Premessa
A settembre mentre ero al mare in totale relax mi chiama Roberto, un amico con cui collaboro:
– Roberto: Ciao Giovanni, ho un nuovo progetto per te!
– Io: Ottimo Roberto, di che si tratta?
– Roberto: E’ un cliente importante…
– Io: Benissimo, continua…
– Roberto: Il lavoro è praticamente già tuo…
– Io: Fantastico, dimmi altro…
– Roberto: Ha un sito molto grande…
– Io: Interessante, qual è la fregatura?
– Roberto: E’ sviluppato in AngularJS…
– Io: …
– Roberto: Giovanni?! Ci sei ancora?
– Io: Con Angular hai detto?
– Roberto: Purtroppo si! Hanno problemi di indicizzazione…
– Io: Ma dai?! Chi lo avrebbe mai detto…
Questa è stata la prima reazione ad AngularJS :D
Il mio approccio è stato molto prudente, non mi sentivo preparato. L’infrastruttura che avrei dovuto analizzare era complessa, il cliente richiedeva un livello di consulenza più alto di quello che al momento ero in grado di offrire su AngularJS (come dice il saggio, più sai e più ti rendi conto di non sapere). Con passione e dedizione mi sono messo a leggere per rispondere ai tutti dubbi, ho passato due mesi a colmare lacune studiando casi di implementazioni ed ottimizzazioni con AngularJS. Una volta approfondite le competenze che mi servivano ho svolto un SEO audit del sito web e, insieme al team di sviluppatori, abbiamo poi corretto e risolto tutte le criticità tecniche che impedivano al sito di venire indicizzato correttamente.
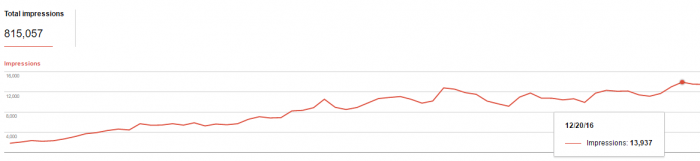
Nella seguente immagine è mostrato l’aumento di impressioni su Google dopo l’ottimizzazione tecnica: la sezione del sito sviluppata in AngularJS è passata da 1.800 impressioni al giorno a quasi 14.000. Con un buon lavoro si possono ottenere risultati importanti anche con AngularJS.
Questa guida è il frutto dell’esperienza maturata lavorando su questo progetto in AngularJS 1.0 e completa l’intervento che ho tenuto al Search Marketing Connect 2016
Tecnologie per lo sviluppo di applicazioni e siti web come Angular (tecnologia spinta da Google), React (tecnologia spinta da Facebook) e Angular 2.0 stanno lentamente proliferando. Dal punto di vista di un SEO, capire come i motori di ricerca interagiscono con queste tecnologie permette di lavorare su nuovi e stimolanti progetti.
Sei un consulente SEO? Devi ottimizzare un sito web sviluppato in AngularJS e non sai da che parte iniziare? Ci sono diverse strade percorribili per avere un sito indicizzabile. Continua a leggere questa guida e, alla fine, potresti avere le idee un pochino più chiare.
Le basi della SEO con AngularJS
AngularJS renderizza le pagine con JavaScript lato client, ovvero nel browser dell’utente che ha richiesto la pagina. AngularJS fornisce tante funzionalità pratiche agli sviluppatori ed è uno strumento molto potente per creare rapidamente applicazioni web. AngularJS è definito un templating language che scarica il lavoro di rendering quasi completamente al client – il tuo browser.
Il consiglio che trovavi sulle linee guida di Google Webmaster era quello di rendere i contenuti scalabili, accessibili ai motori di ricerca, evitando contenuti JavaScript-only. Questo punto di vista è cambiato, Google prova a renderizzare siti web che fanno uso massiccio di JavaScript. I risultati tuttavia non sempre sono quelli desiderati.
Cosa cambia rispetto ad una normale pagina HTML?
Pensa ad una pagina web classica in HTML come quella che stai leggendo ora. Il codice HTML che stai visualizzando è un modello, costruito e personalizzato da funzioni di alcuni file PHP e ricerche nel database mySQL. Il codice HTML si è compilato sul web server nel momento in cui hai richiesto la pagina, e poi ti è servita via HTTP(S).
In presenza di livelli di cache, se qualcun’altro ha richiesto questa pagina prima di te, è probabile che tu stia leggendo la copia cache, costruita dal servizio CDN prima che tu atterrassi su questa pagina. In questo momento stai leggendo una pagina web che è in sostanza un file HTML che è stato servito da un web server. E’ stato consegnato dopo che hai inviato una richiesta HTTP GET, e ora è nel tuo PC. Se tu volessi vedere un’altra pagina web, il mio web server sarà lieto di renderizzarla ed inviartela. Se tu volessi interagire con una pagina, magari compilando un form, invieresti una richiesta POST. Ecco come funziona Internet.
Questo non è proprio quello che accade quando si atterra in una pagina web integrata in un framework JS come AngularJS. In sostanza, quando si effettua una richiesta ad un sito in AngularJS, il contenuto che vedi è il risultato di una manipolazione del DOM con Javascript, avvenuta nel tuo browser. Certo, ci sono diverse chiamate HTTP tra client e server (utilizzando il servizio http $ di AngularJS), ma è il client che sta facendo la maggior parte del lavoro pesante.
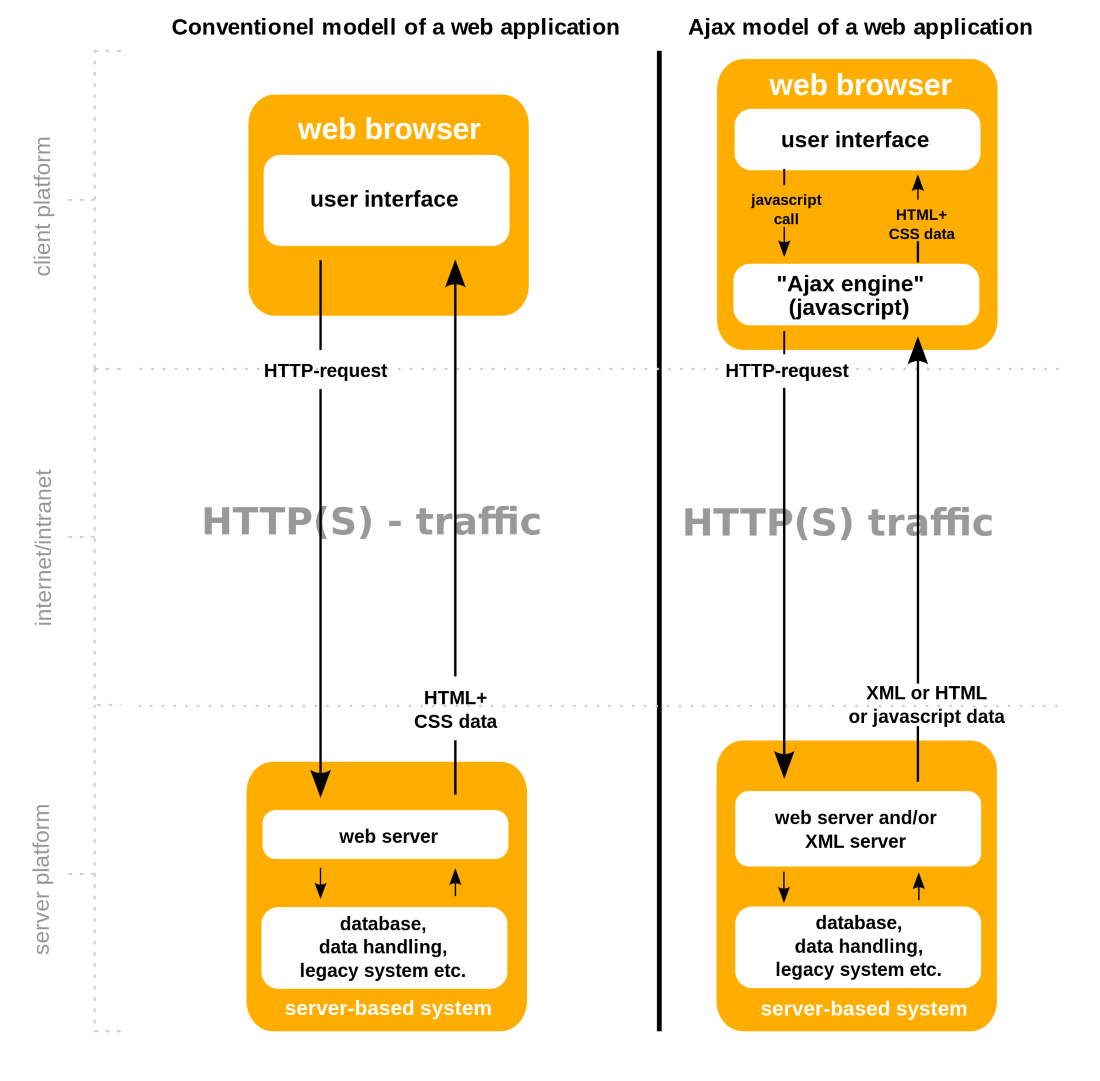
- Browser invia richiesta HTTP
- Web server contatta Database
- Web server compila HTML
- Web server fornisce HTML + CSS
AJAX page call
- Browser invia Javascript call
- Ajax engine interpreta la call e invia richiesta HTTP
- Web server contatta Database
- Web server fornisce JavaScript
- Ajax Engine interpreta risposta JavaScript
- Crea HTML + CSS
- Modifica il DOM
Il rendering lato client delle pagine, lo scambio asincrono dei dati, aggiornamenti dei contenuti senza un aggiornamento della pagina, la costruzione di un modello HTML – sono tutte cose utili che hanno portato questi framework in JS. Per questo motivo molti sviluppatori sono favorevoli ad utilizzare lo stack MEAN (Mongo, Express, Angular, Node), è relativamente semplice e rapido sviluppare prototipi di applicazioni avanzate. Però, se vuoi ricevere traffico organico, è importante creare con queste tecnologie una struttura accessibile agli spider dei motori di ricerca.
La cosa che mi stupisce è che alcuni sviluppatori web insistono a sviluppare siti web in AngularJS anche quando non è necessario, ad esempio per brochureware e siti web mono-pagina (FAQ, landing page, ecc).
Ricordati sempre che, in ogni caso, se crei un sito web con un framework JavaScript dovrai preventivare tempi duri e avrai bisogno di veri esperti nel team di progettazione e sviluppo per competere in SERP con siti web classici – almeno per ora.
Guarda questo sito, oppure questo, entrambi sviluppati in AngularJS. Il contenuto che vedi è reso in Javascript, e per questo motivo, se guardi il codice sorgente (CTRL+U in Google Chrome) vedrai un’insolitamente piccola quantità di HTML, molto meno di quanto ti aspetteresti guardando il risultato renderizzato. Ecco un esempio:
<!doctype html>
<html ng-app="ebsn" lang="it">
<head itemscope="" itemtype="http://schema.org/WebSite"><title itemprop="name">Tigros</title><meta charset="utf-8"><meta http-equiv="content-language" content="it"><meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1"><meta name="description" content="Tigros Drive è il nuovo servizio che permette di ordinare la spesa online e ritirala comodamente in uno de punti vendita Tigros attrezzati"><meta name="keywords" content="supermercato,spesa,online,casalinga,cibo,drive,auto,varese,casa,frigorifero,cucina,pranzo,cena,pendolare, spesa online, spesa online varese, ritiro spesa, ritiro spesa varese, drive varese, supermercato online"><meta name="Author" content="Digitelematica s.r.l."><meta name="viewport" content="width=device-width, user-scalable=no"><meta name="apple-itunes-app" content="app-id=1055600644"><meta name="google-play-app" content="app-id=it.digitelematica.ebsn.tigros"><meta name="fragment" content="!"><link rel="canonical" href="https://www.tigros.it/ebsn-shop/index.html" itemprop="url"><link rel="stylesheet" href="assets/icomoon/style.css"><link rel="icon" href="favicon.ico"><!--[if IE]><link rel="shortcut icon" href="favicon.png"><![endif]--><link rel="stylesheet" href="styles/vendor-56d25324cb.css"><link rel="stylesheet" href="styles/app-d476401f4f.css"></head>
<body device-detector=""><!--[if lt IE 10]>
<p class="browsehappy">Stai utilizzando un browser troppo vecchio. Per continuare la navigazione puoi <a href="http://browsehappy.com/">aggiornare il tuo browser</a> oppure utilizzare la <a href="https://www.tigros.it/ebsn/">versione tradizionale di questo sito</a>.</p>
<![endif]--><div ui-view=""></div>
<noscript class="browsehappy">Per utilizzare questo sito è necessario abilitare javascript</noscript>
<script src="scripts/vendor-890f01f39d.js"></script><script src="scripts/app-81e0eb286a.js"></script>
</body>
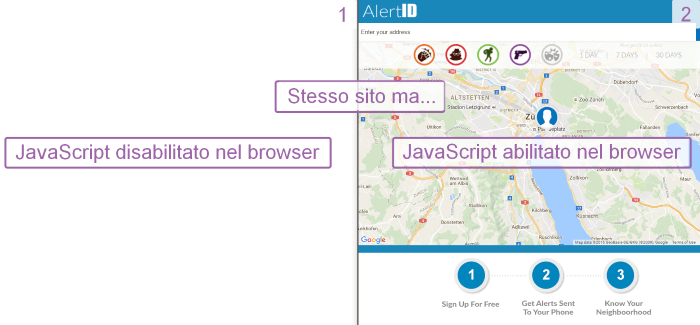
</html>Questo è tutto il contenuto che viene fornito agli spider da un sito in AngularJS, a volte ne troverai anche meno. È per questo che si ottiene la pagina vuota quando si visita il sito con JavaScript disabilitato nel browser. Il tag ng-app che trovi in apertura della pagina HTML crea la magia: indica ad AngularJs di manipolare il DOM.
ng-App: è una direttiva nel modulo ng di AngularJS che indica al framework quale elemento del DOM dovrà utilizzare come radice per la nostra applicazione. Nel caso mostrato sopra, il tag ng-App agisce sull’intera pagina (tag html) ma, più in generale, può essere inserita all’interno del tag o addirittura all’interno di un singolo div.
Fondamenti: quello che sappiamo su GoogleBot e JavaScript
Nell’ultimo anno Google ha fatto progressi migliorando le sue capacità di crawling di pagine web e siti sviluppati in Javascript. Essenzialmente Googlebot esegue il rendering delle pagine web come se fosse un browser.
Di seguito una dichiarazione di Aprile 2016 da parte di Paul Haahr, un ingegnere di Google, che dice chiaramente che la direzione del motore di ricerca è quella di interpretare contenuti JavaScript sempre meglio.And then, we also do content rendering. And this is something that Google has talked about a lot in the past couple of years. It’s new for us over the past few years. It’s a big deal for us that we are much closer to taking into account the JavaScript and CSS [28, 29, 30, 31, 32, 33] on your pages.
How Google Works – Paul Haahr (Software engineer at Google) at SMX April 2016

Nella citazione sono linkati alcuni articoli di approfondimento, nel link #29 Adam Audette descrive dei test di indicizzazione su Google eseguiti con redirect e link in JavaScript. Nei progetti che mi sono capitati ho potuto confermare le sue considerazioni, ritrovandomi con i medesimi risultati che descrivo nel prossimo paragrafo.
Redirect, link e tempi di esecuzione di JavaScript
I progressi di Googlebot nella gestione di redirect, link ed elementi in JavaScript sono rapidi e miglioreranno giorno dopo giorno. Dovendo fare un punto della situazione ad oggi possiamo dire quanto segue.
1. Googlebot segue i redirect in JavaScript
Googlebot considera i redirect JavaScript con la funzione window.location nello stesso modo di un redirect 301 dal punto di vista dell’indicizzazione, sia con URL assoluto sia con URL relativo.
2. Googlebot segue i link in JavaScript
Questo include URL associati con attributo href e inseriti all’interno della classica tag “a”, ed in alcuni casi anche esterni al tag “a”.
<!-- Funzioni «onClick» inserito nel tag «a» -->
<a href=“...” on-click=“funzione1()”>Link</a>
<!-- Funzioni «javascript:window.location» all’interno del tag «a» -->
<a href=“javascript:funzione1();”>Link</a>
<!-- Funzioni esterne al tag "a" ma chiamate all’interno di Attribute-Value Pair href (“javascript:openlink()”) -->
<div href=“javascript:funzione1();”> </div>
<div href=“http://pippo.pluto.com/aaa” on-click=“funzioneCheNavigaIlLink()”>Link</div>Sempre nell’articolo di approfondimento #29 – L’autore racconta che Googlebot ha scansionato URL che venivano generati dal sistema solo in seguito ad un onchange event handler che in questo caso era il movimento del mouse (onmousedown e onmouseout). Sempre nello stesso test l’autore dichiara di aver notato Googlebot seguire URL generati dall’esecuzione di variabili in JavaScript. Nell’esempio aveva concatenato una stringa di caratteri che generava un URL soltanto una volta eseguita.
Personalmente non ho eseguito test di questo tipo, in genere ho notato che Googlebot non esegue eventi che non siano link.
3. Contenuto generato dinamicamente
Googlebot è in grado di indicizzare meta tag (title e description), immagini e contenuto testuale inserito dinamicamente in una pagina HTML (funzione document.writeIn), sia che i contenuti risiedano sulla stessa pagina HTML sia su un file JavaScript esterno. E’ importante non bloccare questi file con il robots.txt.
4. Googlebot non esegue tutti gli eventi
Nonostante gli evidenti miglioramenti di Google nello scansionare pagine in JavaScript, è ancora necessario manipolare gli URL per farli diventare dei veri e propri link dentro il tag “a”. Google infatti è in grado di interpretare elementi di layout ed elementi comuni di una pagina web, ma non prova ad eseguire gli eventi in JavaScript per vedere cosa succede. Per gestire gli URL è necessario fornire a Googlebot un link “classico” da seguire. Utilizzando altri metodi si rischia che Googlebot ignori quegli elementi, oppure addirittura smetta del tutto di scansionare la pagina.
5. Googlebot ha un tempo massimo di attesa per eseguire JavaScript
Sembra che Googlebot non indicizzi i contenuti che impiegano più di 4 secondi per essere renderizzati, oppure contenuti che richiedono l’esecuzione di un evento attraverso un link esterno al tag a (vedi punto precedente).
Il vecchio schema di Scansione AJAX (deprecato)
Il 14 Ottobre 2015, Google annunciò che lo schema di scansione che Googlebot utilizzava con AJAX era diventato obsoleto, stavano deprecando la vecchia “Direttiva Crawl AJAX”. E’ stato poi notato che, nonostante questo annuncio, Google rispetta ancora tutt’oggi la vecchia direttiva.
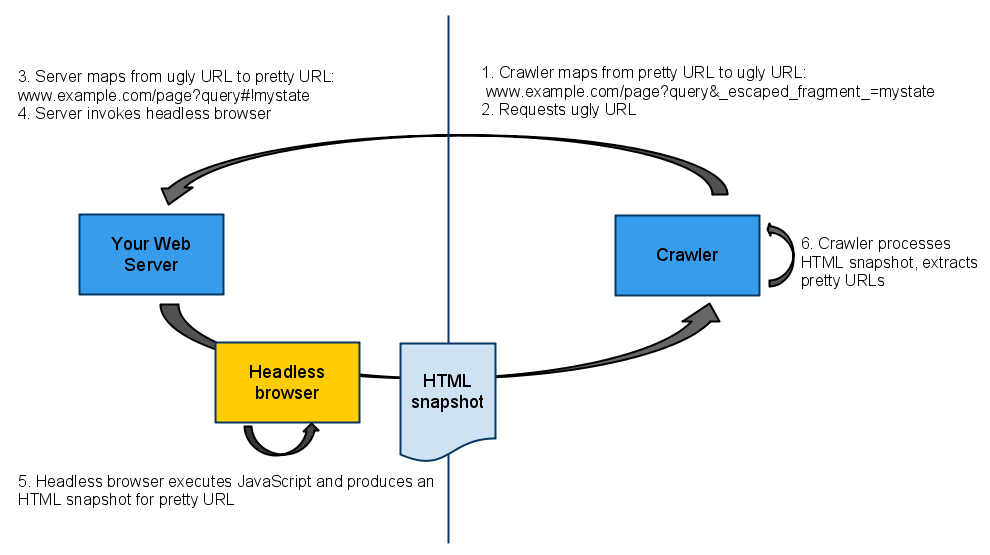
Processo e spiegazione |
Esempio URL |
| 1. URL definito stateful, ovvero il formato di URL che viene generato dal framework JS senza alcuna ottimizzazione. L’hash, il cancelletto, però secondo gli standard HTML indica un’ancora interna. | http://esempio.it/chi-siamo.html#state |
| 2. Google e Bing propongono di aggiungere il FRAGMENTTOKEN (!) dopo hash (#) per riconoscere il contenuto in JS e non andare contro lo standard HTML. Il nuovo URL generato viene definito Pretty URL | http://esempio.it/chi-siamo.html#!AJAX |
3. I motori di ricerca mappano i Pretty URL nell’indice, ma in fase di crawling richiedono al web server gli Ugly URL, ovvero sostituiscono l’hashbang #! con ? _escaped_fragment_ = in modo da ottenere la pagina pre-renderizzata | http://esempio.it/chi-siamo.html?_escaped_fragment_=AJAX |
| 4. Quando il web server riceve la richiesta per un Ugly URL attiva un headless browser che renderizza la pagina JS e crea una istantanea HTML completa da fornire agli spider (con lo stesso DOM che avrebbe una pagina renderizzata da un browser client). I motori di ricercano indicizzano sul Pretty URL il contenuto ricevuto dagli Ugly URL | http://esempio.it/chi-siamo.html#!AJAX |
Importante: se stai lavorando ad un sito che utilizza il parametro ? _escaped_fragment_ =, assicurati che la funzionalità di rendering stia lavorando bene.
Come vedi dallo schema la vecchia direttiva di crawling richiedeva il pre-rendering delle pagine. Ora Google dice in pratica che possiamo anche farne a meno.
Ci pensa lui a renderizzare, dice…
Possiamo stare sereni allora? No, non direi. Il pre-render, a mio parere, è qualcosa che ci serve per svariate ragioni.
Il redering server side è un must
Fornire agli spider dei motori di ricerca degli snapshot HTML pre-renderizzando le pagine secondo me è la scelta migliore alla data in cui scrivo. Faccio spesso riferimento ad oggi – Dicembre 2016, perché domani i MdR saranno molto più efficienti in questo campo.
Google può renderizzare e scansionare siti JS? Si, o almeno ci prova. Questa, tuttavia, non è una garanzia che il risultato sia SEO friendly, ovvero un sito web perfettamente ottimizzato. E’ necessaria la competenza tecnica di un SEO, in particolare durante i test di implementazione. Questo farà sì che il sito sia scansionato correttamente da Googlebot, abbia una struttura corretta e che i contenuti siano scritti con le giuste parole chiave. Le finanze aziendali ringrazieranno, infatti i costi saranno minori rispetto ad una corsa ai ripari.
Gli altri motori di ricerca possono renderizzare e scansionare siti JS? Potrei dire NI, ma preferisco dire NO. Il tuo mercato di riferimento è Russia e vivi di traffico da Yandex? Renderizza o muori. Il traffico da Baidu è prezioso per te? Renderizza o muori. Bing? Già meglio, ma non ai livelli di Google, renderizza o muori.
Renderizzo o no le mie pagine? Per evitare problemi di indicizzazione, credo che sia meglio mantenere il controllo totale di quello che viene “renderizzato”, servendo Google degli snapshot HTML, ovvero una versione pre-renderizzata e compilata delle tue pagine. In questo modo potrai applicare tutte le regole classiche della SEO e sarà più facile rilevare e diagnosticare eventuali problemi durante i test. Inoltre ricordati che in questo articolo parliamo di Google, il motore di ricerca più avanzato, gli altri motori di ricerca ottengono risultati nettamente inferiori nel rendering di JS.
E poi… io guardo spesso come fanno gli altri, “quelli bravi”, e la maggior parte dei siti web più importanti sviluppati con AngularJS (non dico tutti per non sembrare banale, ma fai come se lo avessi detto) usano una funzione di rendering server side, facciamoci una domanda e diamoci una risposta.
Vantaggi del pre-rendering:
- Meglio avere il controllo totale di quello che viene “renderizzato”, servendo a Google degli snapshot HTML
- Sugli SNAPSHOT HTML si lavora alla SEO in modo classico
- Dovrebbe essere più facile rilevare e diagnosticare eventuali problemi durante i test SEO
- Ricorda: Google ha le potenzialità per renderizzare JS, ma gli altri MdR arrancano
4 approcci differenti alla SEO con AngularJS
Per ottimizzare la scansione e l’indicizzazione di un sito web sviluppato con AngularJS ci sono 4 alternative, le spiego in ordine dalla più elegante alla più semplice.
1. Pre-rendering con PhantomJS – il metodo più elegante
- Genera istantanee delle tue pagine utilizzando PhantomJS (un headless browser) e crea un livello di cache personalizzato
- Non usare
#!negli URL - Non usare
escaped_fragmentnegli URL - Assicurati che ogni pagina abbia un Friendly URL con le HTML5 History API (quindi senza
#!) - Inserisci tutti i Friendly URL in una sitemap.xml ed inviala a GSC
- Invece di servire le istantanee quando il parametro
? _escaped_fragment_ =è incluso nel URL richiesto, servi l’istantanea HTML quando viene richiesto il Friendly URL (canonico) della pagina da un user-agent dei motori di ricerca, come ad esempio GoogleBot - Gli utenti (browser) ricevono la pagina senza pre-rendering
- Implementa correttamente la tag rel canonical
Il sito web redbullsoundselect.com segue questa tecnica alla data in cui scrivo.
2. Continua con la vecchia direttiva di crawling
- Mantieni il parametro
? _escaped_fragment_ =per fornire le istantanee renderizzate. Googlebot sta ancora elaborando le richieste di questo parametro - Gli utenti (browser) ricevono la pagina senza pre-rendering sul Pretty URL (con hashbang)
- Fornisci a Google Search Console una sitemap.xml con tutti i Pretty URL (con hashbang)
- Implementa correttamente il tag rel canonical (con hashbang)
3. Lascia renderizzare Google – il metodo «alla spera in DIO»
- Fai renderizzare AngularJS da Google, senza nessun tipo di pre-rendering e vedi cosa succede. Gli altri motori di ricerca si dispiaceranno
- Usa le HTML5 history API per togliere l’hashbang dall’URL visibile nel browser, e fornisci a Google Search Console la sitemap.xml con tutti i Friendly URL (canonici). La maggior parte degli sviluppatori concorda sul fatto che non sia il massimo avere l’hashbang negli URL, aggiunge complessità alla SEO di un sito
- Se non vuoi usare URL con hashbang ma vuoi informare Google che il tuo sito contiene AJAX allora devi usare la direttiva
ng-appdi AngularJS
4. Anglar 2.0
- Non sviluppare niente in AngularJS 1.x
- Passa direttamente ad Angular 2.0. Angular 2.0 include nativamente funzioni di server rendering, con risultati simili a quelli ottenuti con React
- Per approfondire leggi questa guida
Come rendere SEO Friendly un un sito in React: Per iniziare puoi leggere questa guida. Le scelte rimangono bene o male le stesse, fornire il contenuto pre-renderizzato ai motori di ricerca e utenti. Personalmente non ho provato, ma ho letto che viene usato webpack oppure Browserify per modificare JS in moduli npm ed eseguirlo sul server e sul client. L’alternativa è lasciare che Googlebot indicizzi il sito per conto suo.
Sia che tu decida di usare ? _escaped_fragment_ = o meno, ci sono molte altre cose di cui tenere conto ed il lavoro sarà lungo e complesso. Per questo motivo consiglio di usare ReactJS oppure Angular 2.0 Universal, dato che hanno funzionalità di server rendering già incluse. Guarda il video di presentazione.
Phantom.js e Prerender.io
PhantomJS consente di compiere operazioni che normalmente vengono fatte con un browser, senza però mostrare il browser stesso. Si tratta infatti di un cosiddetto headless browser, cioè di un tool che consente la manipolazione via JavaScript del DOM, di CSS, JSON, Ajax altre tecnologie Web client-side da riga di comando, senza alcun rendering a video.
Basato su WebKit, PhantomJS è uno strumento multipiattaforma e può essere utilizzato in tutti quei contesti in cui si ha bisogno di automatizzare le tipiche attività di un Web browser, ma non solo. Per fare qualche esempio, esso può essere utilizzato per attività di Web scraping, per l’automazione di test su siti ed applicazioni Web, per il monitoraggio di rete, ma anche per il rendering in SVG, l’interfacciamento con servizi Web ed addirittura per la creazione di un semplice Web server.
Il server di PhantomJS deve essere installato nella stessa macchina che ospita il web server, lavora su una porta differente. In alternativa esistono servizi esterni di rendering con PhantomJS, come ad esempio Prerender.io. Questo servizio a pagamento (gratis fino ad un massimo di 250 pagine in cache) è particolarmente utile quando il web server non riesce a gestire il rendering di molte pagine con tempi di risposta accettabili.
Hashbang o no?
E’ molto importante per un SEO capire come può aiutare i motori di ricerca a scansionare siti web dipendenti da JavaScript. Se raggiungi questo obiettivo, sei un bravo SEO tecnico. Come abbiamo visto all’inizio, sia Google che Bing supportano una direttiva che consente agli sviluppatori Web di fornire istantanee HTML del contenuto in JS, attraverso una struttura di URL modificata.
In particolare mi riferisco al parametro hashbang che i motori di ricerca sostituiscono con ? _escaped_fragment_ = in un URL.
Ripeto il processo perché è critico comprenderlo.
Immagina di avere URL con hashbang nel tuo sito in Angular:
http://esempio.com/#!/1/2/3/products/contentLo spider di un motore di ricerca riconosce l’hashbang ed automaticamente richiede al web server l’URL con ? _escaped_fragment_ =:
http://esempio.com/?_escaped_fragment_=/1/2/3/products/contentIl web server riconosce la richiesta dei motori di ricerca dato che solo loro richiedono URL con ? _escaped_fragment_ = e fornisce lo snapshot pre-renderizzato della pagina, il file HTML pre compilato. Ovviamente devi assicurarti che il pre-rendering funzioni correttamente sul tuo web server, e questo di solito non accade per caso ;)
La maggior parte degli sviluppatori con cui mi sono confrontato usa PhantomJS per renderizzare le pagine in AngularJS.
Se riesci a renderizzare correttamente le tue pagine come HTML, l’unica cosa che ti rimane da verificare è che tutte le richieste contenenti ? _escaped_fragment_ = vengano dirottate nella directory di cache del tuo web server.
Non voglio usare l’hashbang nel mio sito in Angular
Guarda nel tag head del sito della Redbull che ho linkato sopra – https://www.redbullsoundselect.com/ vedrai una nuova meta tag, sconosciuta a chi non ha mai lavorato con Angular, una meta tag fondamentale se non usi l’hashbang.
<meta name="fragment" content="!" />Scorri le altre meta tag, non ti verrebbe da pensare che con tutte quelle parentesi graffe sia più un disastro che altro? Ti sbagli, quelle parentesi graffe verranno riempite da JS con codice HTML. Lo sviluppatore di questo sito è stato molto bravo, ha impostato gli URL senza hashbang, e per avvertire i motori di ricerca ha inserito la “meta fragment” nel tag head. Il tag fragment invita gli spider dei motori di ricerca a richiedere lo snapshot HTML sull’URL con il parametro ? _escaped_fragment_ =.
Nota: Per generare Friendly URL (URL senza hashbang) usa il servizio AngularJS $location e le HTML5 History API.
Canonical tag
Il tag rel Canonical andrebbe inserita sempre, qualsiasi setup tecnico tu scelga. La cosa importante è che se decidi di usare questa tag, assicurati che sia corretta. Indicare l’URL errato nel tag Canonical potrebbe pregiudicare l’indicizzazione dell’intero sito web.
Nel tag rel Canonical inserisci i Pretty URL, ovvero gli URL usati dagli utenti e visibili nel sito.
Ricordati: i Pretty URL sono indirizzi con:
Hashbang- Friendly URL nel caso tu abbia usato le HTML5 history API per riscrivere gli URL senza
#!
Non inserire mai URL con ? _escaped_fragment_ = nel tag rel Canonical ed in Sitemap.xml. Un altro errore comune da evitare è quello di indicare sempre la homepage nel tag Canonical.
Impostare l’ambiente AngularJS
Per configurare l’ambiente di sviluppo puoi usare Yeoman, un tool per fare scaffolding di applicazioni, che è una soluzione all-in-one per sviluppare e testare applicazioni AngularJS. Apri il terminale e digita:
mkdir testangular
cd testangular
yo angularNota: ho usato il nome “testangular” per la cartella, ma puoi assegnare il nome che preferisci.
Attendi che il processo di setup incominci, rispondi alle varie domande che il sistema ti propone, scegli se includere Bootstrap e uno qualsiasi degli altri moduli AngularJS. Una volta che è terminato il processo, avrai un ambiente di sviluppo configurato. Dal terminale digita grunt server e dovrebbe aprirsi il browser con il template di default di Yeoman. Da qui puoi iniziare a creare una SPA (Single Page Application), ma andiamo oltre per creare lo snapshot HTML della pagina AngularJS.
Ti serve un metodo per dire agli spider dei motori di ricerca di richiedere le pagine pre-renderizzate, a questo fine puoi usare un pacchetto SEO per AngularJS già sviluppato.
git clone https://github.com/steeve/angular-seo.gitNella cartella trovi due file importanti:
- angular-seo.js, che deve essere inserito nella cartella “/testangular/app”
- angular-seo-server.js, che deve essere inserito nella cartella “/testangular” oppure nella root della tua applicazione (la cartella che contiene il file Gruntfile.js)
Nota: Nel repository di GitHub trovi le istruzioni complete.
Il setup deve fare in modo che il sistema utilizzi due porte:
- Application port: per gestire l’applicazione
- Snapshot port: per gestire l’istanza dell’applicazione su PhantomJS
Le richieste da non-bots vengono servite dall’Application port (non importa quale), mentre le richieste da bots e motori di ricerca vengono servite, in HTML pre-renderizzato, dalla Snapshot port. I prossimi passaggi sono:
- dire all’applicazione di abilitare l’indicizzazione da parte degli spider
- includere il modulo SEO
- dire all’applicazione di avvertirti quando ha terminato il rendering
- installare ed eseguire PhantomJS
- notificare i motori di rcerca inserendo nella pagina index.html il meta tag fragment, vedi sopra, gli spider cercheranno lo snapshot HTML sugli URL con
? _escaped_fragment_ =
A questo punto apri il file app.js e trova l’inclusione del modulo all’interno della dichiarazione. In qualsiasi modo tu decida di farlo, hai bisogno di includere il modulo SEO inserito nel file angular-seo.js (che abbiamo inserito nella cartella testangular/app. Ad esempio, la dichiarazione ha questo aspetto:
angular.module('myApp', [
'ngCookies',
'ngResource',
'ngSanitize',
'ngRoute',
'seo'
])
.config(function ($routeProvider) {
$routeProvider
.when('/', {
templateUrl: 'views/main.html',
controller: 'MainCtrl'
})
.when('/about', {
templateUrl: 'views/about.html',
controller: 'MainCtrl'
})
.otherwise({
redirectTo: '/'
});
});Ora devi definire come viene renderizzato l’HTML richiamando la funzione $scope.htmlReady(), in un punto in cui sei certo che la pagina HTML abbia finito di caricare. Dipende come hai organizzato i tuoi controller, ma in genere viene fatto alla fine del controller principale (main controller). Ad esempio, con il controller incluso in Yeoman, il file main.js appare così:
'use strict';
angular.module('giovanniApp')
.controller('MainCtrl', function ($scope) {
$scope.awesomeThings = [
'HTML5 Boilerplate',
'AngularJS',
'Karma'
];
// SEO REQUIREMENT:
// PhantomJS pre-rendering workflow requires the page to declare, through htmlReady(), that
// we are finished with this controller.
$scope.htmlReady();
});Infine devi includere il file angular-seo.js nel tuo file index.html file, verso il fondo, dove è corretto inserire i controller:
<script src="scripts/app.js"></script>
<script src="scripts/controllers/main.js"></script>
<script src="angular-seo.js"></script>Hai terminato il setup dell’applicazione, ora installa e imposta PhantomJS.
Da riga di comando digita npm install phantomjs. Una volta finito il processo di installazione naviga nella root directory (la cartella che contiene i file angular-seo.js e angular-seo-server.js) ed esegui questo comando:phantomjs --disk-cache=no angular-seo-server.js 9090 http://127.0.0.1:9000
Il comando attiva il server di PhantomJS senza disk caching (per ora accontentati^^), attivo sulla porta 9090. La porta usata da PhantomJS deve essere necessariamente diversa dalla porta usata dalla tua applicazione. La porta è impostata nel “grunt file” nativo di Yeoman. In altre parole, yo angular offre l’opzione di lanciare un grunt server, il quale imposta un web server su localhost per testare l’applicazione sulla porta 9000.
- PhantomJS gira sulla porta 9000 ed ascolta le richieste sulla porta 9000
- quando le richieste contengono
?_escaped_fragment=al posto dell’hashtag, PhantomJS pre-renderizza la pagina e la serve al richiedente, che è un crawler. - quando le richieste contengono URL con hashbang significa che il richiedente è un umano (browser) quindi si bypassa PhantomJS.
Ora che PhantomJS è attivo, lancia il server di sviluppo grunt server.
- Il server di sviluppo ha indirizzo 127.0.0.1 con porta 9000 (oppure localhost, dipende come preferisci chiamarlo)
- un secondo web server con porta 9090 ascolta le richieste sulla porta 9000 per identificare il traffico proveniente dai crawler
Prima di andare live assicurati che funzioni correttamente l’identificazione di richieste di URL con ? _escaped_fragment_ = in modo che vengano girate su PhantomJS. Gli URL con ? _escaped_fragment_ = non devono essere serviti dal server principale in ascolto sulla porta 80. Su Nginx puoi usare questa regola:if ($args ~ escaped_fragment) { # Proxy to PhantomJS instance here }
Testare e validare le implementazioni
Una volta che avrai testato e validato il pre-rendering con un crawler, potrai passare alla modalità “SEO classica”, ottimizzando i soliti aspetti di un sito in HTML che già conosciamo. Prima però devi verificare che il pre-rendering funzioni perfettamente. Per il test puoi usare la riga di comando e lanciare (se sei in locale):
curl 'http://localhost:9090/?_escaped_fragment_=
Il web server dovrebbe mostrarti lo snapshot HTML della homepage (indirizzo “/”). In alternativa procurati un crawler ed installa Google Search Console. Gli strumenti necessari sono pochi ma fondamentali:
- Usa Fetch As Google
- Controlla la cache di Google
- Usa Google Search Console
- Scansiona il sito con un crawler JS friendly
Come ripeto sempre: “per fortuna c’è Screaming Frog”, un crawler capace di scansionare anche le pagine in AJAX. Il crawler AJAX rispetta le direttive AJAX, questo significa che ogni volta che troverà un hashbang, richiederà l’URL con ? _escaped_fragment_ = – da Pretty URL a Ugly URL per ottenere la pagina renderizzata dal web server. Per scansionare un sito con Screaming Frog scarica la sitemap.xml (come la trovo?) ed inseriscila in modalità lista. Il crawler emula il comportamento degli spider dei motori di ricerca: trova l’hasbang e richiede la varsione Ugly URL per avere la pagina HTML pre-renderizzata dal web server.
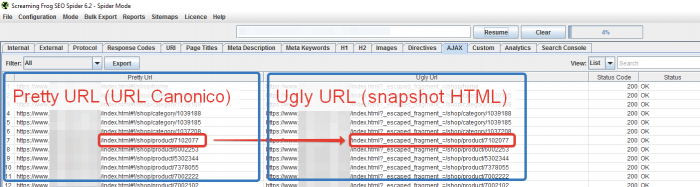
Per una guida completa in Italiano di Screaming Frog ti rimando qui.
Assicurati che gli URL con ? _escaped_fragment_ = rispondano status code 200. Come detto precedentemente, il problema principale con questo framework è gestire la funzionalità di pre-rendering.
Supersegreto
La SEO tecnica non è tutto. Ora che hai un sito web sviluppato in AngularJS perfettamente ottimizzato per i motori di ricerca devi riempirlo di contenuti unici di qualità. Un sito tecnicamente perfetto ma senza contenuti è come una macchina da corsa senza benzina!
Risorse e approfondimenti
Questa guida ha richiesto molto tempo per essere scritta ed è qui per te, gratuitamente. Se pensi che possa essere utile ai tuoi colleghi o amici, condividila sui social e lascia un commento. L’autore ringrazia;)
Articoli correlati
Autore

Mi chiamo Giovanni Sacheli e dal 2009 aiuto le aziende a farsi trovare online. Sono specializzato in SEO tecnica e PPC, competenze che applico quotidianamente nella mia agenzia, Searcus Swiss Sagl. Mi piace sviluppare strumenti a supporto del mio lavoro, ho creato SEOdata.app e cluster.army e co-scritto il libro SEO Audit Avanzato. Curo maniacalmente questo blog per colleghi e appassionati, dove mi "appunto" quello che imparo. Sono un NERD anni '80, motociclista e orgoglioso papà di due bambini.
Link:
Giovanni Sacheli
SEO Audit Avanzato
Searcus Swiss Sagl
SEOdata.app
cluster.army
Commenti |16
Lascia un commentoComplimenti Giovanni, articolo approfondito, interessane e ben strutturato.
Grazie mille Carmine!
Grazie per l’articolo. Negli ultimi mesi ho letto una buona metà delle fonti elencate a fine articolo e mi sono ritrovato perfettamente in quanto da lei ottimamente riassunto. Mi permetto di condividere la mia esperienza lato server con NodeJS dove ho utilizzato “Horseman” come modulo basato su PhantomJS per renderizzare le pagine da salvare su server e dare in pasto agli spider. Inizialmente ho utilizzato il servizio offerto da prerender.io, ma non è andata esattamente come speravo. Grazie ancora.
Grazie Alberto per aver codiviso la tua esperienza. Devo approfondire il discorso PhantomJS perché solo una minima parte lo consigliava e per il momento lo avevo lasciato indietro. Grazie ancora e buon lavoro.
Ottimo articolo, grazie per l’approfondimento di questo aspetto SEO ancora poco conosciuto ma fondamentale per chi se ne occupa!
Grazie mille Andrea, é prezioso il vostro supporto :)
Ciao,
l’articolo è molto interessante, ma credo che sarebbe necessario valutare diversi punti di vista anche in relazione a quello che sarà il futuro.
Google e gli altri motori di ricerca si stanno muovendo sempre più attivamente per non penalizzare i siti web con client-side rendering. Ed il motivo è che dal punto di vista della velocità e della UX le web app client-side vanno molto meglio e sono più performanti. Google, così come Bing, ecc. tengono molto a dare all’utente finale un’ottima esperienza ed in questi anni si stanno già muovendo per avere un futuro client-side rendered. Chi crea una piattaforma oggi (nel momento in cui scrivo manca poco al 2018) rischia di ritrovarsi tra un anno con qualcosa che Google reputa vecchio e “lento”.
In ogni caso, l’articolo è ben scritto e ti faccio i complimenti. Il mio è un punto di vista, ma non parto con il presupposto di aver ragione per forza :)
Ciao Paolo grazie del commento :) Ovviamente fai bene ad esprimere la tua opinione, anche se diversa da quanto consigliato nell’articolo.
Per esperienza posso dirti che ancora oggi molti team che hanno sviluppato portali in Angular o React stanno cercando di passare al server rendering perché i siti non vengono ancora indicizzati correttamente e come desiderato. Era così nel 2016, è stato così nel 2017 e sarà così nel 2018. I tempi che prevedi tu sono, a mio parere, ancora lontani.
Investire in un progetto JS oriented senza definire un sistema di rendering server side è, secondo me, ancora troppo immaturo e si rischia di fare un grande flop.
Che poi la strada intrapresa da Google sia quella che descrivi lo sappiamo, è stato detto più e più volte, ma tra il dire e il fare c’è di mezzo il mare :) Ci vuole pazienza.
A presto!
Grazie, una guida davvero esauriente come se ne trovano poche. Complimenti 👏
Grazie Mirko!
Articolo davvero esauriente, detto da uno che sta iniziando a tuffarsi nel mondo di Angular! Grazie!
Grazie Salvatore, è un ambiente molto interessante Angular. A presto!
Grande Articolo. Ha risposto a tutte le mie domande ed anche di più. Complimenti per la preparazione e la professionalità.
Grazie mille Stelvio
PS: gran passo ;)
Ciao Giovanni, intanto complimenti per l’articolo davvero interessante e grazie per la condivisione della tua conoscenza ed esperienza.
Ho acquistato il tuo libro “Seo Audit Avanzato” nel quale si parla proprio di queste tematiche. Precisamente si tratta del capitolo 6.
La mia domanda è questa: al grafico 6.1 (pag. 186) in corrispondenza di Google e Angular 2 c’è una bella “X”. Rispetto a quanto esposto nell’articolo come si deve leggere il grafico? Un sito costruito con Angular 2 non viene interpretato da Google? Se SI, con un pre-rendering servito a Googlebot in ogni caso si risolverebbe il problema? Ti ringrazio anticipatamente per la risposta.
Ciao Dario, grazie del commento e per aver acquistato il libro :)
Nel grafico in pagina 186, la X su A2 significa che nativamente questo framework fa fatica ad essere interpretato da Google.
Una soluzione, come spiegato nelle pagine seguenti, è usare il prerendering (totale, dinamico oppure parziale).
A presto e buon lavoro!