiamo Giovanni Sacheli e dal 2009 aiuto le aziende a farsi trovare online. Sono specializzato in SEO tecnica e PPC, competenze che applico quotidianamente nella mia agenzia, Searcus Swiss Sagl. Mi piace sviluppare strumenti a supporto del mio lavoro, ho creato SEOdata.app e cluster.army e co-scritto il libro SEO Audit Avanzato. Curo maniacalmente questo blog per colleghi e appassionati, dove mi "appunto" quello che imparo. Sono un NERD anni '80, motociclista e orgoglioso papà di due bambini.
Link:
Giovanni Sacheli
SEO Audit Avanzato
Searcus Swiss Sagl
SEOdata.app
cluster.army