Quante volte ti sei chiesto (o ti hanno chiesto) se un sito web è ben indicizzato su Google? Leggi questa guida, alla fine sarai in grado di rispondere con numeri e dati alla mano.
In questa guida ti mostro il processo che seguo per valutare lo stato di indicizzazione di un sito web e alcuni rapporti che mi è utile calcolare quando inizio un SEO audit.
Premesse
Prima di tutto faccio chiarezza su un punto importante ma spesso non compreso: essere indicizzato NON vuol dire essere in prima pagina.
Una pagina web indicizzata significa che è presente nell’indice di Google, a prescindere dal suo ranking (posizionamento nei risultati di ricerca). L’indicizzazione è la seconda fase del processo che segue una pagina web prima di ricevere traffico organico:
1. Scansione (guida) > 2. Indicizzazione (guida) > 3. Posizionamento (guida).
Oggi ti mostrerò un metodo pratico per valutare lo stato di indicizzazione di un sito web su Google. Lo stesso metodo può essere usato anche per Bing, Yahoo e Yandex.
Per proseguire devi reperire qualche dato che puoi ottenere da una scansione con Screaming Frog (guida) e da Google Search Console – GSC (guida).
In dettaglio i dati che ci interessano sono:
- Numero totale di pagine date ai motori di ricerca, ovvero pagine totali del sito web che devono (o dovrebbero) essere indicizzate.
- Crawl budget, ovvero il numero di pagine scansionate giornalmente da Googlebot.
- Numero di pagine indicizzate da Google.
- Numero di pagine inserite in sitemap.xml.
Vediamo come reperire queste informazioni.
Pagine indicizzabili del sito web
Per trovare questo valore è necessario fare una scansione del sito web con un crawler come Screaming Frog o Visual SEO.
L’obiettivo è trovare tutte le pagine che Google indicizzerebbe del sito web, per trovarle lancia una scansione e usa il report HTML in Screaming Frog. Conta le pagine con status code 200, canoniche e con meta robot index (implicita, non serve dichiararla).
Le pagine devono essere canoniche di loro stesse. Le pagine canonicalizzate non vengono indicizzate, pertanto non vanno conteggiate.
Le pagine noindex oppure con status code di errore (4xx, 5xx) o di redirezione (3xx) devono essere ignorate per le finalità di questa guida, dato che non verrebbero indicizzate.
Formula: pagine HTML con status code 200, canoniche di loro stesse e senza meta robots noindexCrawl budget – numero di pagine scansionate giornalmente da Googlebot
Il numero di pagine scansionate ogni giorno da Googlebot è un valore molto interessante perché ci permette di capire la reputazione del sito web agli occhi del motore di ricerca.
Senza dilungarmi in tematiche già trattate posso riassumere che:
- poche scansioni: sito poco aggiornato, poco autorevole
- molte scansioni: sito aggiornato di frequente e con buona authority online
Per maggiori informazioni ti segnalo la guida per aumentare il Crawl Budget.
Il valore lo trovi in GSC > Crawl > Crawl Stats (Scansione > Statistiche di scansione). Nel nuovo GSC il report è sotto Legacy tools and reports > Crawl stats. In italiano invece lo trovi in Strumenti e rapporti precedenti > Statistiche scansione.
Fai riferimento al valore medio giornaliero se il trend è stabile, se invece il trend è in crescita o in declino puoi usare la media degli ultimi 15 giorni.
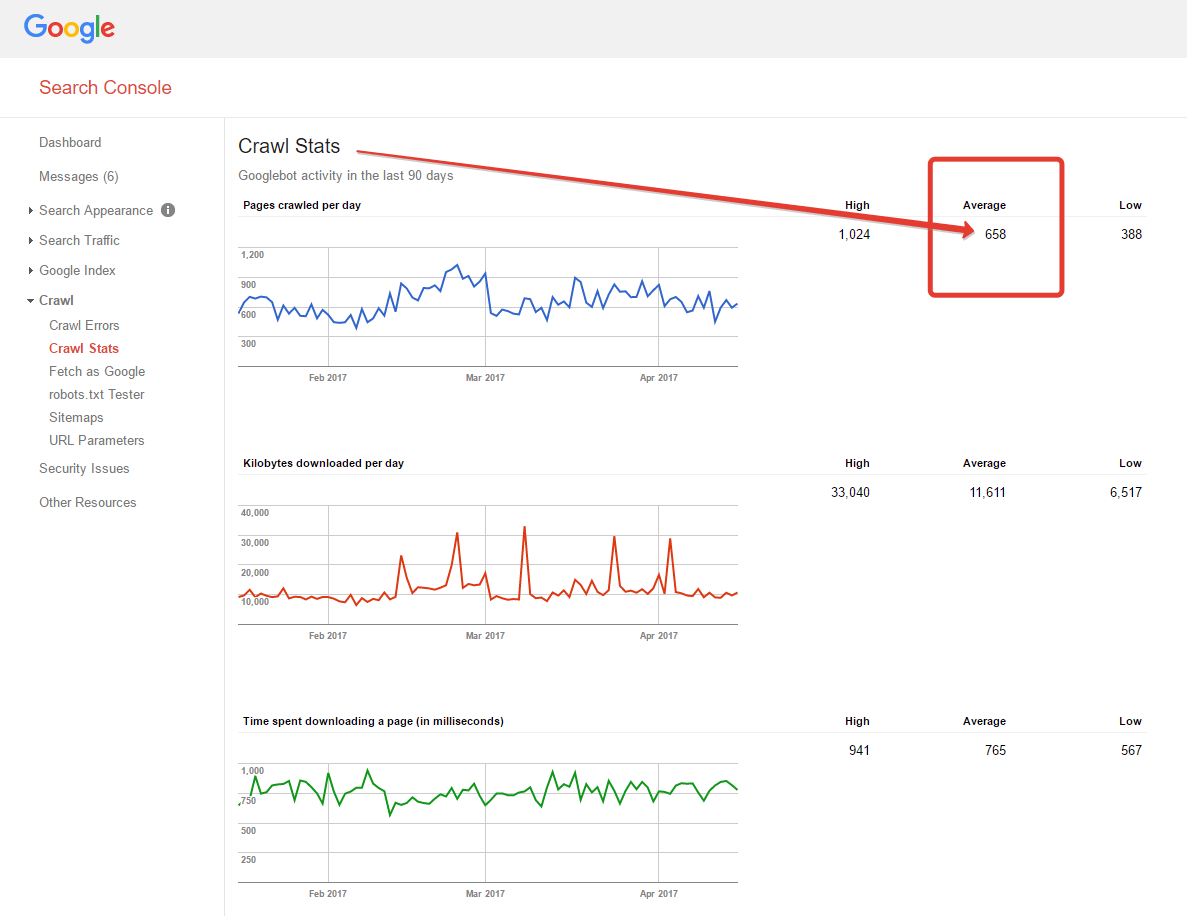
Per ottenere dati più precisi ti consiglio un’analisi del log del web server. Per siti di grosse dimensioni serve tempo a processare il log, ma si ottengono dati più ricchi e precisi rispetto all’approssimazione dei dati forniti da GSC.
Numero di pagine indicizzate da Google
Il numero di pagine indicizzate è reperibile in due modi, ciascuno con pregi e difetti:
- Tramite l’operatore di ricerca site: – valore approssimativo aggiornato di frequente e cambia in base al datacenter interrogato
- Tramite GSC – valore più preciso ma non aggiornato di frequente
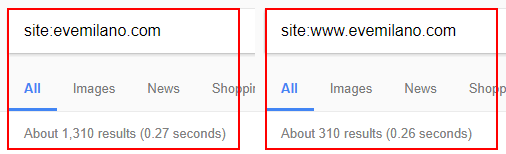
Per usare l’operatore di ricerca vai su Google e digita site:www.tuosito.com. Fai attenzione ad inserire il sottodominio corretto: se il sito usa www devi usarlo anche tu nell’operatore, altrimenti vedresti i dati di indicizzazione di tutti i sottodomini (se ce ne sono).
Il valore lo trovi in GSC > Google Index > Index Status (Indice Google > Stato dell’indicizzazione).
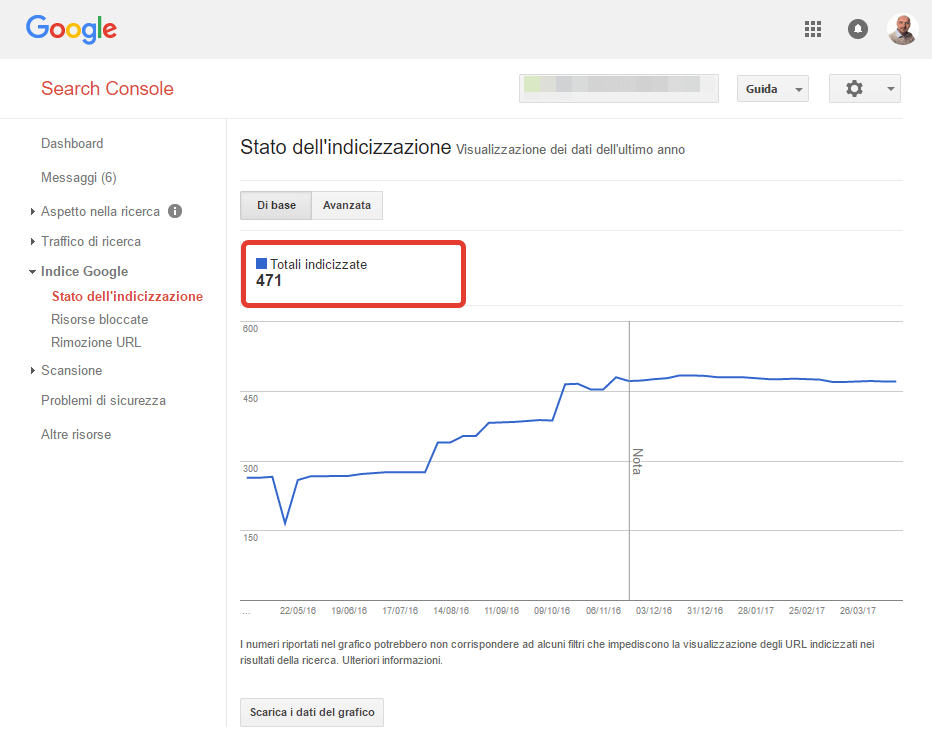
Nel nuovo GSC il report si chiama Coverage o Copertura in italiano. Il valore che ci interessa è la somma dei valori indicati sotto Valid e Valid with warnings.

Formula: Submitted and indexed + Indexed, not submitted in sitemap + Valid with warningsNumero di pagine inserite in sitemap.xml
Per sapere quanti URL vengono passati a Google tramite la sitemap.xml si può usare GSC > Crawl > Sitemaps (Scansione > Sitemap). Prendi nota del valore pagine web inviate.
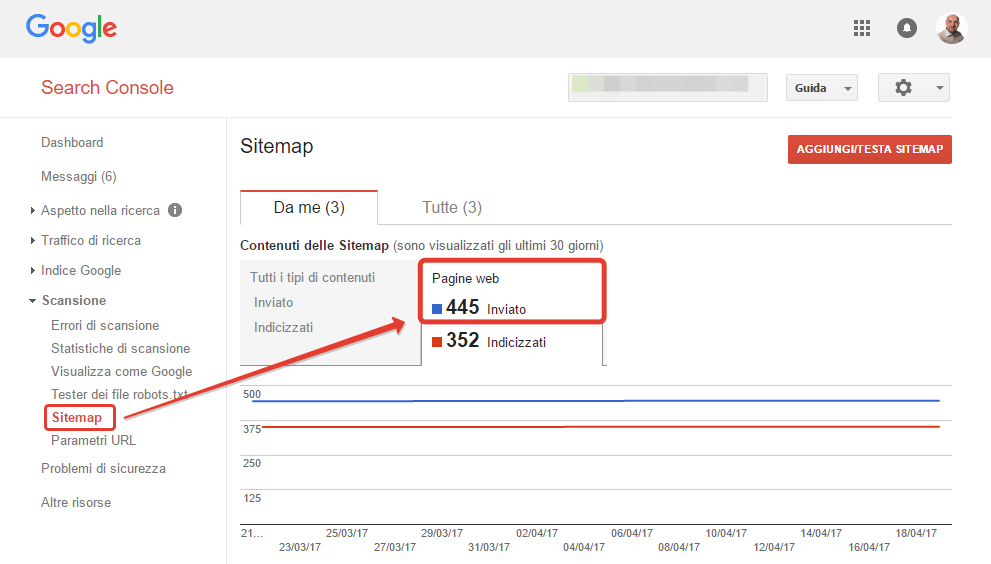
In GSC nuovo la sezione dedicata alla sitemap.xml è linkata direttamente dal menu nella sidebar a sinistra, sotto il gruppo Index/Indice.

Per il conteggio degli URL indicizzabili presenti in sitemap.xml puoi anche usare il report Coverage e filtrare con la tendina i soli URL inviati dalla sitemap.xml.
In alternativa puoi inserire la sitemap.xml in Screaming Frog (modalità lista), avviare la scansione e vedere quante pagine con status code 200, index e canoniche vengono trovate.
Ora che hai raccolto tutti i dati è il momento di calcolare qualche indice per valutare stato di indicizzazione del sito web.
Crawl ratio – rapporto di scansione
Questo rapporto indica l’interesse di Google nello scansionare le pagine di un sito web. Maggiore è il valore e maggiore è l’interesse di Googlebot a cercare aggiornamenti nei contenuti.
Formula: media pagine scansionate al giorno / pagine indicizzabiliUn buon rapporto è maggiore di 80%. Rapporti minori indicano che il sito è poco interessante agli occhi del crawler, probabilmente perché viene aggiornato raramente oppure perché ha una bassa autorevolezza online.
Rapporti maggiori sono invece positivi, indicano un forte interesse di Googlebot.
Index ratio – rapporto di indicizzazione
Questo rapporto indica lo stato di indicizzazione, ovvero la percentuale di pagine del sito web che Google indicizza. Il rapporto perfetto è ovviamente 100% ma raramente troverai un valore così preciso (personalmente non mi è mai capitato).
Formula: pagine indicizzate / pagine indicizzabiliUn buon rapporto è compreso tra 80% e 120%. Rapporti minori indicano che il sito è poco indicizzato, probabilmente per colpa di contenuti di basso valore o copiati, canonical tag sbagliati, spam o mille altri motivi.
Rapporti maggiori sono più complessi da valutare e possono significare diverse cose:
- Google ha indicizzato vecchi file, come .pdf, ancora nel server FTP ma non più linkati internamente al sito
- il sito ha contenuti duplicati indicizzati, ad esempio versione www e versione not-www oppure per causa di parametri non gestiti o rel canonical errati
- la scansione con Screaming Frog o Visual SEO è stata fatta male, il sito ha più pagine di quelle rilevate. Verifica le impostazioni di Screaming Frog, il setup del crawler deve essere specifico per il tuo sito web (usi link nofollow? Usi link in JavaScript?)
Sitemap ratio – rapporto di indicizzazione della sitemap.xml
Formula: pagine inserite in sitemap.xml / pagine indicizzabiliIl rapporto perfetto è 100% ma, anche in questo caso, raramente capita. Un buon rapporto è compreso tra 90% e 110%.
Rapporti minori indicano che la sitemap.xml è incompleta. Confronta i dati di scansione del sito con la sitemap e trova le differenze.
Rapporti maggiori possono indicare che:
- la scansione fatta sul sito web è errata, in realtà le pagine del sito sono di più
- la sitemap.xml include URL che non dovrebbe, come ad esempio pagine noindex. Scansiona la sitemap.xml con Screaming Frog e confronta i dati con quelli di scansione del sito e troverai gli URL in eccesso
Rendering ratio
Formula: pagine renderizzate / pagine indicizzabiliIl valore perfetto è chiaramente 100% ma con un sito basato su framework in JS raramente si possono ottenere risultati perfetti. Un buon valore è compreso tra 80% e 100%.
Come saprai i contenuti JavaScript non vengono indicizzati subito dopo essere stati scansionati, devono infatti prima venire renderizzati. È utile calcolare il rapporto di rendering per capire quante risorse del sito vengono viste correttamente da Google.
Innanzitutto, trova una frase sempre presente nella versione solo HTML delle tue pagine. Potresti prendere la partita IVA oppure altri elementi che sai essere in chiaro nell’HTML. Quindi, trova una frase di un contenuto dipendente da JavaScript, presente quindi solo nella versione renderizzata delle tue pagine. Questo testo non dovrebbe essere presente nella risposta iniziale della pagina dal server, ma piuttosto presente solo dopo il rendering. Ora esegui due query per avere i valori di indicizzazione:
- Utilizza l’operatore di ricerca “site:” + la frase solo HTML. Questo ti mostrerà quante pagine totali Google ha indicizzato.
- Utilizza l’operatore di ricerca “site:” + la frase presente nelle pagine con JavaScript. Questo ti mostrerà quante pagine totali Google ha renderizzato.
Dividendo il numero di pagine renderizzate per il numero di pagine indicizzate, otterrai il rapporto di rendering.
Quality ratio
Formula: pagine incluse / pagine escluse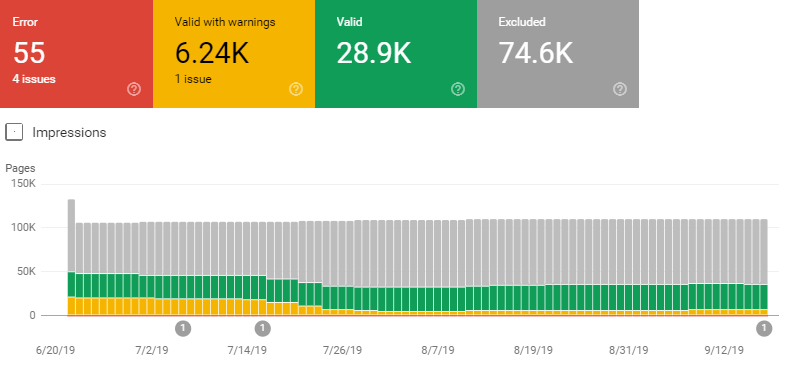
Il Quality Ratio è il rapporto che misura la qualità del crawling rapportando le pagine che Google decide di includere nell’indice con quelle che invece esclude.
Per il calcolo delle pagine incluse dobbiamo sommare le pagine valide e le pagine valide con avvisi, dato che entrambe le categorie di pagine finiscono nell’indice.
Per il valore delle pagine escluse sommiamo le pagine in errore con le pagine escluse.
Il risultato sarà un valore percentuale variabile da 0% a 100%. Quale valore o range di valori può essere considerato buono? Dal punto di vista del crawl budget è buona norma evitare di far perdere tempo a Googlebot, non diamogli pagine inutili da scansionare.
Secondo me un buon range per il Quality ratio è compreso tra 35% e 100%, più si avvicina a 100% e meglio è.
Conclusioni
Con questi rapporti è possibile valutare lo stato di indicizzazione di un sito web ed individuare criticità che possono pregiudicare una buona SEO.
Spero che questo metodo ti possa aiutare durante le analisi che affronterai, se hai domande lascia un commento.
Articoli correlati
Autore

Mi chiamo Giovanni Sacheli e dal 2009 aiuto le aziende a farsi trovare online. Sono specializzato in SEO tecnica e PPC, competenze che applico quotidianamente nella mia agenzia, Searcus Swiss Sagl. Mi piace sviluppare strumenti a supporto del mio lavoro, ho creato SEOdata.app e cluster.army e co-scritto il libro SEO Audit Avanzato. Curo maniacalmente questo blog per colleghi e appassionati, dove mi "appunto" quello che imparo. Sono un NERD anni '80, motociclista e orgoglioso papà di due bambini.
Link:
Giovanni Sacheli
SEO Audit Avanzato
Searcus Swiss Sagl
SEOdata.app
cluster.army
Commenti |7
Lascia un commentoOttimo articolo, come sempre :) Un unico dubbio: ma siamo sicuri che le pagine 404 non vengono indicizzate? A volte capita persino di trovarle in SERP…
Ciao Michele, grazie del commento! Una pagina, se costantemente in 404, viene rimossa dall’indice di Google. Può capitare di trovare 404 in SERP se sono 404 recenti che Google non ha ancora rimosso.
A presto e buon lavoro!
Ciao Giovanni,
come sempre articolo ricco di informazioni utili. Una domanda, è normale che il Crawl ratio raggiunga valori del 400% o superiori?
Quale potrebbe essere il problema in caso?
Ciao Manuela grazie per la domanda.
Un crawl ratio del 400% è abbastanza alto, significa che Googlebot scansiona 4x le pagine del sito in media, ogni giorno.
A mio parere questo valore di crawl budget non è un problema, anzi, è positivo. Significa che Google è “goloso” di scoprire aggiornamenti e nuove pagine nel sito web in questione.
Di solito i motivi per un alto crawl budget possono essere:
il sito web è nuovo (il crawl budget scenderà)
ottimi tempi di risposta del web server
vengono pubblicati spesso nuovi contenuti
vengono aggiornati spesso i contenuti
il sito web ha una buona authority online
Ciao Giovanni, grazie dell’articolo / guida ottimo come sempre e che ho approfondito anche grazia al libro SEO Audit Avanzato a cui hai collaborato. Finalmente zero fuffa, contenuti di qualità e “actionable” sulla SEO. Grazie!
Ciao Giovanni, complimenti per i pezzi sempre dettagliati che richiamo sempre alle bisogna. Mi sbaglio o la formula del Crawl Ratio si basa sull’assunto che le pagine indicizzabili siano meno di quelle indicizzate? Mentre se l’Index Ratio ha un valore insolitamente alto, il rapporto del Crawl Ratio dovrebbe tenere conto delle indicizzate, in quanto saranno quantomeno queste ad essere sottoposte a scansione con più frequenza. E allora mi sorgerebbe l’ulteriore domanda: ma non è meglio tararlo su tutte le pagine sottoposte a scansione (valide + escluse)? Perdona eventuali castronerie :).
Ciao Riccardo, grazie a te per il commento.
La formula del crawl ratio è: pagine scansionate/pagine indicizzabili.
La formula dell’index ratio è: pagine indicizzate/pagine indicizzabili, e non è detto che le indicizzate siano meno delle indicizzabili. Ci possono essere casi dove le indicizzate sono di più delle indicizzabili, ad esempio per mancanza di rel canonical o redirect www/not www o http/https.
Il crawl ratio serve a capire quango Google è curioso di scansionare il sito e aggiornare le pagine.
Se basi il calcolo sulle indicizzate, e il sito ha problemi di indicizzazione per qualsiasi motivo, avresti valori poco significativi.
Se basi il calcolo sulle indicizzabili trovate via crawling, hai un valore più ragionato.
Ad ogni modo, se il sito è ben indicizzato e non ha problemi tecnici, indicizzate e indicizzabili sono valori molto simili, quindi in questo caso cambierebbe poco usare uno o l’altro.
Se basi i rapporti anche sulle pagine escluse vai a sballare tutti i valori, perdono di significato perché conteggi pagine che potrebbero nemmeno esistere sul sito live. Infatti, nelle pagine escluse puoi trovare URL in disallow, URL canonicalizzati, noindex, redirect, 404 di vecchie versioni del sito … non vedo il senso di considerare pagine non indicizzabili e magari nemmeno esistenti per il calcolo del crawl e index ratio.