Screaming frog, lo spider che emula il comportamento di Googlebot, è un supporto indispensabile per la diasagnosi dei siti web.
Le attività di analisi SEO sono tantissime e spaziano dalle più tecniche alle più concettuali e pratiche, pensa ad esempio agli innumerevoli test di usabilità. Come in ogni cosa non tutto può piacere e anche per gli specialisti SEO ci sono attività che si svolgono più volentieri di altre… Ecco, a me piace molto la SEO tecnica, i tool di analisi, ottimizzare il crawling e gli Audit SEO. Mi rilassa e mi viene relativamente facile cercare errori nel codice HTML, mancanze tecniche e strutturali che possono rendere la vita difficile a Googlebot. Questa è una delle attività che considero più divertenti ed appassionanti, una sorta di caccia al tesoro!
Screaming Frog è un software indispensabile per fare una SEO efficiente, ne ho parlato a diversi convegni.
The @screamingfrog guru @EVEMilano going deep on technical SEO at #SMConnect
— Andrea Pernici (@andreapernici) December 1, 2017
Il processo di revisione tecnica di un sito web può essere una attività scoraggiante quando si è alle prime armi dato che richiede una metodologia molto rigida, tanto tempo e i giusti strumenti.
La prima attività con cui inizio un Audit SEO è solitamente il crawling del sito web. Ci sono diversi strumenti utili a questo scopo, uno dei più famosi ed utilizzati è senza dubbio Screaming Frog SEO Spider, disponibile per Windows, Mac e Ubuntu. L’interfaccia del tool è molto semplice e user friendly, è veloce da usare e da interpretare. Le numerose opzioni disponibili nel pannello di configurazione tuttavia potrebbero confondere i meno esperti, soprattutto le prime volte che si affrontano crawling importanti. Capire il significato di ogni opzione di Screaming Frog è indispensabile per fare dei crawling corretti, ogni sito ha le sue caratteristiche e peculiarità e tramite le opzioni dello spider si deve adattare il tool all’ambiente che andrà a visitare per permettergli di fare scansioni corrette.
Sceglierne una opzione piuttosto che un’altra può cambiare radicalmente il risultato del crawling.
Ho scritto questa Guida Completa di Screaming Frog usando come base di partenza quella pubblicata da SEER Interactive, ho quindi aggiunto procedimenti testati personalmente ed altre informazioni ottenute con l’uso quotidiano del tool. In futuro mi tornerà utile per ricordarmi tutti i trucchetti del mestiere che volta per volta imparo, e spero possa servire anche ad altri webmaster per capire le potenzialità di questo potente crawler per le analisi SEO.
Dato che l’articolo è molto lungo e copre molte funzioni disponibili in Screaming Frog, ho pensato fosse meglio creare un indice per agevolare la navigazione. Per iniziare scegli l’argomento che ti interessa e goditi la guida!
1. Le Basi del Crawling con Screaming Frog
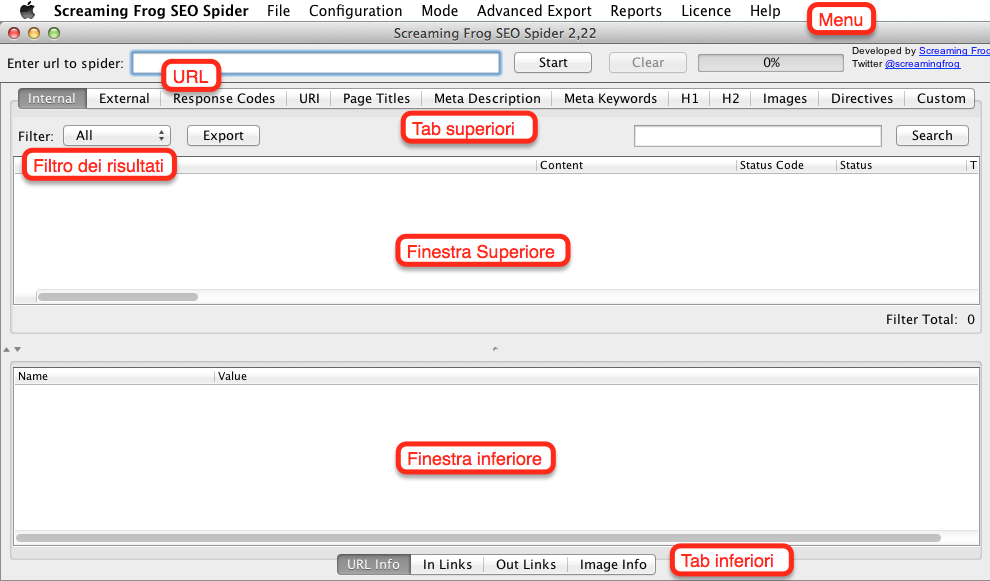
1.1 I comandi base
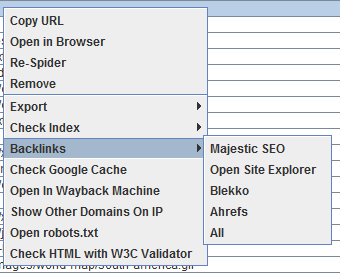
Cliccando con il tasto destro su qualsiasi URL nella finestra superiore dei risultati, potrai eseguire le seguenti azioni:
- Copiare oppure aprire l’URL
- Fare di nuovo crawling dell’URL oppure rimuoverlo dalla lista
- Esportare le informazioni di un URL specifico, i link in entrata, in uscita oppure le informazioni dell’immagine.
- Controllare l’indicizzazione della pagina in Google, Bing e Yahoo
- Controllare i backlinks della pagina con Majestic, OSE, Ahrefs e Blekko
- Aprire la pagina nella cache di Google per verificarne la versione e la data
- Vedere le vecchie versioni della pagina salvate da archivi online
- Validare il codice HTML della pagina
- Aprire il file robots.txt relativo al sito che si sta analizzando
- Cercare altri domini ospitati sullo stesso IP
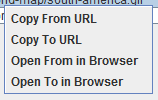
Nello stesso modo, nella finestra inferiore, cliccando con il pulsante destro potrai:
- Copiare oppure aprire l’URL nella colonna “To” e “From” per la riga selezionata.
1.2 Avviare il crawling dell’intero sito web
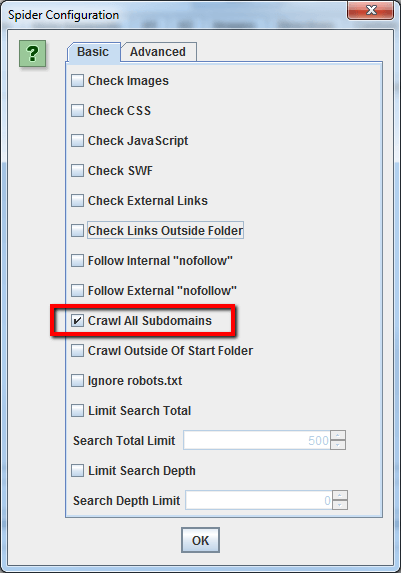
Come impostazione di base, Screaming Frog esegue il crawling solo del sottodominio che inserisci. Qualsiasi sottodominio aggiuntivo che lo spider potrebbe incontrare sarà trattato come un link esterno. Per abilitare lo spider a fare crawling di tutti i sottodomini, devi entrare nel pannello di amministrazione e cambiare una opzione della sezione relativa alla configurazione dello spider.
Selezionando “Crawl All Subdomains” lo spider farà il crawling anche di tutte le pagine, linkate internamente, appartenenti a sottodomini.
Primo Step:
Secondo Step:
Per velocizzare il processo di crawling ti consiglio di non fare scansionare a Screaming Frog le immagini, CSS, JavaScript, SWF, oppure link in uscita. Puoi modificare le opzioni nel pannello di controllo dello spider.
1.3 Come fare crawling di una singola sotto-directory
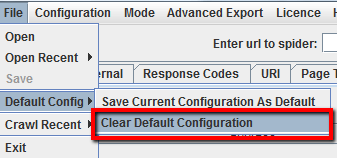
Se vuoi limitare l’azione dello spider ad una singola cartella (sub-folder), ti basterà inserire l’URL esatto del sub-folder e premere Start senza cambiare nessuna impostazione di default. Se in precedenza hai sovrascritto le impostazioni di base ti basterà resettare la configurazione di default tramite l’opzione dedicata nel menu “File”, oppure spunta tutte le opzioni in modo da non avere niente selezionato nella configurazione dello spider.
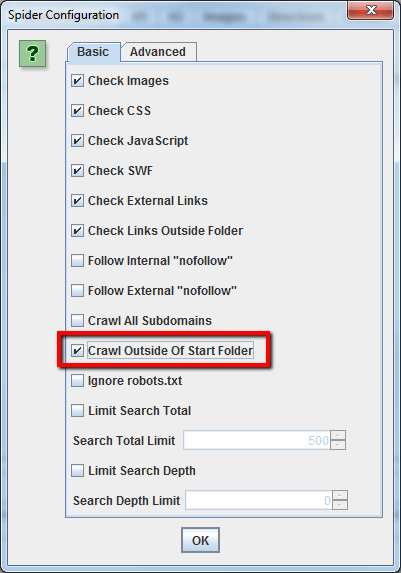
Se preferisci iniziare a fare crawling dentro una cartella specifica, ma vuoi recuperare anche le altre pagine del sottodominio, assicurati di aver selezionato l’opzione “Crawl Outside Of Start Folder” nel pannello di configurazione dello spider, prima di inserire l’URL di partenza.
1.4 Come fare crawling di specifici sottodomini o sotto-directories
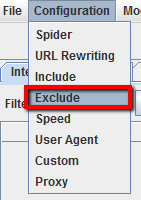
Se vuoi limitare il crawling a specifici sottodomini o sotto-directories puoi usare le RegEx. Questo comando si usa per impostare le regole nella sezione “Include/Exclude” del pannello di configurazione dello spider.
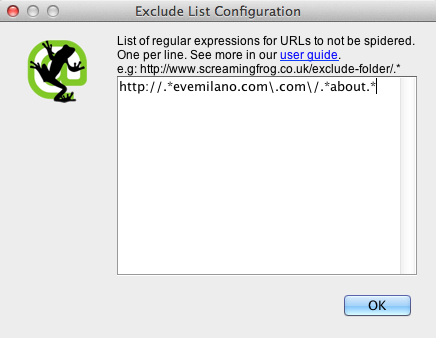
Esclusione:
In questo esempio vogliamo fare crawling di tutte le pagine del sito tranne la pagina “about”, in tutti i sottodomini.
Step 1:
Step 2:
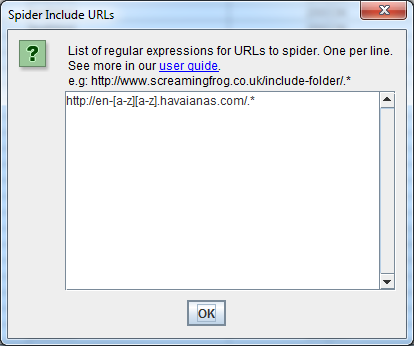
Inclusione:
Una situazione opposta a quella presentata precedentemente: l’inclusione, ovvero fare crawling soltanto di certe pagine. In questo esempio vogliamo fare crawling soltanto del sottodominio in lingua Inglese del sito havaianas.com.
1.5 Voglio una lista di tutte le pagine del mio sito
Come impostazione di base, Screaming Frog fa crawling di tutte le immagini, JavaScript, CSS e file flash che incontra. Per raccogliere soltanto le pagine HTML devi deselezionare “Check Images”, “Check CSS”, “Check JavaScript” e “Check SWF” nella configurazione dello spider.
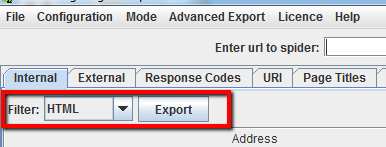
Utilizzare lo spider in questo modo permette di creare una lista di tutte le pagine (URLs) del sito linkate internamente. Una volta terminato il processo di crawling spostati nella tab Internal e filtra i risultati per “HTML”. Clicca quindi “Export” e otterrai la lista completa delle pagine del sito in formato .CSV.
Consiglio:
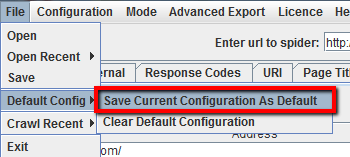
Se di abitudine usi il crawler con opzioni customizzate, puoi salvare la tua configurazione dello spider:
1.6 Voglio una lista di tutte le pagine in una specifica sotto-directory
Oltre a deselezionare “Check Images”, “Check CSS”, “Check JavaScript” e “Check SWF”, dovrai anche deselezionare “Check Links Outside Folder” nel pannello di configurazione dello spider.
Lanciando Screaming Frog con queste impostazioni otterrai una lista di pagine contenute soltanto nella sotto-directory. Le pagine che non ottengono link interni non saranno incluse nella lista.
1.7 Come ottenere una lista di domini che i competitors usano per redirezionare traffico verso i loro siti principali
1.8 Come trovare tutti i sottodomini di un sito e verificare i link interni
Inserisci l’URL della root nel tool ReverseInternet, poi clicca sulla tab Subdomains ’per vedere la lista dei sottodomini.
Ora usando Scrape Similar puoi raccogliere la lista di URLs tramite la query XPath:
Esporta i risultati in .CSV e carica il file in Screaming Frog usando la “List mode”. Lancia il crawling, quando lo spider avrà finito potrai verificare gli status code, tutti i link nella homepage del sottodominio, anchor text ed il tag title duplicato (e altre info).

1.9 Come fare crawling di un eCommerce oppure di sito di grandi dimensioni, con molte pagine
Screaming Frog non è studiato per fare crawling di centinaia di migliaia di pagine a causa di limiti di memoria fisica del computer sul quale viene eseguito, in particolare mi riferisco ai limiti di memoria per applicativi in Java. Tuttavia, ci sono degli accorgimenti da prendere per evitare che il programma si blocchi quando fa crawling di grossi siti, ovvero con più di 50.000 pagine.
Come prima cosa puoi aumentare l’allocazione della memoria per lo spider. Come seconda opzione potresti spezzettare il sito in sotto-directories a fare crawling di una singola sezione per volta. Come ultimo accorgimento potresti dire allo spider di non scansionare immagini, JavaScript, CSS e flash in modo da salvare memoria da dedicare alle sole pagine HTML.
Consiglio:
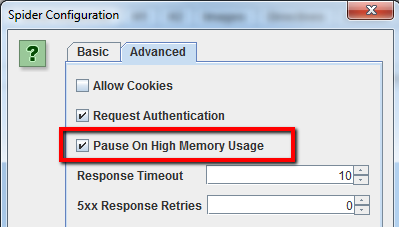
Con versioni precedenti di Screaming Frog poteva capitare che il crawler andava in time-out su siti molto grossi. Dalla versione 2.11 puoi dire al programma di mettersi in pausa quando la memoria si sta per esaurire. Queste impostazioni di sicurezza evitano che Screaming Frog vada in crash prima di aver salvato oppure prima di aver aumentato la memoria allocata.
Queste sono le impostazioni di default, se stai per iniziare un crawling molto esteso ricordati di attivare “Pause On High Memory Usage” nelle impostazioni avanzate dello spider.
1.10 Come fare crawling di un sito ospitato su un vecchio server
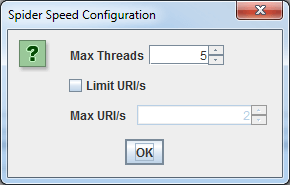
In alcuni casi, i vecchi server potrebbero non essere in grado di gestire le numerose richieste simultanee di URLs di Screaming Frog. Per ridurre la velocità di crawling dello spider basta andare nella sezione “Speed” delle opzioni e scegliere un valore inferiore cercando di trovare il giusto equilibrio con il web server. Ovviamente da questo menu puoi anche aumentare il numero di richieste per velocizzare il crawling su server particolarmente potenti.
Consiglio:
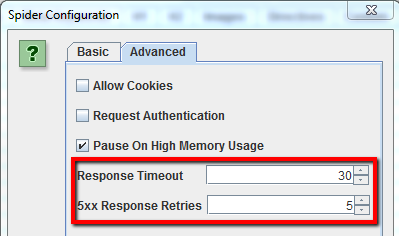
Se noti che Screaming Frog restituisce troppi falsi errori del server (ovvero pagine in errore che testate una seconda volta restituiscono codice 200), vai nelle opzioni “Avanzate” dello spider e aumenta il “Response Timeout”’ e le “5xx Response Retries”.
1.11 Come fare crawling di siti che richiedono i cookies
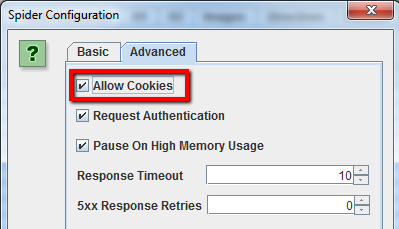
Sebbene gli spider dei motori di ricerca non accettano i cookies di default, se stai facendo crawling di un sito che richiede necessariamente i cookies ti basterà selezionare “Allow Cookies” nella tab Advanced delle opzioni dello spider.
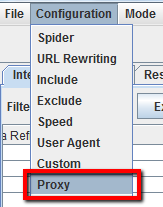
1.12 Come fare crawling usando un proxy oppure un user-agent differente
Per fare crawling usando un proxy, seleziona “Proxy” nel menu di configurazione ed inserisci le informazioni del server Proxy.
Per fare crawling usando un user-agent differente seleziona “User Agent” nel menu di configurazione, scegli il bot di ricerca dal menu a tendina oppure inserisci l’user-agent desiderato.
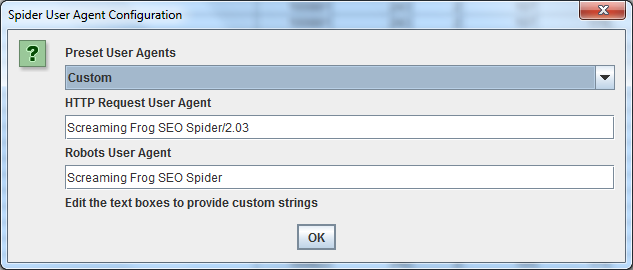
1.13 Come fare crawling di pagine protette da password
Quando lo spider di Screaming Frog trova pagine protette da password, verrà mostrato un pop-up nel quale potrai inserire il nome utente e la password per accedere ai contenuti protetti.
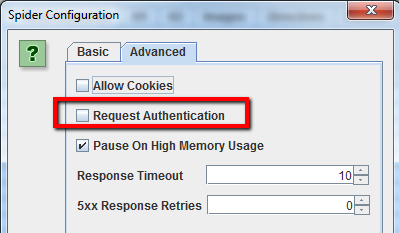
Per disattivare il pop-up ti basta togliere la spunta da “Request Authentication” nella tab Advanced del pannello di controllo dello spider.
2. Analizzare i Link Interni
2.1 Come raccogliere informazioni sui link interni ed esterni del mio sito (anchor text, direttive, links per pagina etc.)
Se non hai bisogno di verificare le immagini, JavaScript, flash o CSS sul sito, deseleziona queste opzioni nel pannello di controllo dello spider per salvare tempo e memoria.
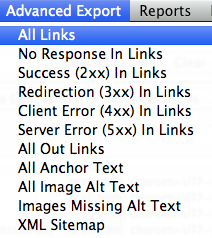
Una volta che lo spider avrà finito di fare crawling, usa la voce “Advanced Export” del menu per esportare tutti i link “All Links” in formato .CSV.
Il file conterrà tutti gli URL dei links, l’anchor text, le direttive etc.
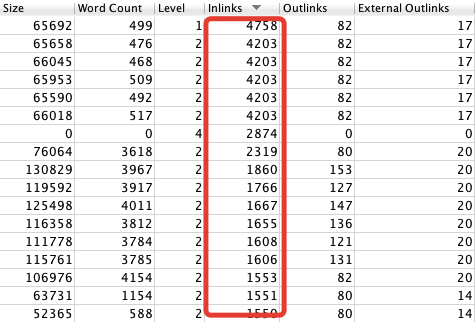
Per trovare velocemente il numero di link presenti in ogni pagina vai nella tab Internal e ordina i dati della colonna “Outlinks”.
Consiglio: Una vecchia linea guida di Google diceva di non superare i 100 link per pagina, ora sappiamo che quel limite è stato superato ma è sempre buona norma non esagerare.
2.2 Come trovare link interni rotti (broken internal links) su una pagina o un sito
Se non hai bisogno di verificare le immagini, JavaScript, flash o CSS sul sito, deseleziona queste opzioni nel pannello di controllo dello spider per salvare tempo e memoria.
Una volta che lo spider avrà finito di fare crawling, ordina i dati della colonna “Status Code” nella tabella “Internal”. Tutti gli errori 404, 301 oppure altri Status Code possono essere facilmente individuati e filtrati.
Puoi visualizzare ulteriori informazioni sui link interni nella parte bassa dello schermo, semplicemente cliccando su qualsiasi URL nella lista dei risultati del crawling nella finestra in alto dello schermo.
Dopo aver selezionato un URL, puoi cliccare sulla tab In Links per trovare la lista di pagine che linkano all’url selezionato, le anchor text e le direttive di quei links. Questa funzionalità è molto utile per trovare pagine che hanno link interni che devono essere aggiornati.
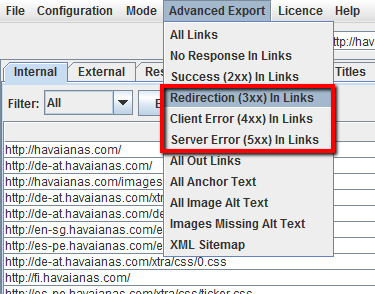
Per esportare in .CSV la lista completa delle pagine che includono link rotti o redirezionati, scegli “Redirection (3xx) In Links” oppure “Client Error (4xx) In Links” oppure “Server Error (5xx) In Links” nella voce del menu “Advanced Export”.
Alcuni webmaster utilizzano i link relativi all’interno del loro sito, questa svista se accompagnata ad un errore comune quello di inserire i link senza prefisso HTTP può generare catene di link infiniti in grado di consumare il crawl budget dei motori di ricerca inutilmente. Per fortuna questo non è un grande problema perché con Screaming Frog è possibile individuare e correggere questi link in un attimo. Per filtrare i link errati basta cliccare sul menu di configurazione del crawler ed impostare l’inclusione dei soli caratteri:
I risultati del crawling mostreranno tutte le pagine che linkano con la sintassi errata.
2.3 Come trovare link in uscita rotti (broken outbound links) su una pagina o un sito ed in genere tutti i link che puntano fuori
Per trovare i link in uscita, dopo aver deselezionato “Check Images”, “Check CSS”, “Check JavaScript” e “Check SWF” nel pannello di configurazione dello spider, assicurati di selezionare la voce “Check External Links”.
Una volta che lo spider avrà finito di fare crawling, clicca sulla tab External nella finestra superiore, ordina i risultati per “Status Code” e potrai trovare velocemente tutti gli URL con Status Code diverso da 200. Cliccando su qualsiasi URL nei risultati del crawling e successivamente sulla tab In Links nella finestra inferiore, troverai la lista di pagine che puntano a quello specifico URL che hai selezionato. Puoi usare questa funzione per identificare pagine che richiedono un aggiornamento dei link esterni.
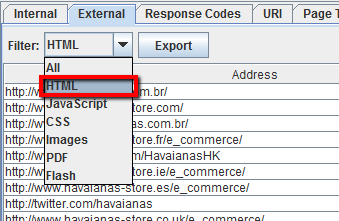
Per esportare la lista completa degli outbound links, clicca su “Export” nella tab Internal. Puoi anche impostare un filtro per esportare link che puntano ad immagini esterne, file JavaScript esterni, file CSS esterni, file Flash e PDF esterni.
Per limitare il filtro alle sole pagine seleziona “HTML”.
Per una lista completa di tutte le pagine che contengono i link outbound e le relative anchor text, seleziona “All Out Links” dalla voce del menu “Advanced Export” e poi filtra la colonna “Destination” del .CSV in modo da escludere il proprio dominio.
2.4 Come trovare link che vengono redirezionati
Dopo che lo spider ha finito di fare crawling, seleziona la tab Response Codes nella finestra superiore di Screaming Frog, poi filtra per “Redirection (3xx)”. Questa tab ti fornirà una lista di tutti i link interni ed esterni che vengono redirezionati. Ordina per “Status Code” e potrai distinguere ogni singolo errore e suddividere i redirect per categoria.
Clicca un link qualsiasi nella finestra superiore “Response Codes” e poi naviga nella tab In Links nella finestra inferiore per vedere quali sono le pagine che contengono il link che viene redirezionato. Se esporti direttamente da questa tab potrai vedere soltanto le informazioni mostrate nella finestra superiore (Address, Status Code e Redirect URL).
Per esportare la lista completa delle pagine che contengono link che vengono redirezionati, devi selezionare “Redirection (3xx) In Links” nel menu “Advanced Export”. Il file esportato includerà le locations di tutti i link redirezionati. Per mostrare solo i redirect interni al sito, filtra la colonna “Destination” nel file .CSV in modo da includere soltanto il tuo dominio.
Consiglio:
Usa la funzione VLOOKUP di Excel tra due file esportati per aggiungere alle colonne “Source” e “Destination” anche la location finale dell’URL.
La formula di esempio è:
=VLOOKUP([@Destination],’response_codes_redirection_(3xx).csv’!$A$3:$F$50,6,FALSE) - “response_codes_redirection_(3xx).csv” è il file .CSV che contiene gli URL redirezionati
- “50” è il numero di righe presenti in quel file
2.5 Opportunità di linking interno
Ti consiglio di leggere questa guida Scaling Internal Link Building with Screaming Frog & Majestic
2.6 Voglio scansionare soltanto gli URL canonici evitando tutte le pagine parametrizzate
Dal pannello di controllo dello spider accedi alla tab Advanced e seleziona “Respect Canonical“
3. Analizzare i contenuti del sito
3.1 Come identificare pagine con poco contenuto
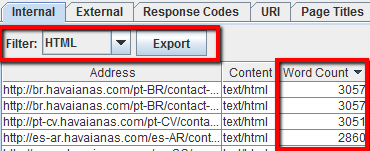
Dopo che lo spider ha finito di fare crawling, vai nella tab Internal e filtra solo i file HTML. A questo punto scrolla a destra fino a quando non trovi la colonna “Word Count“.
Ordina la colonna dal minore al maggiore per vedere quali sono le pagine con poco testo. Puoi trascinare la colonna a sinistra per affiancarla agli URL. Clicca “Export” nella tab Internal se preferisci lavorare su un file .CSV con Excel.
3.2 Voglio la lista di tutte le immagini contenute in alcune pagine
Se hai già fatto crawling di un intero sito o di una sotto-cartella, ti basta selezionare nella finestra superiore la pagina che vuoi analizzare e quindi cliccare sulla tab Image Info nella finestra inferiore.
In questa lista puoi vedere tutte le immagini che sono state trovate in quella pagina. Le immagini sono elencate sotto la colonna “To”.

Consiglio:
Clicca con il tasto destro su qualsiasi risultato nella finestra inferiore per copiare o aprire un URL.
In alternativa puoi vedere tutte le immagini contenute in una pagina semplicemente facendo crawling di solo quell’URL. Assicurati di aver impostato il valore di profondità del crawler (Crawl Depth) a 1 nelle impostazioni dello spider.
Una volta che il crawler ha terminato puoi cliccare sulla tab Images per vedere l’elenco di tutte le immagini che sono state trovate da Screaming Frog.
Per esportare i dati usa la voce del menu “Advanced Export” e clicca su “All Image Alt Text” per avere la lista completa delle immagini e delle rispettive alt tag.
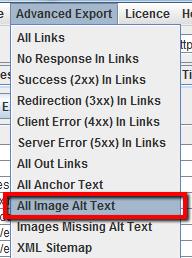
3.3 Come trovare tutte le immagini a cui manca l’alt tag oppure con alt tag con troppo testo
Per prima cosa assicurati di aver selezionato la voce “Check Images” nel pannello di configurazione dello spider. Dopo che lo spider avrà finito di fare crawling vai nella tab Images e filtra per “Missing Alt Text” oppure “Alt Text Over 100 Characters”. Ora potrai individuare le pagine che contengono le immagini semplicemente cliccando nella tab Image Info nella parte inferiore dello schermo. Le pagine saranno elencate nella colonna “From”.
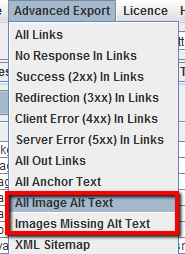
In alternativa, nella voce del menu “Advanced Export”, puoi esportare “All Image Alt Text” oppure “Images Missing Alt Text” direttamente in formato .CSV.
Il file scaricato mostrerà la lista di tutte le pagine che contengono le immagini usate nel sito.
3.4 Come trovare tutti i file .CSS nel mio sito
Nel pannello di configurazione dello spider seleziona soltanto “Check CSS” prima di lanciare il crawling. A processo terminato naviga nella tab Internal e filtra per “CSS”.
3.5 Come trovare tutti i file JavaScript nel mio sito
Nel pannello di configurazione dello spider seleziona soltanto “Check JavaScript” prima di lanciare il crawling. A processo terminato naviga nella tab Internal e filtra per “JavaScript”.
3.6 Come identificare tutti i plugin jQuery usati sul sito ed in quali pagine vengono usati
Prima di tutto assicurati di aver selezionato l’opzione “Check JavaScript” nel pannello di configurazione dello spider. Dopo che lo spider ha finito il suo lavoro, filtra solo i file “JavaScript” nella tab Internal poi cerca “jQuery”. La lista conterrà tutti i file dei plugin, ordina i dati con la colonna “Address” poi apri la tab InLinks nella parte inferiore dello schermo oppure esporta in un file .CSV tutte le pagine che includono i plugin (campo della colonna “From”).

In alternativa puoi usare la funzione “Advanced Export” ed esportare in .CSV la lista “All Links” e filtrare la colonna “Destination” per mostrare solo gli URL con “jquery”.
Consiglio:
Non tutti i plugin jQuery sono negativi per la SEO. Se vedi un sito che usa jQuery, la cosa migliore da controllare è che il contenuto che ti interessa indicizzare sia incluso nel codice sorgente e mostrato al caricamento della pagina e non successivamente. Se sei insicuro controlla la cache di Google oppure informati sul funzionamento di quello specifico plugin.
3.7 Come trovare i file Flash inseriti nel sito
Nel menu di configurazione dello spider seleziona “Check SWF” prima di iniziare il crawling. A processo terminato vai nella tab Internal e filtra per “Flash”.
NB: Questo metodo troverà soltanto i file .SWF che sono linkati in una pagina. Se il file viene richiamato con JavaScript, ti servirà un filtro customizzato.
3.8 Come trovare i file PDF inseriti nel sito
Dopo che lo spider ha finito di fare crawling, filtra i risultati della tab Internal selezionando “PDF”.
3.9 Come identificare la suddivisione dei contenuti all’interno di un sito o un gruppo di pagine
Se vuoi trovare pagine sul tuo sito che contengono uno specifico contenuto, imposta un filtro customizzato per il footprint HTML che definisce univocamente quelle pagine. L’impostazione deve essere fatta prima di avviare il crawling.
3.10 Come trovare le pagine che includono i pulsanti di condivisione social
Per trovare tutte le pagine che contengono i pulsanti di condivisione social, devi impostare un filtro customizzato prima di avviare il crawler. Per creare un filtro customizzato vai nel menu di configurazione e clicca “Custom”. In questa sezione inserisci lo snippet di codice che vuoi ricercare nel codice sorgente delle pagine.
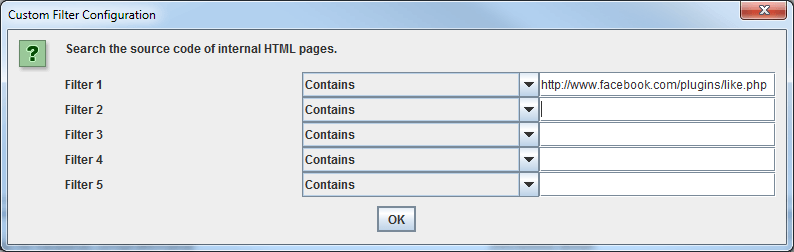
Nell’esempio dello screenshot, si vuole trovare le pagine che contengono il pulsante “Like” di Facebook e per fare ciò filtriamo tutte le pagine che contengono un link verso http://www.facebook.com/plugins/like.php.
3.11 Come trovare le pagine che usano iframes
Per trovare tutte le pagine che includono un iframe, imposta un filtro customizzato per il codice <
3.12 Come trovare le pagine che contengono video oppure file audio
Per trovare le pagine che contengono video embeddati o file audio, imposta un filtro customizzato con lo snippet di codice usato per embeddare un video YouTube, oppure qualsiasi altro media player che viene usato nel sito.
4. Meta Dati e le Direttive
4.1 Come identificare pagine con title tag, meta description oppure URL troppo lunghi e troppo corti
Dopo che lo spider ha finito di fare crawling, vai nella tab Page Titles e filtra per “Over 70 Characters” per vedere tutti i title tag che sono troppo lunghit. La stessa cosa può essere fatta nella tab delle “Meta Description”’ ed in quella degli “URI”.

4.2 Come trovare title tag, meta description e URL duplicati
Dopo che lo spider ha finito di fare crawling, vai nella tab Page Titles e filtra per “Duplicate”. La stessa cosa può essere fatta nelle tab Meta Description e “URI”.

4.3 Come trovare contenuto duplicato e URL che devono essere riscritti/redirezionati/canonicalizzati
Dopo aver terminato il crawling vai nella tab URI, poi filtra per “Underscores”, “Uppercase” oppure “Non ASCII Characters” per trovare tutti gli URL che potrebbero venire riscritti in modo più semplice. Filtra per “Duplicate” per trovare tutte le pagine che hanno versioni multiple dello stesso URL. Filtra per “Dynamic” e troverai tutti gli URL che includono parametri.
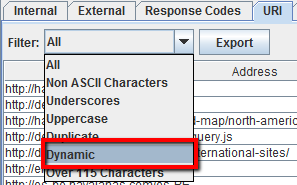
Inoltre, se vai nella colonna “Hash” nella tab Internal e filtri per “HTML” puoi vedere una serie unica di lettere e numeri per ogni pagina. Questo numero seriale serve a contraddistinguere le pagine, Hash identici indicano pagine identiche. Se esporti il .CSV e lo apri in Excel potrai trovare subito gli Hash identici con le formattazioni condizionali.
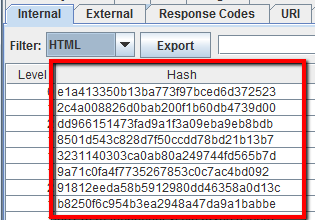
4.4 Come identificare le pagine che includono direttive dei crawler, es: nofollow/noindex/noodp/canonical etc.
Dopo aver terminato il crawling clicca sulla tab Directives. Puoi usare il filtro per visualizzare soltanto specifiche direttive:index
- noindex
- follow
- nofollow
- noarchive
- nosnippet
- noodp
- noydir
- noimageindex
- notranslate
- unavailable_after
- refresh
- nosnippetcanonical
4.5 Come verificare che il file robots.txt funzioni come desiderato
Le opzioni standard di Screaming Frog lo forzano a seguire le direttive del robots.txt che incontra nel sito. Come priorità lo spider seguirà le direttive specifiche assegnate al bot di Screaming Frog. Se non viene definita nessuna direttiva specifica per l’user-agent di Screaming Frog, seguirà le direttive per Googlebot e se nemmeno le direttive per Googlebot sono state assegnate seguirà le direttive globali per tutti gli user-agent. Tieni presente che lo spider seguirà soltanto un set di direttive, non mischierà direttive assegnate a spider diversi.
Se vuoi bloccare alcune parti del sito allo spider, usa la sintassi regolare del robots.txt e assegna le direttive all’user-agent “Screaming Frog SEO Spider”. Per far si che lo spider ignori il robots.txt basta selezionare l’opzione dedicata nel pannello di configurazione.
4.6 Come trovare markup di Schema.org e altri microdati
Per trovare tutte le pagine che contengono markup di Schema oppure qualsiasi altro formato di Microdati, bisogna usare i filtri customizzati. Clicca su “Custom” nel menu di configurazione ed inserisci il footprint che stai cercando.
- Per trovare tutte le pagine che contengono markup di Schema.org, inserisci questo snippet nel filtro customizzato: itemtype=http://schema.org
- Per trovare markup specifici come ad esempio il markup di Schema per il rating, usa il filtro customizzato ‹span itemprop=”ratingValue”›
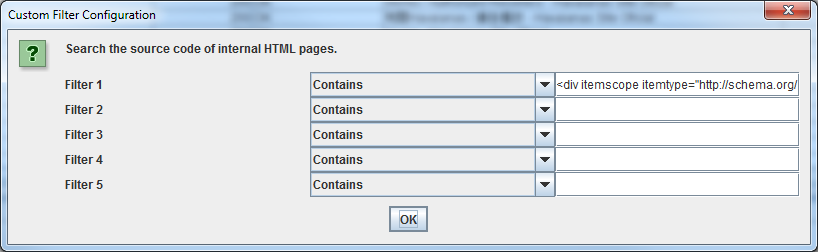
Puoi inserire fino a 5 filtri customizzati differenti. Premi OK e procedi con il crawling del sito o di una lista di pagine.
Quando il crawling è terminato seleziona la tab Custom nella parte superiore dello schermo per trovare tutte le pagine che contengono il tuo footprint. Se hai usato più di un filtro customizzato puoi vederne uno a uno cambiando il filtro nei risultati.
5. Utilità per Sitemap XML
5.1 Come creare una Sitemap XML
Dopo che lo spider ha terminato il crawling, clicca sul menu “Advanced Export” e seleziona “XML Sitemap”.
Salva la sitemap e aprila con Excel. Seleziona “Read Only” e apri il file come tabella XML. Potresti ricevere un avvertimento di incompatibilità con il foglio di lavoro, premi “Yes” e procedi. Ora che la sitemap è stata importata puoi modificare facilmente i valori di frequency, priority ed eventualmente altri. Assicurati che la sitemap contenga una sola versione di ogni URL (canonico), senza parametri o fattori di duplicazione. Quando avrai finito di modificare il file, salva il lavoro come XML.
5.2 Come verificare la Sitemap XML
Prima di iniziare dovrai avere una copia della sitemap.xml salvata nel tuo computer. Apri Screaming Frog e abilita la modalità “List” cliccando la voce del menu “Mode”. Importa il file della sitemap.xml cliccando su “Select File” e poi avvia lo spider. Una volta terminato il crawling potrai vedere se il sito ha pagine che finiscono in errore 404, se vengono redirezionate, se ci sono URL duplicati e altri errori che potrebbero sporcare la sitemap. Per approfondire questo argomento ti consiglio questa guida: Come verificare la correttezza di una Sitemap.xml.
6. Problematiche generali
6.1 Individuare i motivi per cui certe pagine non vengono indicizzate
Ti stai chiedendo perché certe pagine del tuo sito non vengono indicizzate? Per prima cosa assicurati che il robots.txt non blocchi per errore le pagine che vuoi indicizzare poi controlla di non avere tag noindex nell’head. Ora bisogna verificare che queste pagine siano facilmente raggiungibili dagli spider dei motori di ricerca attraverso i link interni al sito. Dopo che Screaming Frog ha terminato il crawling vai nella tab Internal e scorri a destra fino alla colonna “Inlinks”. I valori riportati in colonna rappresentano il numero di link interni che ogni pagina riceve. Controlla che le pagine più importanti ricevano in proporzione più link interni rispetto a pagine secondarie.
Esporta la lista di URL interni in .CSV usando il filtro “HTML” nella tab Internal. Apri il file .CSV con Excel, in un secondo foglio incolla tutti gli URL che non sono indicizzati. Con la funzione VLOOKUP verifica che le pagine non indicizzate siano state raggiunte dal crawler di Screaming Frog.
- In caso negativo devi rivedere i link interni verso quella pagina visto che sembra non averne
- In caso affermativo quella pagina potrebbe ricevere troppo pochi link interni. Cerca di aumentarne il numero in proporzione alle altre pagine di minore importanza.
Consiglio:
Su Google Doc potete trovare questo file da usare in Excel: Pages Not Indexed. Una volta importati i dati di Screaming Frog, il foglio analizza i dati e fornisce possibili spiegazioni per cui le pagine che avete indicato non vengono indicizzate.
6.2 Come verificare la corretta migrazione di un sito web
Segui questa procedura per verificare la corretta migrazione del tuo sito web. Prima di iniziare il crawling del nuovo devi procurarti la vecchia sitemap.xml del sito pre-migrazione. Premi sul tasto “Mode” e attiva la modalità “List”. Carica la vecchia sitemap.xml e avvia lo spider. Per la verifica finale dovrai controllare che tutti i vecchi URL presenti in sitemap.xml vengano correttamente redirezionati verso i nuovi URL. Eventuali errori 404 indicano che tali URL non hanno regole di redirect.
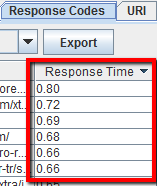
6.3 Come trovare pagine che hanno tempi lunghi di caricamento
Dopo che lo spider ha terminato il crawlng, apri la tab Response Codes e ordina i dati con la colonna “Response Time”. Questa visuale ti aiuterà ad identificare subito le pagine che necessitano di troppo tempo per venire caricate
6.4 Come trovare malware e spam sul sito web
Per prima cosa devi identificare lo snippet di codice che rappresenta il malware o lo spam. Successivamente vai nel menu di configurazione e clicca su “Custom” per modificare i filtri customizzati. ed inserisci il footprint che ti interessa individuare.
Puoi inserire fino a 5 filtri customizzati. Avvia il crawler premendo OK per processare il sito o la lista di pagine.
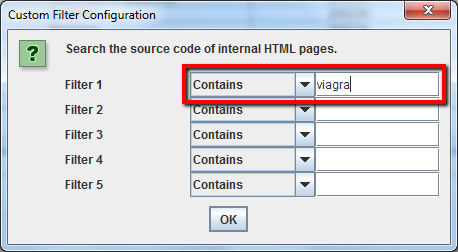
Quando lo spider avrà terminato il processo, seleziona la tab Custom nella parte superiore dello schermo per vedere tutte le pagine che contengono il footprint. Se hai inserito più filtri puoi passare da uno all’altro semplicemente cambiando il filtro dei risultati.
6.5 Come aumentare la memoria allocata a Screaming Frog
Windows 32 & 64-bit: Prima di tutto, se hai una macchina a 64-bit, assicurati di aver scaricato ed installato la versione di Java a 64-bit, altrimenti non potrai allocare più memoria di una macchina a 32-bit. Apri la cartella dove hai installato lo spider (solitamente C:Program Files/Screaming Frog SEO Spider), dovresti trovare 4 file: due applicazioni (install and uninstall), un file .JAR e poi il file .INI di configurazione che ci interessa editare, chiamato “ScreamingFrogSEOSpider.l4j.ini”. Apri questo file con un editor di testo e noterai una riga di codice con questo numero “-Xmx512M” che rappresenta il massimo di memoria assegnata allo spider, ovvero “512Mb”. Il valore preimpostato è “512M”, quindi per raddoppiare la memoria puoi semplicemente raddoppiare il numero sostituendolo con “1024”. Per allocare, ad esempio, 6GB sostituisci il numero con “6144” (attenzione a non modificare il codice antecedente al numero, quindi per 1024 dovrai scrivere -Xmx1024M). Considera che questo valore si riferisce alla memoria RAM e non del disco, quindi se assegni più memoria di quella disponibile nel tuo computer lo spider non si avvierà. Se dovesse capitarti questa situazione apri di nuovo il file di configurazione ed inserisci un valore realistico basato sulla memoria disponibile nella tua macchina.
In genere le macchine Windows a 32-bit sono limitate ad un massimo di 4GB RAM. Questo tradotto vuole dire che potrai allocare un valore compreso tra 1,024mb e 1,500mb.
Per le macchine a 64-bit potrai allocare decisamente più memoria (relativamente a quanta installata). Screaming Frog è programmato per lavorare su macchine a 32 e 64-bit, ricordati di installare Java a 64-bit se la tua macchina è a 64-bit altrimenti non potrai allocare tutta la memoria potenziale dei 64-bit.
Se Windows non ti permette di modificare il file di configurazione (probabilmente ti servono i diritti di amministratore), prova a copiare il file sul desktop, modificalo e rimettilo nella cartella dello spider sostituendo il file vecchio.
Per verificare che la memoria sia effettivamente aumentata riavvia Screaming Frog, clicca su “Help” e successivamente su “Debug” e osserva il valore “Max”. Il valore è sempre leggermente inferiore a quanto allocato, è normale e dipende da JVM management.
Mac: Esistono due metodi per incrementare la memoria di Screaming Frog sul Mac e dipende dalla versione del crawler che si sta utilizzando. Se stai usando l’ultima versione (oppure dalla 2.55 in avanti) puoi semplicemente aprire il Terminale (lo trovi dentro “Applications” e “Utilities”) e digitare uk.co.screamingfrog.seo.spider Memory 1g.
Questo comando alloca 1 GB di memoria a Screaming Frog. Per allocare 9 GB scrivi: uk.co.screamingfrog.seo.spider Memory 8g. Puoi anche specificare la memoria in megabytes, usando la stringa: uk.co.screamingfrog.seo.spider Memory 2048m. Queste impostazioni verranno ricordate anche dopo un aggiornamento e non sarà necessario ripetere l’operazione. Puoi verificare le impostazioni digitando nel terminale: defaults read uk.co.screamingfrog.seo.spider Memory. Il risultato sarà tipo: 8g.
Se stai utilizzando un Mac con versione OS inferiore alla 10.7.3 (32-Bit Macs) dovrai usare una versione uguale o inferiore alla 2.40 di Screaming Frog e dovrai editare il file di configurazione come segue.
Apri in un editor di testo il file “Info.plist” dentro la cartella “/Applications/Screaming Frog SEO Spider”, trova la stringa -Xmx512Mm. Aumenta il valore in base alla memoria disponibile sul tuo sistema, per raddoppiare l’allocazione di memoria ad esempio inserisci -Xmx1024Mm
Se non riesci a trovare il file “info.plist” vai nella cartella “applications” con il finder. Clicca con il pulsante destro su “ScreamingFrogSEOSpider” e seleziona “Show package contents”. Il file”info.plist” è dentro la cartella “contents”. Clicca con il pulsante destro sul file e aprilo con un editor di testo.
Ubuntu: per aumentare la memoria e fare crawling di siti più grandi devi modificare il numero nel file .screamingfrogseospider situato nella cartella “Home” dell’utente. Il file viene creato la prima volta che Screaming Frog viene avviato.
Il file è impostato di default su questo valore: -Xmx512M. Puoi incrementare il valore come spiegato sopra.
Se non sei in grado di aumentare la memoria allocata e devi fare crawling di siti molto estesi, ti consiglio di dividere il sito in sezioni. Puoi usare il menu di configurazione per fare crawling soltanto delle pagine HTML (evitando quindi immagini, CSS e JS) oppure escludendo alcune sezioni del sito. Come alternativa se il sito ha una struttura di URL ben definita puoi dividere il crawling in cartelle (/holidays/, /blog/ etc) oppure usare la funzione Regex per includere soltanto certi URL.
Screaming Frog non è stato sviluppato per fare crawling di siti con centinaia di migliaia di pagine dato che non alloca tutta la memoria in database. Per studiare siti molto grossi si possono usare servizi di crawling online come 80legs oppure DeepCrawl.
7. PPC & Analytics
7.1 Come verificare che il codice di tracciamento di Google Analytics sia presente in tutte le pagine
Prima di avviare il crawler apri i filtri customizzati e nei primi due campi inserisci il codice UA di Analytics che vuoi verificare:
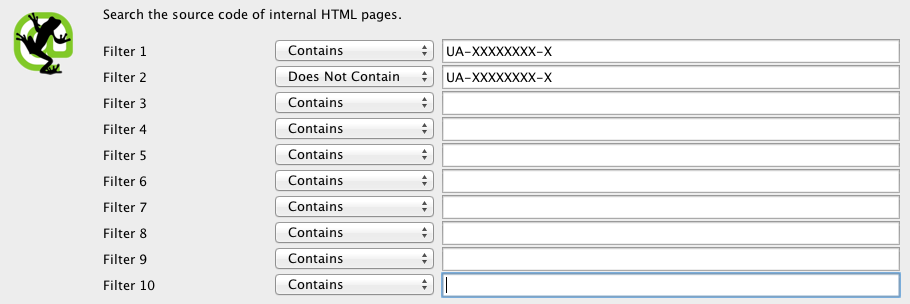
- Contains: UA-XXXXXXXX-X
- Does Not Contain: UA-XXXXXXXX-X
Avvia Screaming Frog e quando ha terminato vai nella tab Custom. Il filtro così impostato ti permetterà di passare da una visualizzazione all’altra semplicemente cambiando il filtro dei risultati.
7.2 Come verificare una lista di landing page usate per il PPC
Salva la tua lista in formato .TXT oppure .CSV poi cambia Screaming Frog in modalità “List”.
Successivamente seleziona il file da caricare e premi “Start” per avviare lo spider. A processo terminato apri la tab Internal e controlla gli status code.
8. Scraping di contenuti
8.1 Come fare scraping dei meta dati di una lista di pagine
Per raccogliere informazioni e meta dati da una lista di URL devi attivare la modalità “List”, caricare la lista di pagine in formato .TXT oppure .CSV e poi avviare lo spider. A processo terminato potrai analizzare gli status code, i link in uscita, il conteggio delle parole contenute nelle singole pagine e ovviamente tutti i meta dati.
8.2 Come fare scraping di tutte le pagine che contengono un determinato footprint
Per prima cosa devi identificare il footprint che ti serve. Salva il codice HTM dell’elemento che vuoi cercare, poi apri il pannello di configurazione, clicca su “Custom” ed inserisci il footprint.
Puoi inserire fino a 5 filtri customizzati nello spider. Premi OK e procedi con il crawling del sito o delle pagine in elenco. In questo specifico esempio voglio identificare tutte le pagine che includono il pulsante “Contattami”, ho quindi cercato il codice del pulsante nelle pagine HTML e l’ho inserito nel campo customizzato del filtro.
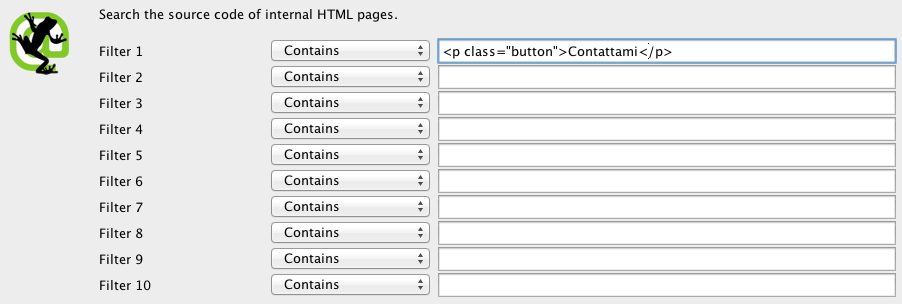
Quando lo spider ha terminato di fare crawling, seleziona la tab Custom nella parte superiore dello schermo per vedere tutte le pagine che contengono il footprint. Se hai inserito più di un filtro customizzato puoi visualizzare i rispettivi dati cambiando il filtro dei risultati.
8.3 Come fare scraping di tutte le pagine che contengono un determinato footprint
Per prima cosa devi identificare il footprint che ti serve. Salva il codice HTM dell’elemento che vuoi cercare, poi apri il pannello di configurazione, clicca su “Custom” ed inserisci il footprint.
9. Riscrittura degli URL
9.1 Come trovare e rimuovere i parametri e le session id dagli URL scansionati
Per identificare tutti gli URL che contengono ID di sessione e parametri, avvia Screaming Frog con le impostazioni di default. Quando lo spider ha terminato clicca sulla tab URI e filtra per “Dynamic” per vedere tutti gli URL che includono parametri.
Per rimuovere i parametri dagli URL raccolti seleziona “URL Rewriting” nel menu di configurazione, apri la tab Remove Parameters e clicca su “Add” per aggiungere i parametri che vuoi rimuovere dagli URL e premi OK. Dovrai lanciare di nuovo il crawling con questi settaggi per ottenere la riscrittura degli URL.
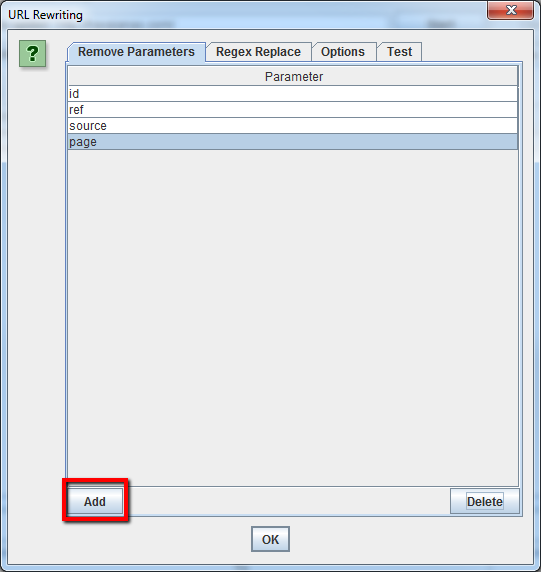
9.2 Come riscrivere gli URL raccolti dal crawler (es: sostituire .com con .co.uk, oppure riscrivere tutti gli URL in minuscolo)
Per riscrivere tutti gli URL archiviati dallo spider, seleziona “URL Rewriting” nel menu di configurazione. Nella tab “Regex Replace” clicca su “Add” per aggiungere una regola RegEx che definisca quello che vuoi sostituire.
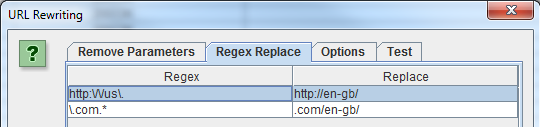
Una volta che hai definito tutte le tue regole di riscrittura ti consiglio di testarle. Vai nella tab Test, inserisci l’URL che vuoi provare nello spazio “URL before rewriting” ed il campo “URL after rewriting” si aggiornerà automaticamente seguendo le regole che hai impostato.
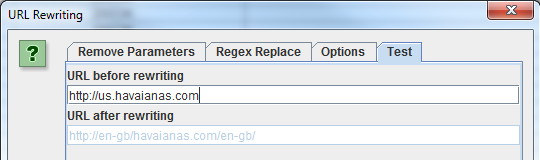
Per rimuovere dal crawling tutti gli URL duplicati da caratteri maiuscoli devi selezionare “Lowercase discovered URLs” nella finestra delle opzioni.
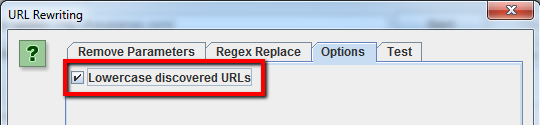
Ricorda che le impostazioni vanno decise prima di avviare lo spider per abilitare la riscrittura degli URL.
10. Analisi delle parole chiave
10.1 Come trovare le pagine più importanti nei siti competitor
Generalmente i siti dei competitor cercheranno di guidare link popularity e traffico verso le loro pagine più importanti attraverso link interni. I competitor orientati alla SEO probabilmente linkeranno le pagine più importanti dal loro blog.
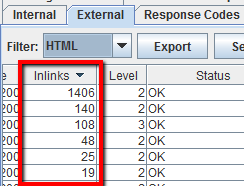
Per trovare le pagine più importanti di un sito avvia il crawling e poi nella tab Internal ordina la colonna “Inlinks”. Le pagine più linkate internamente saranno presumibilmente anche le più importanti per il competitor.
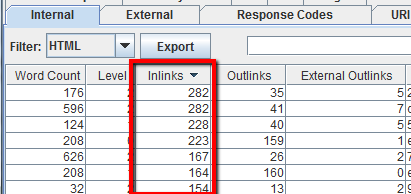
Per trovare le pagine linkate del blog del tuo competitor, non selezionare l’opzione “Check links outside folder” nel menu di configurazione dello spider poi avvia il crawling della cartella o sottodominio del blog. A questo punto nella tab External filtra i risultati cercando l’URL del dominio principale. Scorri la schermata a destra e ordina la colonna “Inlinks” per vedere quali pagine sono linkate più spesso.
Consiglio:
Puoi ottimizzare la visualizzazione dei dati semplicemente trascinando le colonne nella posizione desiderata.
10.2 Come sapere quali anchor text usano i competitors nei link interni
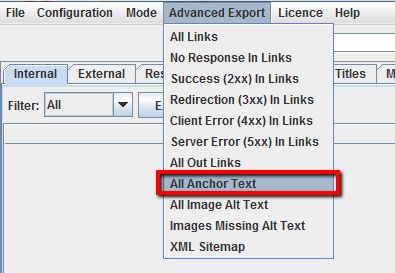
Avvia il crawling sul sito del competitor. A processo terminato vai ne menu “Advanced Export” e seleziona “All Anchor Text” per esportare il file .CSV con l’elenco degli anchor text usati nel sito, dove sono usati e a cosa linkano.
10.3 Come trovare le parole chiave (Meta Keywords) usate dai competitor
Dopo che Screaming Frog ha terminato il crawling del sito del competitor, guarda la tab Meta Keywords per trovare la lista dei tag Meta Keyword usati in ogni pagina. Ordina la colonna “Meta Keyword 1” per trovare i tag vuoti.
10.4 Fare scraping della pagina dei risultati di Google
Inserisci un URL di ricerca con Google in Screaming Frog, ad esempio https://www.google.it/search?q=hotel+milano. Nel menu di configurazione dello spider seleziona soltanto “Ignore robots.txt” mentre nella tab Advanced non selezionare niente. Con l’opzione “Include” puoi scegliere se fare scraping di tutte le pagine che lo spider troverà, oppure decidere se restare su Google.it per analizzare soltanto la prima o tutte le pagine dei risultati (attento a non esagerare oppure Google bannerà il tuo IP temporaneamente). L’ultima impostazione da cambiare è sotto il menu “User Agent”, entra e seleziona Chrome. A questo punto puoi avviare lo spider.
Clicca sull’unico URL trovato (se hai forzato l’analisi solo sulla prima pagina) e nella parte inferiore dello schermo, nella tab Out Links, troverai molte informazioni estratte dalla prima pagina di Google:
- i termini correlati
- i top 10 competitor
- i titoli delle loro pagine
- i siti correlati
- la cache e molto altro.
Con un minimo di fantasia potrete trovare altri trucchi interessanti per recuperare dati da Google.
I più attenti avranno notato in mezzo alla lista alcuni URL con il parametro ?q=related:www.esempio.com. Questi URL sono molto importanti per capire come Google relaziona argomenti e siti web. Il parametro related permette di ottenere, dato un sito web di partenza, una lista di altri siti web correlati, ovvero molto vicini per argomenti e tipologia. Questa info torna molto utile per pianificare strategie di link building e content marketing poiché aiuta ad individuare i siti più attinenti sui quali pubblicare testi e backlink.
Un altro gruppo di URL che può essere analizzato è webcache dato che permette di verificare se l’URL è presente nella cache di Google oppure no.
11. Funzioni per la Link Building
11.1 Come analizzare una lista di URL a cui puntano i link
Se hai fatto scraping oppure hai una lista di URL da controllare, puoi caricare la lista in Screaming Frog tramite la modalità “List” raccogliere alcune informazioni su quelle pagine. Dopo che lo spider avrà finito il suo lavoro vai nella tab Response Codes e analizza gli Staus Code. Potrai ottenere info riguardanti tutti gli outbound links, i tipi di link, le anchor text e le direttive nofollow nella tab Out Links nella parte inferiore dello schermo. La lista ti aiuterà a capire a quali tipologie di siti linkano queste pagine e soprattutto come. Per controllare la tab Out Links assicurati di aver selezionato l’URL che ti interessa nella finestra superiore.
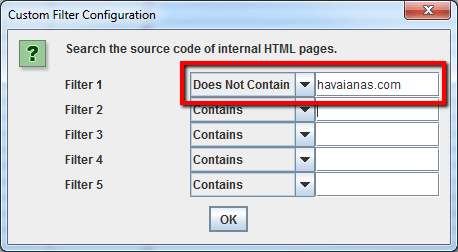
Puoi anche usare un filtro customizzato per determinare se queste pagine ti stanno già linkando o meno.
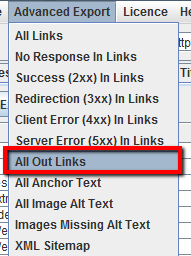
Puoi anche esportare la lista completa dei link in uscita dal menu “Advanced Export Menu” cliccando sulla voce “All Out Links”. Il file conterrà tutti i link che puntano all’esterno.
11.2 Come trovare link rotti ed usarli a proprio vantaggio
Hai trovato un sito dal quale ti piacerebbe ricevere un backlink? Usa Screaming Frog per trovare collegamenti rotti su quel sito. Contatta successivamente il webmaster e se hai contenuti che possono sostituire la pagina di destinazione del link rotto proponila, se ti va bene riceverai un backlink altrimenti avrai comunque fatto un gesto che verrà apprezzato e da cosa nasce cosa, chi lo sa :)
11.3 Come posso verificare i miei backlinks e le relative anchor text
Carica la tua lista di backlink in Screaming Frog e lancia lo spider in modalità “List”. A processo terminato esporta la lista completa di link cliccando “All Out Links” nella tab Advanced Export Menu. La lista contiene tutti gli URL e le anchor text/alt tag per tutti i link in queste pagine. Ora puoi usare un filtro con Excel sulla colonna “Destination” per determinare se il tuo sito è linkato e quale anchor text/alt tag è incluso.
11.4 Come verificare se il tuo sito fa parte di un network di link
Vuoi verificare se un gruppo di siti si sta linkando reciprocamente? Leggi questa guida visualizing link networks using Screaming Frog and Fusion Tables.
11.5 Sto facendo pulizia di backlink e voglio controllare che siano stati tutti definitivamente cancellati
Imposta un filtro customizzato che contiene l’URL della root del tuo dominio, poi carica la lista di backlink in Screaming Frog e lancia lo spider in modalità “List Mode”. Quando lo spider ha finito di fare crawling, seleziona la tab Custom per vedere tutte le pagine che stanno ancora linkando verso il tuo sito.
11.6 Come trovare i backlink dofollow tra quelli segnalati da Google Search Console
Scarica l’elenco dei backlink da Search Console, avvia Screaming Frog e dal menu “Mode” attiva la visione “List”. Clicca il bottone “Select File”, importa la lista di backlink e avvia lo spider.
A processo terminato clicca su “Advanced Export” e seleziona “All Out Links”. Apri il file .CSV con Excel, con il comando dati/text-to-columns ordina i dati in colonne e poi applica i filtri. Dalla colonna “Destination” filtra soltanto gli URL del tuo dominio e nella colonna “Follow” puoi vedere quali backlink sono dofollow e quali no.
Estrazioni customizzate
La nuova funzione “custom extraction” permette di collezionare qualsiasi informazione estratta dall’HTMl di un URL. Se sei familiare a strumenti di scraping che importano l’XML e Xpath (SeoTools per Excel, Scraper per Chrome, …) allora sai di cosa sto parlando. Questa funzione la trovi sotto “Configuration > Custom”.
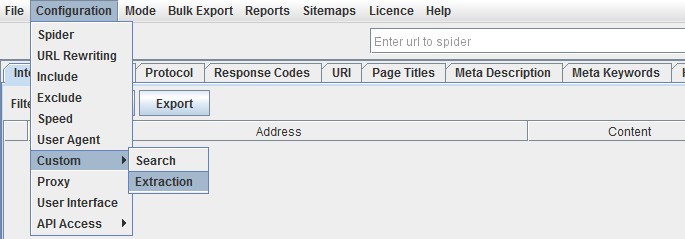
“Search” è la classica ricerca nel codice HTML.
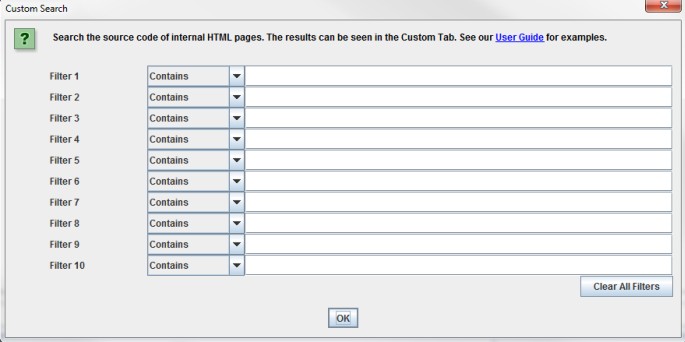
“Extraction” è simile alla funzione Search, hai a disposizione 10 campi per estrarre qualsiasi cosa dall’HTML della pagina usando sia Xpath, CSS path oppure ReegEx.
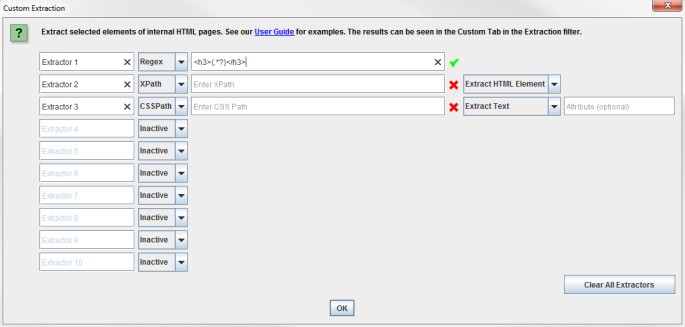
Quando usi XPath o CSS Path per fare scraping dell’HTML, puoi decidere cosa estrarre:
- Estrarre elementi HTML: estrae l’elemento completo e l’HTML contenuto in esso.
- Estrarre Inner HTML: estrae il contenuto dell’HTML dell’elemento selezionato. Se l’elemento selezionato contiene un altro elemento, questo verrà incluso.
- Estrarre semplice testo: estrae il testo contenuto nell’elemento ed il testo di sotto elementi (essenzialmente viene estratto tutto l’HTML).
Come verifica della sintassi di Xpath, CSS path e RegEx inserita nei filtri viene attivata una virgoletta verde se è corretta, altrimenti una x rossa se la sintassi è errata.
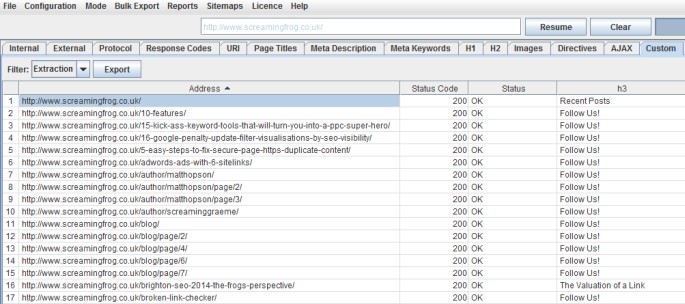
Autori & Commenti
Ora Screaming Frog ci può dire quale sia l’autore di ogni post e quanti commenti ogni post abbia ricevuto, bello no? Tutto quello che ti serve fare è aprire un post su Chrome, cliccare col tasto destro e selezionare “Ispeziona elemento” sul dato che vuoi collezionare e copiare l’ Xpath o CSS path che ti interessa.
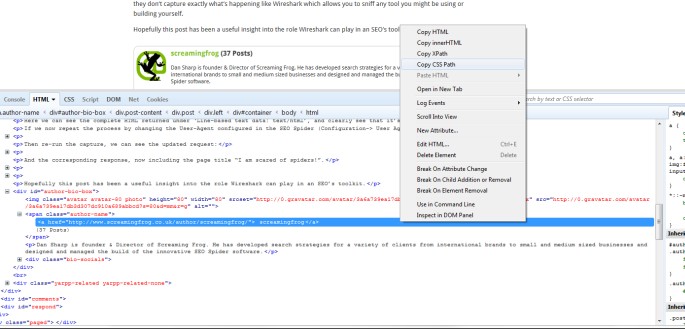
Puoi anche rinominare gli “estrattori” assegnando un nome alle colonne. In questo caso ho usato “CSS Path” e “XPath”.

Il nome autore e la somma dei commenti vengono mostrati sotto il filtro “extraction” dentro la tab “Custom”.
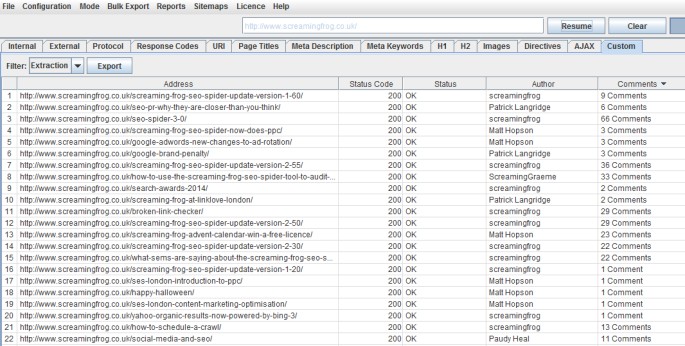
Google Analytics ID
Con questo filtro customizzato puoi estrarre ilf tag ID del tracking di Google Analytics da tutte le pagine:
["'](UA-.*?)["']

I dati estratti appariranno in questo modo:
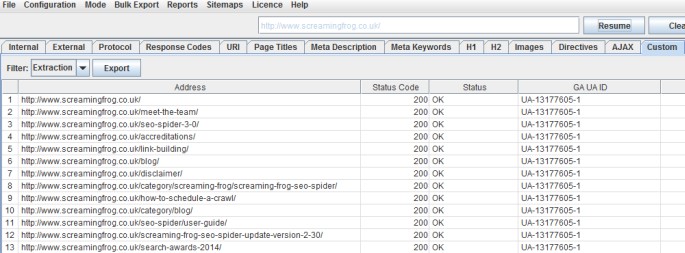
Headings H1-H6
Screaming Frog era in grado di collezionare i tag H1 e H2. Ora con l’aggiornamento alla versione 4.0 puoi analizzare anche i tag H3/H4/H5 e H6. Ora con una semplice query RegEx puoi filtrare quello che ti serve:
<h3>(.*?)</h3>
La stringa Xpath sarebbe:
//h3I primi H3 estratti sono mostrati come segue:
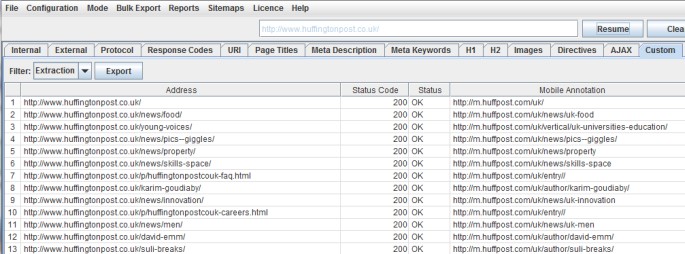
Annotazioni Mobile
Per estrarre le annotazioni mobile da un sito web, devi usare l’Xpath come indicato di seguito:
//link[contains(@media, '640') and @href]/@href
I risultati per il sito Huffington Post sono i seguenti:
Tag Multilingua Hreflang
Con la nuova versione 4.0 di Screaming Frog possiamo estrarre tutti i tag Hreflang.
(//*[@hreflang])[1]
(//*[@hreflang])[2]
---Alternativa:
//link[@rel="alternate"][1]/@hreflang
//link[@rel="alternate"][2]/@hreflang
//link[@rel="alternate"][3]/@hreflang
//link[@rel="alternate"][4]/@hreflang
//link[@rel="alternate"][...]/@hreflangAlternativa con definizione del country code:
//link[@hreflang="en-US"]/@hreflang
//link[@hreflang="en-AU"]/@hreflang
La stringa che segue raccoglie tutto l’elemento HTML, con il link al valore Hreflang.
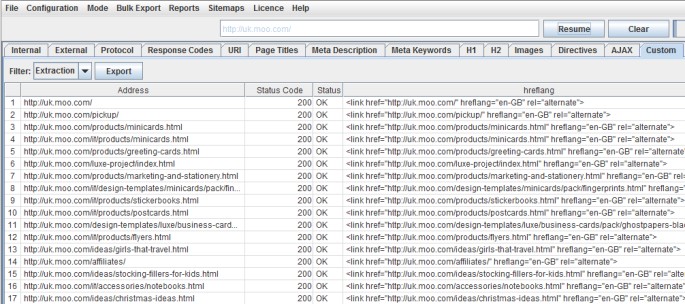
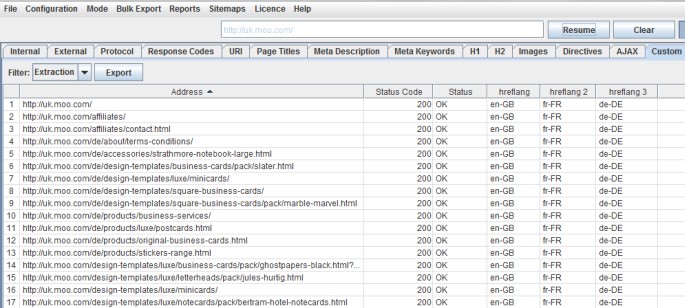
Se invece vuoi solo recuperare il valore del tag Hreflang, puoi specificare l’attributo Xpath @hreflang:

Questo filtro colleziona soltanto i valori dei linguaggi inseriti nel tag:
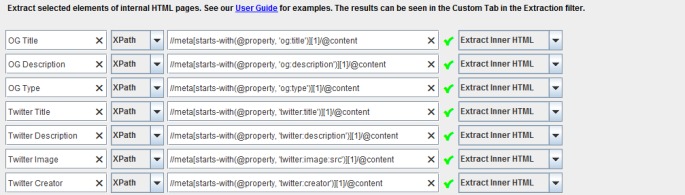
Social Meta Tags: Open Graph e Twitter Card
Per estrarre i tag dedicati ai social media, come Open Grap e Twitter card, puoi usare i seguenti filtri:
//meta[starts-with(@property, 'og:title')][1]/@content
//meta[starts-with(@property, 'og:description')][1]/@content
//meta[starts-with(@property, 'og:type')][1]/@content
...
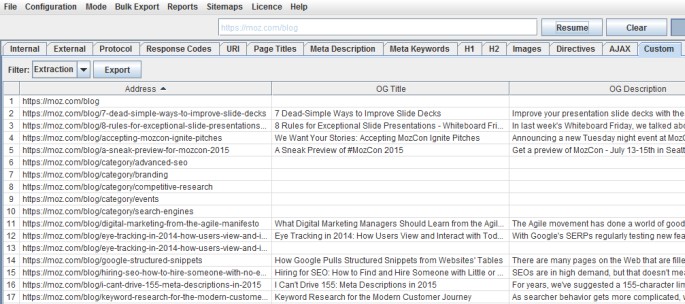
Ad esempio, sul sito di Moz questi sono i risultati di scansione dei tag social:
Schema.org
Per fare scraping del markup di Schema.org dentro l’HTML usa questi filtri:
(//*[@itemtype])[1]/@itemtype
(//*[@itemtype])[2]/@itemtype
...
Così è come appaiono i dati raccolti:
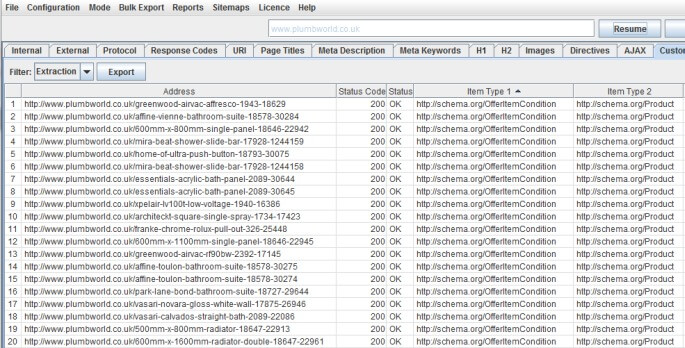
is –
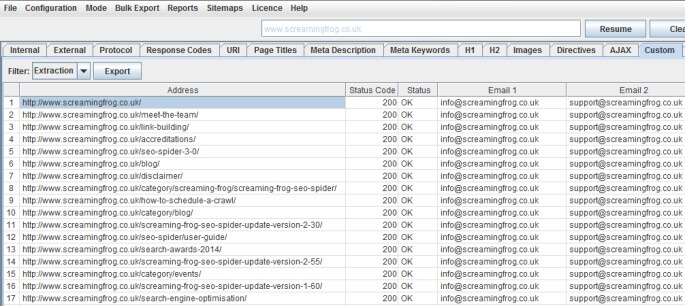
Indirizzi Email
Ebbene si, Screaming Frog può anche fare scraping di tutti gli indirizzi email che trova scansionando le pagine del sito. Per impostare il filtro basta usare questo Xpath:
//a[starts-with(@href, 'mailto')][1]
//a[starts-with(@href, 'mailto')][2]
...
I risultati appaiono come segue:
Prerender
Per estrarre l’URL indicato nel link Prerender imposta la seguente custom extraction con XPath e Extract Text:
//link[@rel="prerender"][1]/@href
//link[@rel="prerender"][2]/@href
//link[@rel="prerender"][3]/@href
//link[@rel="prerender"][...]/@hrefCollegare Google Analytics
Dalla versione 4.0 di Screaming Frog è possibile scaricare via API i dati di navigazione per ogni singolo URL. Finalmente diciamo basta a faticosi merging con vlookup del database Screaming Frog con il database di Google Analytics :D
Come collegare Google Analytics
Per collegare Screaming Frog a Google Analytics devi cliccare nel menu “Configuration” e poi su “API access”. Nella nuova schermata clicca su “connect account” per essere redirezionato sulla pagina di conferma di Google per accettare la condivisione dei dati con l’applicazione.
Ora è disponibile il pannello delle opzioni di Google Analytics dove puoi impostare tra le altre cose, il range di date, le metriche e le dimensioni da mostrare.
A questo punto basta scegliere l’account, la proprietà e la visuale del profilo Analytics del sito che stiamo scansionando ed il gioco è fatto. I dati sono mostrati nella tab dedicata “Analytics”.
Spero che questa guida ti abbia aiutato a comprendere meglio le potenzialità di Screaming Frog, io non potrei farne a meno! Hai suggerimenti che vorresti aggiungere? Lascia un commento e verrà inserito nella guida e se le info ti sono servite condividi questa pagina sui social!
Richiedi ora un SEO Audit per il tuo sito, compila il form di contatto e riceverai un preventivo rapido e specifico per il tuo business!
Articoli correlati
Autore

Mi chiamo Giovanni Sacheli e dal 2009 aiuto le aziende a farsi trovare online. Sono specializzato in SEO tecnica e PPC, competenze che applico quotidianamente nella mia agenzia, Searcus Swiss Sagl. Mi piace sviluppare strumenti a supporto del mio lavoro, ho creato SEOdata.app e cluster.army e co-scritto il libro SEO Audit Avanzato. Curo maniacalmente questo blog per colleghi e appassionati, dove mi "appunto" quello che imparo. Sono un NERD anni '80, motociclista e orgoglioso papà di due bambini.
Link:
Giovanni Sacheli
SEO Audit Avanzato
Searcus Swiss Sagl
SEOdata.app
cluster.army
Commenti |56
Lascia un commentoBuon giorno, complimenti e grazie per l’articolo. Volevo chiederti però cosa intendi tu per tempi lunghi di caricamento pagina? mi spigo meglio scusa, quale il tempo massimo di caricamento pagina che un sito non dovrebbe mai superare secondo la tua esperienza. Es: 0,80 0,90 e i siti che superano tali limiti subiscono penalizzazioni? Grazie di cuore
Ciao Mario,
un page load time buono è sotto i 3-4 secondi, se invece ti riferisci ai tempi del crawler (indicati anche in GWMT – statistiche di scansione) allora è meglio stare sotto il secondo. Però preferisco rispondere linkandoti alcuni video ufficiali di Matt Cutts che parlano dell’argomento:
http://youtu.be/B3zmP0W26M0
http://youtu.be/muSIzHurn4U
http://youtu.be/oG7y87SVG6A
http://youtu.be/nndi1mxl4vE
http://youtu.be/sIyM7NFiDWM
http://youtu.be/-I4rWnQxxkM
http://youtu.be/a-9pCfyYPdQ
Grazie Giovanni
Ciao ragazzi avrei un problema, dal web master tool risulta che un mio sito riceve link da un altro mio sito, e io non voglio (forse ci sono capitati per errore). Come faccio a sapere quali sono le pagine dove stanno i link, se faccio un analisi con Screaming Frog mi mostra dove stanno i link in modo che posso eliminarli?
Ciao Virgilio, esegui la scansione con SF e quando termina passa nella tab superiore “external”. Individua il link verso il tuo sito (con il filtro è veloce) e cliccalo, nella tab inferiore trovi “Inlinks”. Dentro Inlinks trovi tutte le pagine che contengono quel link.
:D buona giornata!
Grazie Giovanni
Buon giorno Giovanni, la scansione del mio sito si blocca al 80% che faccio? da premettere ho già preso tutte le precauzioni, ho deselezionato Images, CSS, JavaScript, SWF e ho aumentato la memoria del mio computer un i5 con 10 GB di ram, che altro posso fare? tu nel art sopra consigli di dividere il sito, ma cosi facendo non rischio di perdere eventuali duplicazioni di title?. Grazie di tutto
Ciao Virgilio, alcune domande:
1) a quanti URL si ferma Screaming Frog? Con 10 GB di RAM allocati dovresti arrivare tranquillamente a scansionare 20-25.000 URL (con immagini, CSS, JS & Co.) oppure circa 200.000 di soli URL HTML
2) nella guida spiego come verificare che la memoria sia effettivamente allocata a SF, hai verificato?
3) SF è un software in Java che NON archivia i dati in un database ma in memoria, questo lo rende poco efficiente RAM-parlando. Se hai un sito con centinaia di migliaia o peggio ancora milioni di URL è impensabile usare questo software su PC con dotazione standard. Per siti molto estesi ci sono crawler online, ti elenco i migliori:
– http://80legs.com/
– https://www.deepcrawl.com/
Dividere il sito è una soluzione, poi comunque dovrai esportare i dati e riunirli in Excel per evitare, come dici tu, di perdere dei dati come titoli duplicati. Se dividi il sito in sezioni l’analisi con Excel diventa obbligatoria perchè non potrai più basarti solo sui dati mostrati da SF essendo dati parziali.
Giovanni sei un pozzo di scienza, grazie mille
eheheheh grazie :D ma non mi hai detto se hai risolto e come!
Voglio provare a dividere il sito, i servizi che mi hai consigliato sono troppo cari. Ti terrò aggiornato. A dimenticavo la scansione è arrivata a 676.121 url
676.121 URL? Mezzo milione di URL non sono pochi con 10 GB RAM :D
Quindi l’unica soluzione senza spendere altri soldi è excel giusto?
eh si, scansioni settoriali e merging dei database in Excel :)
Si è un sito grosso ma ha problemi di indicizzazione, pensa che dal wmt risultano indicizzate solo 1.555 URL in 6 mesi circa il dominio è anziano 5 anni. Devo trovare il problema
Buon giorno, ottimo art. bravo, bravo. Potrei avere una delucidazione? io ci provo. Scansionando il mio sito mi ritrovo con una miriade di 302 found tutti gravatar.com ma è normale? Giovanni SOS
Ciao Michela, gravatar è il servizio che associa le foto alle email nei commenti. È un servizio esterno al tuo blog quindi non mi preoccuperei.
Grazie giovanni, quindi lascio tutto cosi, anche se sono tanti 302?
Ciao Michela, se sai come entrare nel template e correggere i link verso Gravatar puoi anche fixare. Clicca il link attuale sugli avatar, controlli cosa cambia nel path dell’URL dal vecchio al nuovo e dovresti risolvere :D
Ciao Giovanni, che guida!!!!!!! Sei un grande! Provo a chiederlo anche a te: provando a scansionare il mio sito con il programma, mi restituisce sempre questo errore:
Status code 406 Status Not Acceptable
Ma come cavolo è possibile? Ho anche contattato l’assistenza del mio host ma non hanno trovato una soluzione.,,
Grazie!!!!
Grazie Jedi :D
Dato che Screaming Frog non definisce niente nell’intestazione HTTP come “accept headers”, l’errore 406 probabilmente è causato da errata configurazione del webserver.
Tecnicamente l’errore dice: la risorsa richiesta è solo in grado di generare contenuti non accettabili secondo la header Accept inviato nella richiesta.
Ma anche via browser ricevi 406? Prova a disabilitare qualche plugin a turno.
Salve Giovanni,
per prima cosa mi sento in dovere di ringraziarti per quanto condiviso!
Sono alle prime armi tuttavia so riconoscere la qualità di un contenuto e sia questo che le tue altre guide sono fantastiche!!
Passo ora con la domanda!
Quando provo ad eseguire il passaggio 1.2 “Avviare il crawling dell’intero sito web” nel momento in cui vado su Configurations/Spider/Basic non mi è possibile abilitare nessuna voce compreso “Crawl All Subdomains”.
Mi compare il messaggio “These options are only available to licenced users”.
Cosa dovrei fare per abilitarlo?
E nel caso si facesse crawling di un competitor come è possibile (se possibile) abilitare tali voci?
Ringraziandoti ancora ti saluto
Ciao Giuseppe, grazie per il commento!
vuol dire che la funzione che cerchi è disponibile soltanto nella versione a pagamento di Screaming Frog.
Come sai quel programma, nella versione gratuita, è limitato. Per fruire di tutte le sue funzioni ti serve la licenza.
Spero di averti aiutato, buona serata!
Ti ringrazio Giovanni, pensavo che la versione free permettesse di fare qualcosina in più.
Un saluto e grazie per il materiale messo a disposizione!!
Salve Giovanni e complimenti per l’ottima guida, avrei una domanda: ho modificato il file hosts della workstation per visualizzare un sito web da analizzare che sta subendo un restyling sia grafico che di architettura informativa. Se lancio la scansione, Screaming Frog cosa mi analizza? il dominio vecchia versione o interpreta la modifica la mio file hosts e mi scansiona la nuova versione? grazie
Ciao Luketto, grazie per il commento.
In teoria se modifichi correttamente il file host, Screaming Frog dovrebbe navigare sul sito di test – ovvero sull’IP segnato nel file HOST.
Perfetto, grazie, tutto chiaro!
Grazie Giovanni per l’ottima guida.
Ho un problema: ho avviato screaming frog per analizzare un sito su protocollo https, appena avvio mi scarica solo l’home page con risposta: connessione rifiutata. Ho provato anche a cambiare vari user agent, ma con lo stesso risultato, cosa può essere secondo te? c’è qualche impostazione da fare per https?
Con xenu riesco a spiderizzarlo ….
Grazie dell’aiuto
Ciao Marco grazie per il commento.
Screaming Frog può essere bloccato via robots.txt o da redirezioni sull’user-agent a livello di http-header.
Il robots.txt blocca SF?
Se hai già provato a lanciare la scansione con diversi user-agent senza successo, allora il problema potrebbe essere lato server. Ad esempio il server potrebbe richiedere i cookies per fornire le pagine, in questo caso ti basta spuntare l’opzione “accetta cookies”. Un altro esempio: i link del sito web sono in JavaScript e Screaming Frog non vedendoli si ferma alla homepage.
L’errore che ha scritto “connessione rifiutata” è della serie 5xx. La serie di status code 5xx è relativa ad errori sul web server, hai controllato il file .htaccess?
Ottima guida davvero ben fatta. Ero indeciso su Screaming Frog ma questa guida me ne ha fatto apprezzare le potenzialità. Grazie.
Guida eccellente, non conoscevo il vostro sito ma diventerò una frequetatrice abituale
Grazie Barbara!
Buongiorno,
se volessi utilizzare Screaming Frog per i miei clienti avrei bisogno di più licenze o posso configurare più siti web in un’unica licenza?
Buonasera Mario, la licenza di Screaming Frog è legata al PC e non all’uso che se ne fa. Con una licenza attiva può scansionare tutti i siti che vuole senza limiti di URL. A presto e buon lavoro!
Ciao, non capisco perché Screamin Frog non prende le lettere accentate. In effetti su Content non compare la codifica dei caratteri.
Ciao Elio, la pagina html che stai scansionando usa la meta tag <meta charset="utf-8"> ?
Salve, eccellente articolo. Mi chiedevo come fare a scansionare un url di questo tipo “pagina.php?AB=212121-A” in massa. Mi spiego: vorrei fare in modo che con una semplice istruzione screamingfrog scansioni tutte le chiamate possibili. “pagina.php?AB=(qualsiasi numero e lettera)”. E’ possibile?
Buonasera Maria grazie per la domanda.
Non sono sicuro di aver ben capito la domanda ma la prima cosa che le posso dire è che Screaming frog non indovina gli URL da scansionare. Per sua natura Screaming Frog (che è un web crawler) segue i link che incontra scansionando le pagine. Che siano URL SEO friendly o parametrizzati non cambia: se esiste il link in pagina il crawler lo seguirà.
In alternativa si può usare SF in modalità lista. Il tool scansionerà tutti e soltanto gli URL che gli vengono forniti.
Se quello che le serve è invece testare URL seguiti da un range di parametri, potrebbe generare la lista di URL con Excel e poi passarla a SF.
Non mi vengono in mente altri metodi :) Spero di averti aiutata.
A presto!
Ciao Giovanni, come sempre un contributo di altissima qualità.
Volevo chiederti se, in termini di crawling, ci fosse differenza tra l’usare GoogleBot Regular o uno dei due GoogleBot Mobile (ed immagino di sì, perché in base a quello impostato varierà la versione del sito crawlata); e soprattutto se fosse corretto, in ottica mobile-first, scansionare i siti con il bot per mobile.
Grazie!! :)
Ciao Alessandro, grazie del commento.
Non ci sono differenze eseguendo una scansione con impostazione di user-agent desktop o mobile, se il web server non è impostato per trattarli in modo differente, come ad esempio sarebbe dovuto essere con i siti mobile m.
In screaming frog per emulare un dispositivo mobile devi cambiare l’opzione configuration – spider – rendering – da “text only” a JavaScript. A questo punto puoi settare la risoluzione dello schermo da emulare.
In risposta alla tua seconda domanda posso dirti che ha assolutamente senso oggi scansionare un sito in versione mobile. Uno dei controlli che faccio negli audit è confrontare i dati di scansione full text con quelli JavaScript – googlebot mobile. Le differenze sono tutte da verificare per capire se sono accettabili o meno.
A presto, buona serata!
Complimenti, davvero una grande guida!
Grazie Gianmarco :)
Bellissimo articolo. Volevo fare una domanda: nel capitolo “10.4 Fare scraping della pagina dei risultati di Google” viene citata la possibilità di ottenere termini correlati. In base alla tua esperienza, su Screaming Frog, è possibile ottenere co-occorrenze ed entità facendo scraping? Se si, come lo faresti?
Attualmente per questo tipo di analisi utilizzavo SEO Hero ma parrebbe non funzionare più. In pratica analizzava i primi cento risultati e catalogava le corrispondenze in termini di keyword tra un sito e l’altro. Altrimenti utilizzavo “SEO Content Template” di Semrush, ma non ti da la possibilità di comprenderne il dato, anche se le parole combaciavano con il servizio di Seo Hero.
Grazie mille!
Ciao Valerio grazie per la domanda.
Ottenere co occorrenze ed entità dei siti in SERP con SF… La vedo abbastanza complessa come attività.
Per trovare le entità correlate uso un piccolo tool che ho scritto che si basa sulle API dell’Knowledge Graph e le API di Wikipedia – http://apps.evemilano.com/entities/
Altrimenti per trovare la distribuzione delle parole ed i termini in comune uso http://urlsmatch.eu/
Quelle che proponi sono analisi abbastanza difficili da automatizzare dato che comportano lo scraping dei risultati di Google, attività che viola le linee guida di utilizzo del servizio.
Grazie mille per la risposta! utilizzerò questi servizi per questo tipo di ricerca.
Sono appena agli inizi e sto studiando questo strumento eccezionale. Ho una domanda se mi vorrete rispondere.
Perché una pagina creata nel mio sito, analizzata con Screaming Frog mi da connection refused?
Eppure la pagina esiste e il browser la vede. Non ho firewall che bloccano Screaming Frog.
Cosa potrebbe essere?
Grazie
Ciao Mauro grazie per la domanda.
“Connection refused” è uno Status Code che invia il server quando non vuole aprire una connessione con l’user-agent che richiede la risorsa.
Hai provato a cambiare user-agent in Screaming Frog?
Il server potrebbe avere dei filtri o configurazioni che bloccano alcuni user-agent.
Un’altra causa abbastanza frequente su server condivisi è il blocco IP se si eccede un certo numero di richieste al secondo. In questo caso dovresti provare a rallentare Screaming Frog con il menu “Speed”, in modo che il crawler sia mano invasivo.
Ciao Giovanni , dovendo fare un audit di un sito di circa 50 mila pagine, ho 6 gb di ram; non mi è chiaro come aumentare l’allocazione della memoria.
Se vado sul sito trovo un video: https://www.youtube.com/watch?time_continue=18&v=Q-Im86a5Tis&feature=emb_logo
Se non sbaglio loro consigliano di usare come modalità il “database Storage” piuttosto che il “Memory Storage” , Corretto?
Praticamente mi salva su un file interno che posso aprire al volo le pagine indicizzate AL 100?
Grazie
Ciao, esatto. La modalità con database è specifica per PC che hanno poca RAM dato che scrive tutto direttamente in un file e non in memoria. Con questa impostazione dovresti riuscire a scansionare anche siti grandi che in alternativa non riusciresti a scansionare con soli 6 GB.
Grazie Giovanni
Ciao Giovanni.
Se dovessi studiare e capire l’alberatura di un sito web di un competitor, in modo da avere una sorta di mappa visiva, con screaming frog è possibile? Nel caso di risposta negativa: che tool si potrebbe usare ?
Grazie mille
Ciao Marco, grazie per la domanda. L’ultima versione di Screaming Frog mostra una tabella sulla struttura del sito, è molto utile e chiara. Prima usavo Excel ed estraevo dagli URL le cartelle.
Ciao Giovanni,
nessuna domanda. Solo tanti complimenti e ringraziamenti. Grande guida che ho salvato tra i link preferiti e che almeno una volta al mese consulto per non perdermi tra la varie funzionalità di Screaming Frog. Grazie ancora!
Grazie Alessandro, apprezzo molto il tuo commento.
A presto e buona giornata.
Ciao Giovanni,
Sto utilizzando la versione con licenza di Screaming Frog. Ho un problema e tu forse puoi aiutarmi, dato che lo conosci così bene.
Ho due siti web diversi, dove utilizzo l’estensione WEBP per le immagini.
Stranamente, se avvio la scansione sulla URL .webp di un sito web Screaming Frog me la segnala correttamente come “immagine”, mentre se faccio lo stesso sull’altro sito web non me la da come immagine ma la inserisce in “Altro” e in “tipo di contenuto” è vuoto (non esce image/webp).
Da cosa potrebbe dipendere?
Grazie mille!
Ciao Gennaro,
Il problema potrebbe dipendere dalle intestazioni HTTP inviate dai due siti web. Quando Screaming Frog analizza una pagina web, cerca di rilevare il tipo di contenuto utilizzando l’intestazione HTTP “Content-Type” restituita dal server per il file richiesto.
Nel caso delle immagini WebP, l’intestazione “Content-Type” dovrebbe essere impostata su “image/webp” per indicare che si tratta di un’immagine nel formato WebP. Tuttavia, se l’intestazione “Content-Type” manca o non è correttamente impostata per il file .webp nel secondo sito web, Screaming Frog potrebbe non essere in grado di riconoscerlo come un’immagine.
Potresti verificare le intestazioni HTTP restituite dal server per il file .webp nel secondo sito web utilizzando strumenti come DevTools del browser o un’estensione per la visualizzazione delle intestazioni HTTP. Assicurati che l’intestazione “Content-Type” sia impostata correttamente su “image/webp” per il file .webp.
Se l’intestazione “Content-Type” è correttamente impostata e il problema persiste, potrebbe essere utile contattare il supporto di Screaming Frog per ulteriori informazioni o assistenza specifica al software.
Spero che questa spiegazione ti sia stata utile. Se hai ulteriori domande, non esitare a chiedere!