Quando si parla di TF-IDF si parla di comprensione del linguaggio da parte delle macchine. La sigla TF-IDF significa “Term Frequency-Inverse Document Frequency” e rappresenta una formula matematica per calcolare l’importanza di una parola inserita in un documento in rapporto ad altri documenti simili.
Questo valore era utilizzato come fattore di ponderazione in information retrieval (recupero delle informazioni) e data mining. Il valore TF-IDF aumenta proporzionalmente al numero di volte che una parola compare nel documento, ma viene compensata dalla frequenza della stessa parola nel corpo di altri documenti simili, questo aiuta a controllare se alcuni termini sono generalmente più comuni di altri.
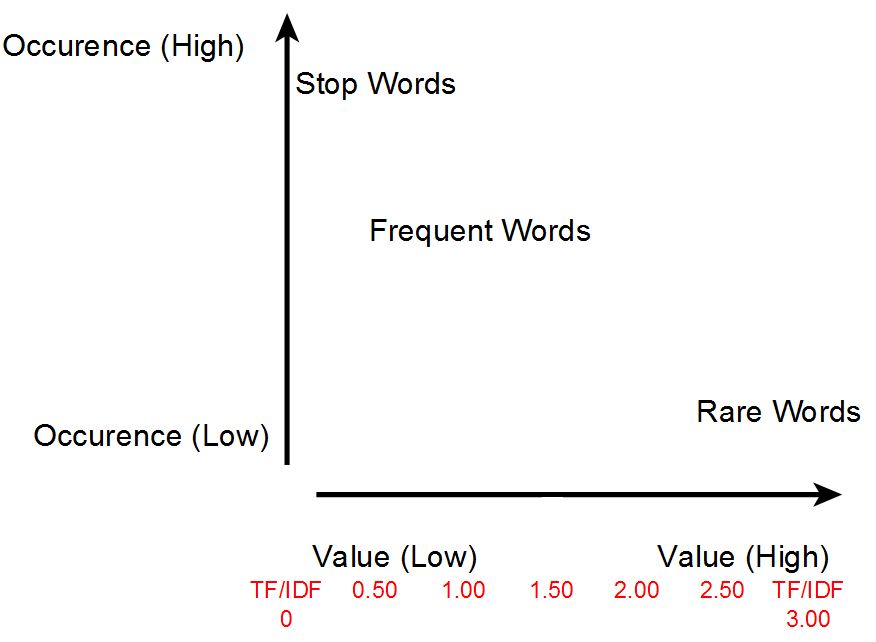
Un errore comune è quello di confonde TF-IDF con la Keyword Density, la KD non mette in rapporto il documento di partenza con altri documenti simili e non analizza la rarità della parola chiave.
I Motori di Ricerca usano funzioni molto avanzate per quantificare il livello di pertinenza di un documento rispetto alla query e non si basano certo sulla funzione basilare TF-IDF. La funzione TF-IDF (e sue funzioni derivate) ad esempio può essere usata per identificare e filtrare le stop-words e creare un documento di sintesi con le sole parole rilevanti e significative per quel topic.
La formula TF-IDF
- TFIDF(t,d,D) = tf(t,d) * idf(t,D).
- TF(t) = (Numero di volte che il termine t appare in un documento) / (Numero totale di termini nel documento).
- IDF(t) = log_e(Numero totale di documenti / Numero di documenti che contengono il termine t).
Un valore alto della funzione può essere raggiunto con un’alta frequenza del termine (in un dato documento) ed una bassa frequenza in tutti gli altri documenti simili. Dato che il rapporto dentro alla funzione IDF è sempre maggiore o uguale a 1, il valore IDF (e TF-IDF) è maggiore oppure uguale a zero. Più volte il termine appare in altri documenti simili e più il rapporto tenderà a zero.
TF-IDF e la SEO
I ricercatori di Google hanno recentemente descritto TF-IDF come una funziona a lungo utilizzata per indicizzare le pagine web e diverse varianti della funzione originale si possono ritrovare in alcuni brevetti di Google.
One way to approach the problem is to look for words that appear more often than their ordinary rates. For example, if you see the word “coach” 5 times in a 581 word article, and compare that to the usual frequency of “coach” — more like 5 in 330,000 words — you have reason to suspect the article has something to do with coaching. The term “basketball” is even more extreme, appearing 150,000 times more often than usual. This is the idea of the famous TFIDF, long used to index web pages.
TF-IDF quindi non misura quanto spesso un termine appare in un singolo documento, ma aiuta a capire l’importanza di un termine calcolando quanto spesso appare in confronto ad altri documenti simili, ovvero quanto è rara e specifica una parola chiave.
Se proviamo a confrontare i termini “calcio” e “calciomercato” su Google Ngram possiamo notare come il termine “calciomercato” sia un termine più raro e meno diffuso di “calcio”. Partendo da questa considerazione possiamo concludere che “calciomercato” è un termine importante da utilizzare in una pagina che contiene il termine “calcio”.
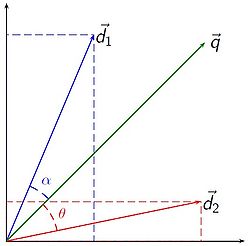
Il rapporto TF-IDF è soltanto l’inizio, è una funzione studiata fin dagli anni ’70 e oggi non è utilizzata dai motori di ricerca. L’indicizzazione si è evoluta molto negli ultimi anni e molti altri fattori sono entrati in gioco come ad esempio il calcolo della distanza tra coppie di termini in una pagina per capire la loro correlazione attraverso il modello vettoriale ed il calcolo dell’angolo formato tra due termini. Con l’implementazione del Knowledge Graph Google ha cominciato a ragionare non più a livello di singole parole chiave ma in termini di entità e relazioni, si parla in questo caso di ricerca semantica. Lo stesso concetto lo possiamo ritrovare nella struttura di Freebase.
Infografica
Un esempio pratico
Consideriamo i seguenti dati in tabella che rappresentano la frequenza di quattro parole all’interno di tre documenti in panel totale di 1.000 documenti. Si può verificare che la frequenza inversa dei documenti per le stop-words comuni a tutti i documenti è prossima allo zero. Il termine “metodo” invece, che appare abbastanza di frequente nei brevetti, ottiene un valore IDF abbastanza basso. Un termine molto specifico come “bioreattore”, che appare solo in 25 su 1.000 documenti, ottiene in proporzione un IDF alto.

Da questa tabella possiamo capire come la frequenza inversa dei documenti influisce sul valore finale TF-IDF. Anche se il termine “metodo” viene ripetuto meno di frequente rispetto a “acqua” nel documento doc2, il valore TF-IDF del termine “acqua” è circa 6.6 volte più alto.
Conclusioni
Come per la LSI, quando si misura la correlazione tra TF-IDF ed il ranking in SERP, non si è notata una correlazione significativa. In altre parole, generare un alto punteggio TF-IDF non è sufficiente a posizionare in alto la nostra pagina nei motori di ricerca. La cosa importante a mio giudizio è capire come è nata la scienza del recupero delle informazioni sul web, solo in questo modo si potrà comprendere il presente e le future evoluzioni degli algoritmi di ricerca.
Link e approfondimenti
- Per calcolare il fattore TF-IDF esistono diversi software, il più famoso gira su Pyton e si chiama Textblob.
- http://nlp.stanford.edu/IR-book/html/htmledition/tf-idf-weighting-1.html
- http://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.TfidfTransformer.html
- http://pyevolve.sourceforge.net/wordpress/?p=1589 e http://pyevolve.sourceforge.net/wordpress/?p=1747
- http://stevenloria.com/finding-important-words-in-a-document-using-tf-idf/
- http://textminingonline.com/getting-started-with-textblob
- urlsmatch, strumento per l’analisi delle parole chiave e calcolo TF*IDF
Articoli correlati
Autore

Mi chiamo Giovanni Sacheli e dal 2009 aiuto le aziende a farsi trovare online. Sono specializzato in SEO tecnica e PPC, competenze che applico quotidianamente nella mia agenzia, Searcus Swiss Sagl. Mi piace sviluppare strumenti a supporto del mio lavoro, ho creato SEOdata.app e cluster.army e co-scritto il libro SEO Audit Avanzato. Curo maniacalmente questo blog per colleghi e appassionati, dove mi "appunto" quello che imparo. Sono un NERD anni '80, motociclista e orgoglioso papà di due bambini.
Link:
Giovanni Sacheli
SEO Audit Avanzato
Searcus Swiss Sagl
SEOdata.app
cluster.army